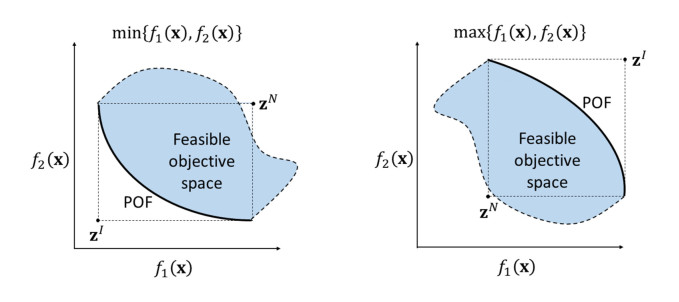
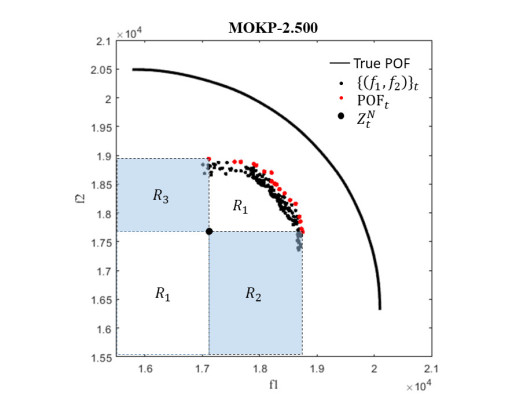
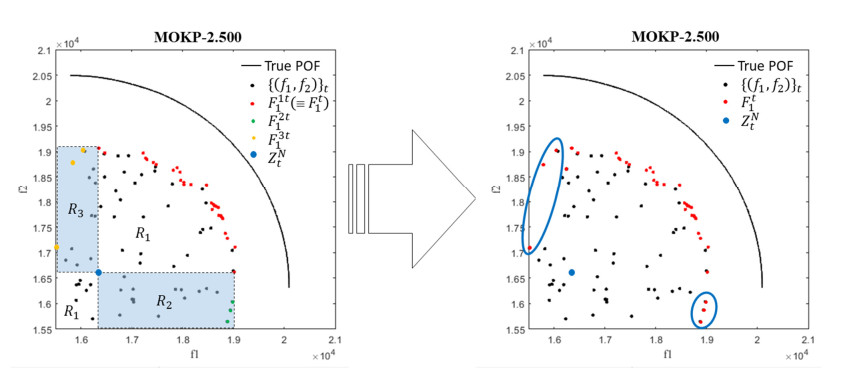
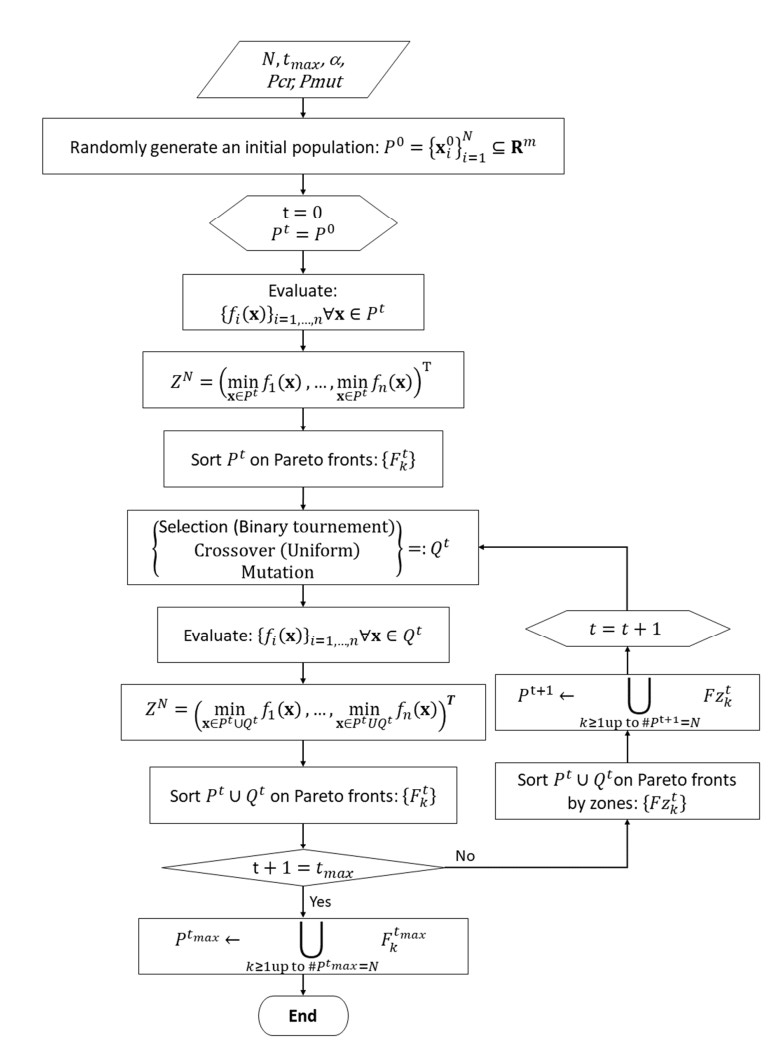
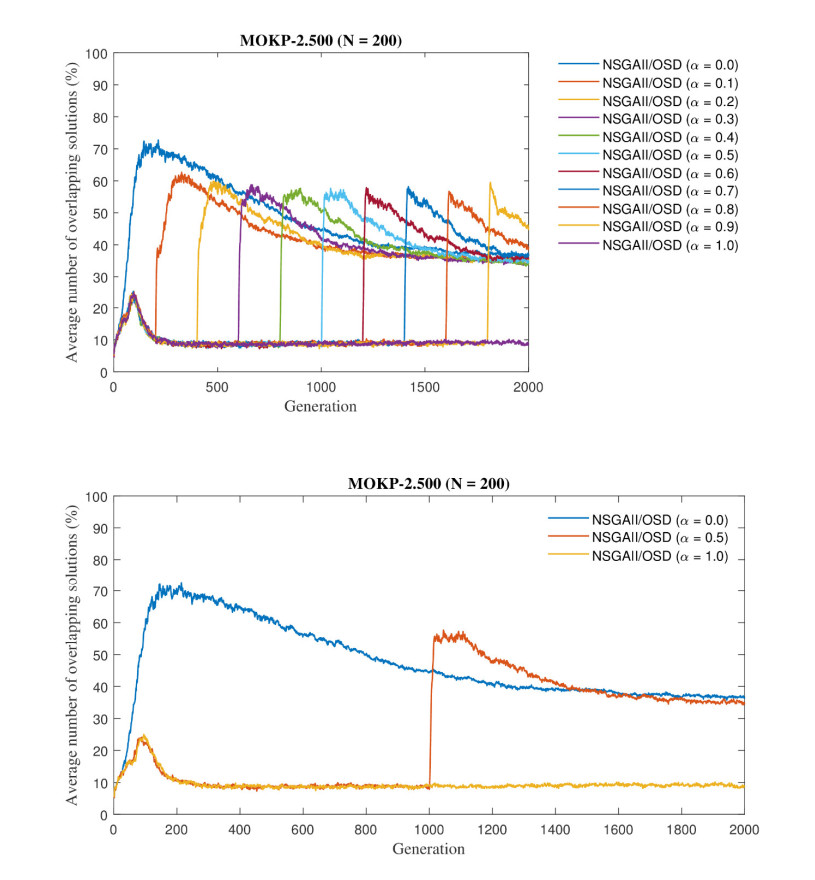
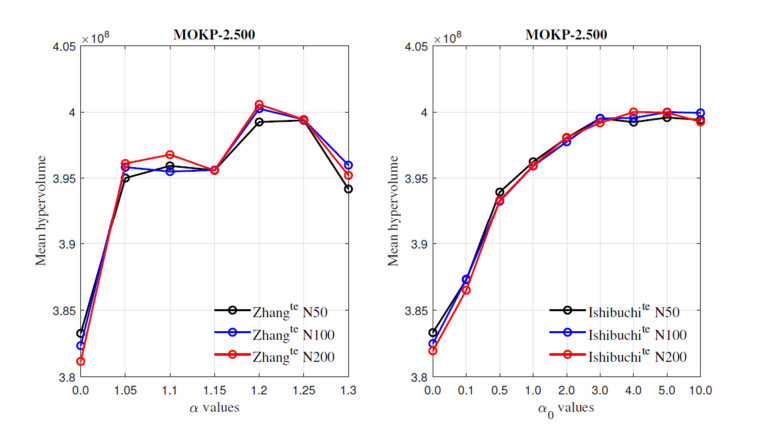
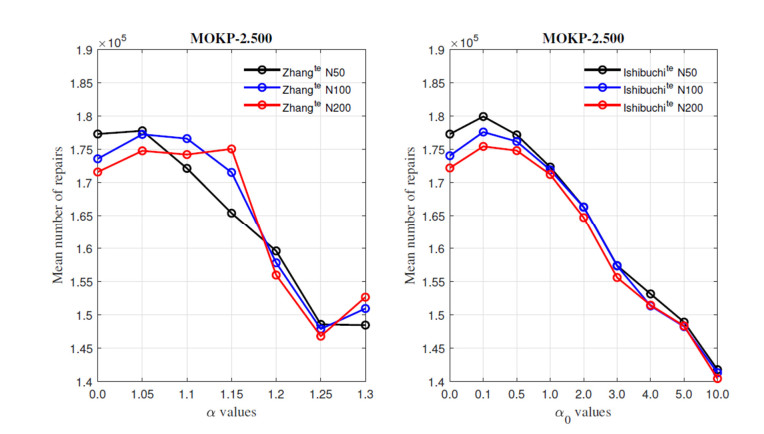
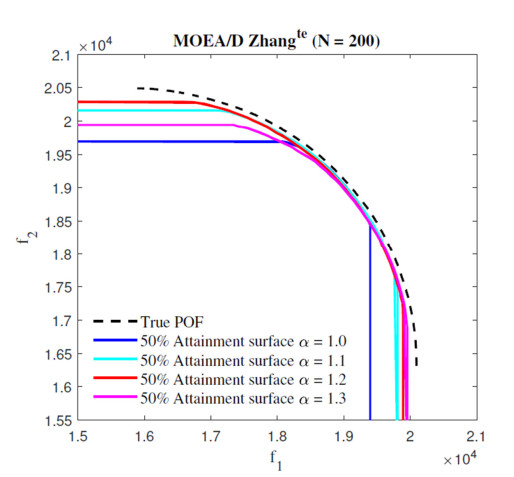
Overlapping solutions occur when more than one solution in the space of decisions maps to the same solution in the space of objectives. This situation threatens the exploration capacity of Multi-Objective Evolutionary Algorithms (MOEAs), preventing them from having a good diversity in their population. The influence of overlapping solutions is intensified on multi-objective combinatorial problems with a low number of objectives. This paper presents a hybrid MOEA for handling overlapping solutions that combines the classic NSGA-II with a strategy based on Objective Space Division (OSD). Basically, in each generation of the algorithm, the objective space is divided into several regions using the nadir solution calculated from the current generation solutions. Furthermore, the solutions in each region are classified into non-dominated fronts using different optimization strategies in each of them. This significantly enhances the achieved diversity of the approximate front of non-dominated solutions. The proposed algorithm (called NSGA-II/OSD) is tested on a classic Operations Research problem: the Multi-Objective Knapsack Problem (0-1 MOKP) with two objectives. Classic NSGA-II, MOEA/D and Global WASF-GA are used to compare the performance of NSGA-II/OSD. In the case of MOEA/D two different versions are implemented, each of them with a different strategy for specifying the reference point. These MOEA/D reference point strategies are thoroughly studied and new insights are provided. This paper analyses in depth the impact of overlapping solutions on MOEAs, studying the number of overlapping solutions, the number of solution repairs, the hypervolume metric, the attainment surfaces and the approximation to the real Pareto front, for different sizes of 0-1 MOKPs with two objectives. The proposed method offers very good performance when compared to the classic NSGA-II, MOEA/D and Global WASF-GA algorithms, all of them well-known in the literature.
Citation: Begoña González, Daniel A. Rossit, Máximo Méndez, Mariano Frutos. Objective space division-based hybrid evolutionary algorithm for handing overlapping solutions in combinatorial problems[J]. Mathematical Biosciences and Engineering, 2022, 19(4): 3369-3401. doi: 10.3934/mbe.2022156
Overlapping solutions occur when more than one solution in the space of decisions maps to the same solution in the space of objectives. This situation threatens the exploration capacity of Multi-Objective Evolutionary Algorithms (MOEAs), preventing them from having a good diversity in their population. The influence of overlapping solutions is intensified on multi-objective combinatorial problems with a low number of objectives. This paper presents a hybrid MOEA for handling overlapping solutions that combines the classic NSGA-II with a strategy based on Objective Space Division (OSD). Basically, in each generation of the algorithm, the objective space is divided into several regions using the nadir solution calculated from the current generation solutions. Furthermore, the solutions in each region are classified into non-dominated fronts using different optimization strategies in each of them. This significantly enhances the achieved diversity of the approximate front of non-dominated solutions. The proposed algorithm (called NSGA-II/OSD) is tested on a classic Operations Research problem: the Multi-Objective Knapsack Problem (0-1 MOKP) with two objectives. Classic NSGA-II, MOEA/D and Global WASF-GA are used to compare the performance of NSGA-II/OSD. In the case of MOEA/D two different versions are implemented, each of them with a different strategy for specifying the reference point. These MOEA/D reference point strategies are thoroughly studied and new insights are provided. This paper analyses in depth the impact of overlapping solutions on MOEAs, studying the number of overlapping solutions, the number of solution repairs, the hypervolume metric, the attainment surfaces and the approximation to the real Pareto front, for different sizes of 0-1 MOKPs with two objectives. The proposed method offers very good performance when compared to the classic NSGA-II, MOEA/D and Global WASF-GA algorithms, all of them well-known in the literature.

| [1] | C. A. C. Coello, G. B. Lamont, D. A. V. Veldhuizen, Evolutionary Algorithms for Solving Multi-Objective Problems, 2nd edition, Springer, New York, 2007. |
| [2] |
H. Zhang, J. Sun, T. Liu, K. Zhang, Q. Zhang, Balancing exploration and exploitation in multi-objective evolutionary optimization, Inf. Sci., 497 (2019), 129-148. https://doi.org/10.1016/j.ins.2019.05.046 doi: 10.1016/j.ins.2019.05.046

|
| [3] |
M. Méndez, D. A. Rossit, B. González, M. Frutos, Proposal and comparative study of evolutionary algorithms for optimum design of a gear system, IEEE Access, 8 (2020), 3482-3497. https://doi.org/10.1109/ACCESS.2019.2962906 doi: 10.1109/ACCESS.2019.2962906
|
| [4] |
C. Wang, J. Li, H. Rao, A. Chen, J. Jiao, N. Zou, L. Gu, Multi-objective grasshopper optimization algorithm based on multi-group and co-evolution, Math. Biosci. Eng., 18 (2021), 2527-2561. https://doi.org/10.3934/mbe.2021129 doi: 10.3934/mbe.2021129
|
| [5] |
K. Deb, A. Pratap, S. Agarwal, T. Meyarivan, A fast and elitist multiobjective genetic algorithm: NSGA-II, IEEE Trans. Evol. Comput., 6 (2002), 182-197. https://doi.org/10.1109/4235.996017 doi: 10.1109/4235.996017
|
| [6] |
Q. Zhang, H. Li, MOEA/D: A multiobjective evolutionary algorithm based on decomposition, IEEE Trans. Evol. Comput., 11 (2007), 712-731. https://doi.org/10.1109/TEVC.2007.892759 doi: 10.1109/TEVC.2007.892759
|
| [7] |
R. Saborido, A. B. Ruiz, M. Luque, Global WASF-GA: An evolutionary algorithm in multiobjective optimization to approximate the whole Pareto optimal front, Evol. Comput., 25 (2017), 309-349. https://doi.org/10.1162/EVCO_a_00175 doi: 10.1162/EVCO_a_00175
|
| [8] | A. P. Wierzbicki, The use of reference objectives in multiobjective optimization, in Multiple Criteria Decision Making, Theory and Applications, Springer, 177 (1980), 468-486. https://doi.org/10.1007/978-3-642-48782-8_32 |
| [9] | H. Ishibuchi, K. Doi, Y. Nojima, Reference point specification in MOEA/D for multi-objective and many-objective problems, in Proceedings of the 2016 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Budapest, Hungary, (2016), 004015-004020. https://doi.org/10.1109/SMC.2016.7844861 |
| [10] |
R. Wang, J. Xiong, H. Ishibuchi, G. Wu, T. Zhang, On the effect of reference point in MOEA/D for multi-objective optimization, Appl. Soft Comput., 58 (2017), 25-34. https://doi.org/10.1016/j.asoc.2017.04.002 doi: 10.1016/j.asoc.2017.04.002
|
| [11] |
Z. Wang, Q. Zhang, H. Li, H. Ishibuchi, L. Jiao, On the use of two reference points in decomposition based multiobjective evolutionary algorithms, Swarm Evol. Comput., 34 (2017), 89-102. https://doi.org/10.1016/j.swevo.2017.01.002 doi: 10.1016/j.swevo.2017.01.002
|
| [12] | H. Ishibuchi, K. Narukawa, Y. Nojima, Handling of overlapping objective vectors in evolutionary multiobjective optimization, Int. J. Comput. Intell. Res., 1 (2005), 1-18. |
| [13] | Y. Wang, C. Dang, Improving multiobjective evolutionary algorithm by adaptive fitness and space division, in Advances in Natural Computation, Springer, (2005), 392-398. https://doi.org/10.1007/11539902_47 |
| [14] |
M. Wang, Y. Wang, X. Wang, A space division nultiobjective evolutionary algorithm based on adaptive multiple fitness functions, Int. J. Pattern Recognit. Artif. Intell., 30 (2016), 1659005. https://doi.org/10.1142/S0218001416590059 doi: 10.1142/S0218001416590059
|
| [15] |
C. He, Y. Tian, Y. Jin, X. Zhang, L. Pan, A radial space division based evolutionary algorithm for many-objective optimization, Appl. Soft Comput., 61 (2017), 603-621. https://doi.org/10.1016/j.asoc.2017.08.024 doi: 10.1016/j.asoc.2017.08.024
|
| [16] |
H. Chen, G. Wu, L. Huo, Y. Qi, Objective space division based adaptive multiobjective optimization algorithm, J. Software, 29 (2018), 2649-2663. https://doi.org/10.13328/j.cnki.jos.005278 doi: 10.13328/j.cnki.jos.005278
|
| [17] |
J. Liu, H. Zhang, K. He, S. Jiang, Multi-objective particle swarm optimization algorithm based on objective space division for the unequal-area facility layout problem, Expert Syst. Appl., 102 (2018), 179-192. https://doi.org/10.1016/j.eswa.2018.02.035 doi: 10.1016/j.eswa.2018.02.035
|
| [18] |
L. Pan, L. Li, C. He, K. C. Tan, A subregion division-based evolutionary algorithm with effective mating selection for many-objective optimization, IEEE Trans. Cybern., 50 (2020), 3477-3490. https://doi.org/10.1109/TCYB.2019.2906679 doi: 10.1109/TCYB.2019.2906679
|
| [19] |
W. Zhong, X. Hu, F. Lu, J. Wang, X. Liu, Y. Chen, A two-stage adjustment strategy for space division based many-objective evolutionary optimization, IEEE Access, 8 (2020), 197249-197262. https://doi.org/10.1109/ACCESS.2020.3034754 doi: 10.1109/ACCESS.2020.3034754
|
| [20] |
X. Gandibleux, A. Freville, Tabu search based procedure for solving the 0-1 multiobjective knapsack problem: the two objectives case, J. Heuristics, 6 (2000), 361-383. https://doi.org/10.1023/A:1009682532542 doi: 10.1023/A:1009682532542
|
| [21] |
H. Ishibuchi, N. Akedo, Y. Nojima, Behavior of multiobjective evolutionary algorithms on many-objective knapsack problems, IEEE Trans. Evol. Comput., 19 (2015), 264-283. https://doi.org/10.1109/TEVC.2014.2315442 doi: 10.1109/TEVC.2014.2315442
|
| [22] |
J. Yuan, H. Liu, C. Peng, Population decomposition-based greedy approach algorithm for the multi-objective knapsack problems, Int. J. Pattern Recognit. Artif. Intell., 31 (2017), 1759006. https://doi.org/10.1142/S0218001417590066 doi: 10.1142/S0218001417590066
|
| [23] |
N. Kantoura, S. Bouroubia, D. Chaabane, A parallel MOEA with criterion-based selection applied to the knapsack problem, Appl. Soft Comput., 80 (2019), 358-373. https://doi.org/10.1016/j.asoc.2019.04.005 doi: 10.1016/j.asoc.2019.04.005
|
| [24] |
M. Mahrach, G. Miranda, C. León, E. Segredo, Comparison between single and multi-objective evolutionary algorithms to solve the knapsack problem and the travelling salesman problem, Mathematics, 8 (2020), 2018. https://doi.org/10.3390/math8112018 doi: 10.3390/math8112018
|
| [25] | Y. Sato, M. Sato, M. Midtlyng, M. Miyakawa, Parallel and distributed MOEA/D with exclusively evaluated mating and migration, in Proceedings of the 2020 IEEE Congress on Evolutionary Computation (CEC), Glasgow, UK, (2020), 1-8. https://doi.org/10.1109/CEC48606.2020.9185559 |
| [26] | S. Zapotecas-Martínez, A. Menchaca-Méndez, On the performance of generational and steady-state MOEA/D in the multi-objective 0/1 knapsack problem, in Proceedings of the 2020 IEEE Congress on Evolutionary Computation (CEC), Glasgow, UK, (2020), 1-8. https://doi.org/10.1109/CEC48606.2020.9185715 |
| [27] | D. A. Rossit, M. Méndez, M. Frutos, B. González, Hybrid evolutionary algorithm based on objective space division for the bi-objective knapsack problem, in Production Research: 10th International Conference of Production Research-Americas (ICPR-Americas 2020), Bahía Blanca, Argentina, 2020, Part I, Springer Nature, 2021. |
| [28] | E. Zitzler, L. Thiele, Multiobjective optimization using evolutionary algorithms--A comparative case study, in Parallel Problem Solving from Nature-PPSN IV, Springer, LNCS, 1498 (1998), 292-301. https://doi.org/10.1007/BFb0056872 |
| [29] | C. M. Fonseca, P. J. Fleming, On the performance assessment and comparison of stochastic multiobjective optimizers, in Parallel Problem Solving from Nature-PPSN IV, Springer, LNCS, 1141 (1996), 584-593. https://doi.org/10.1007/3-540-61723-X_1022 |
| [30] | J. Knowles, A summary-attainment-surface plotting method for visualizing the performance of stochastic multiobjective optimizers, in 5th International Conference on Intelligent Systems Design and Applications (ISDA 05), Warsaw, Poland, (2005), 552-557. https://doi.org/10.1109/ISDA.2005.15 |
| [31] |
F. Wilcoxon, Individual comparisons by ranking methods, Biom. Bull., 1 (1945), 80-83. https://doi.org/10.2307/3001968 doi: 10.2307/3001968
|
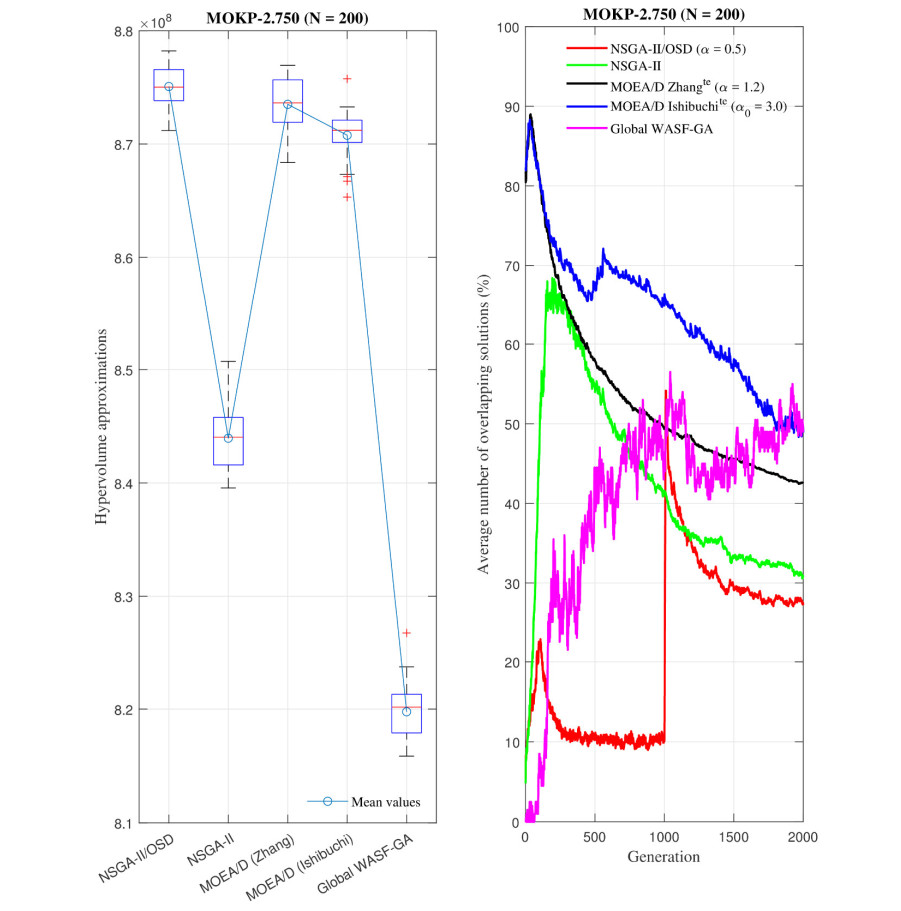
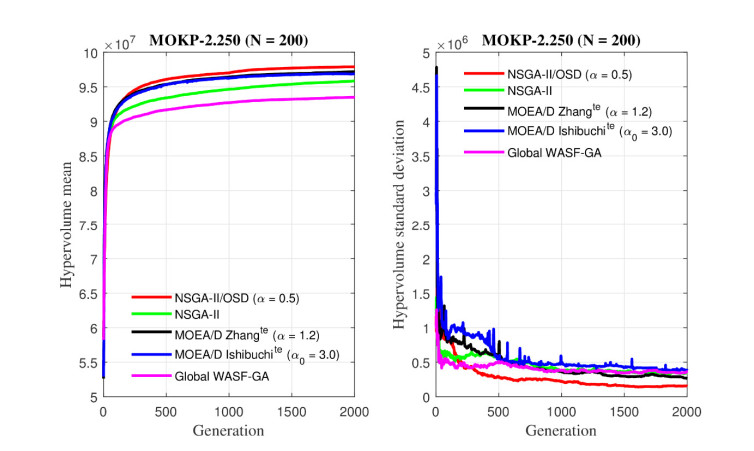
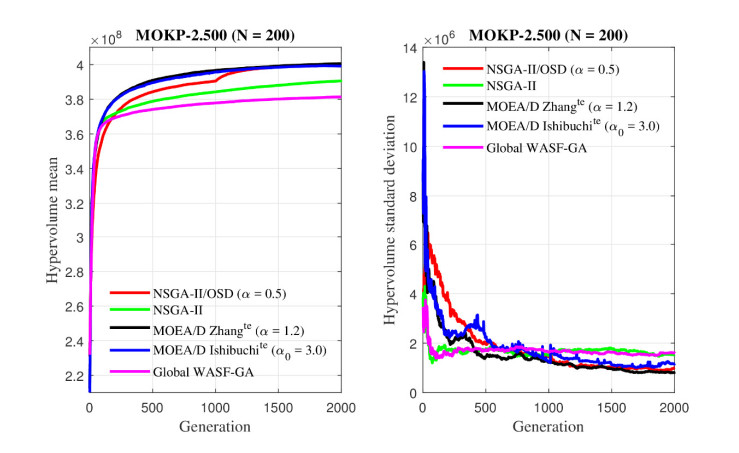
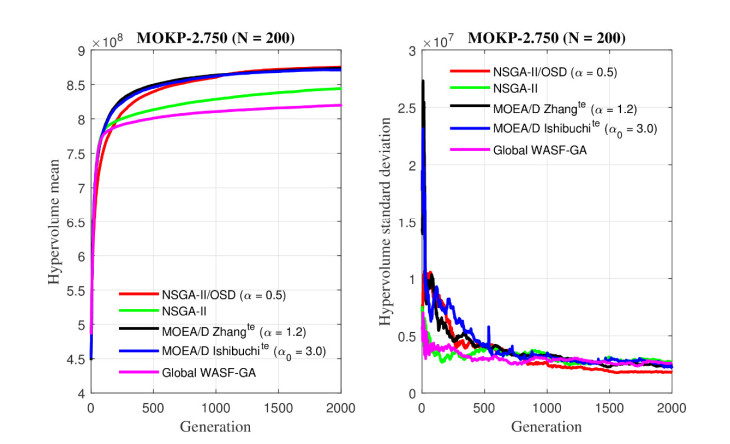
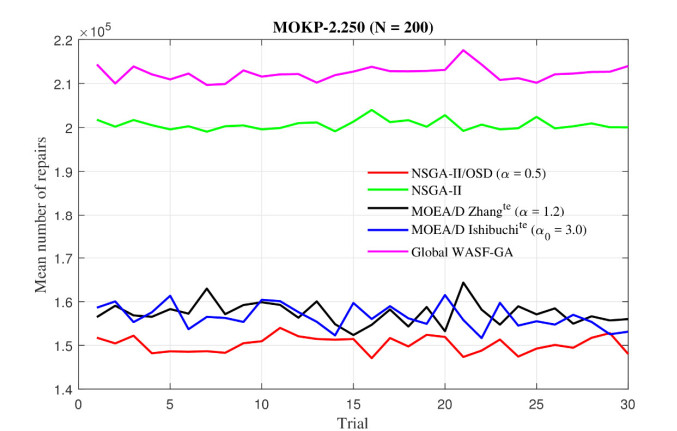
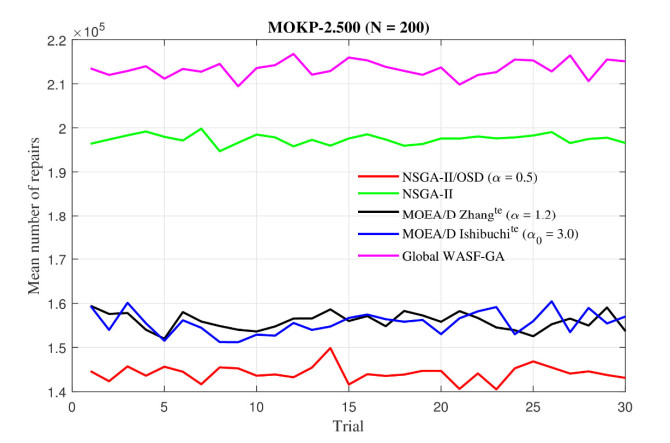
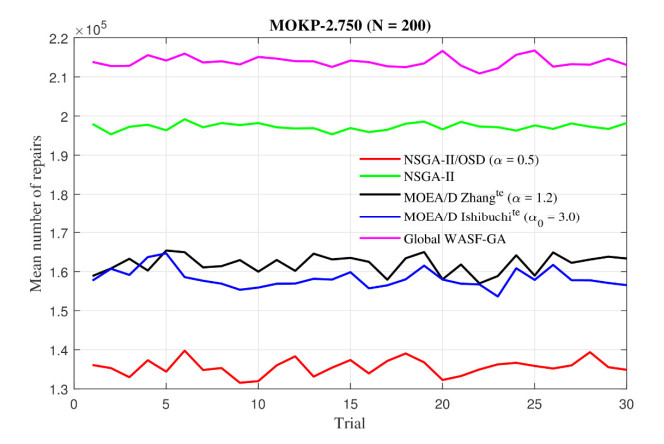
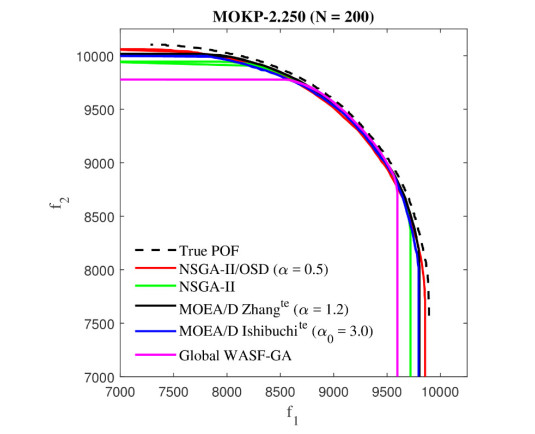
Figures(26) / Tables(6)

Begoña González, Daniel A. Rossit, Máximo Méndez, Mariano Frutos. Objective space division-based hybrid evolutionary algorithm for handing overlapping solutions in combinatorial problems[J]. Mathematical Biosciences and Engineering, 2022, 19(4): 3369-3401. doi: 10.3934/mbe.2022156







 DownLoad:
DownLoad: