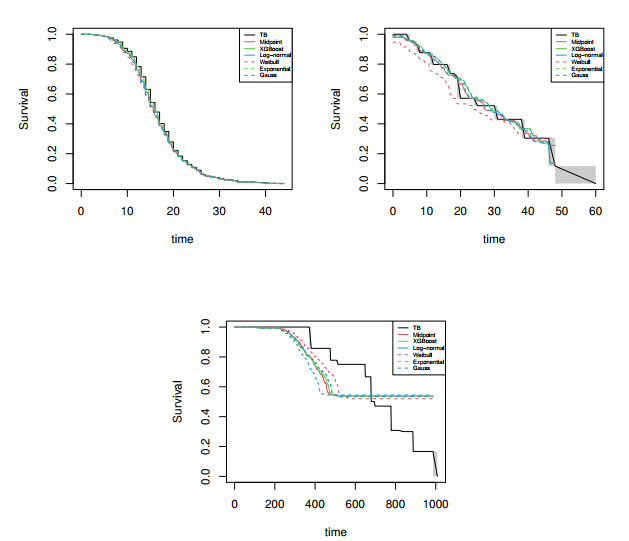
Interval-censored data pose challenges in survival analysis because event times are only known to occur within observation intervals. Traditional strategies, such as midpoint imputation, often fail to capture the uncertainty inherent to this censoring. This study compares classical, model-based, and machine learning approaches for imputing interval-censored event times. Specifically, we evaluate (ⅰ) standard midpoint imputation, (ⅱ) accelerated failure time (AFT) model–based imputation, (ⅲ) a machine learning method using XGBoost, and (ⅳ) a new scaled linear redistribution method that constrains model-based imputations within censoring bounds while preserving their relative variability. A comprehensive simulation study under varying levels of right censoring was carried out to assess bias, accuracy, and concordance. Three real datasets were then analyzed to illustrate the practical behavior of the imputation methods. Results show that the XGBoost-based imputation shows stable performance across the different censoring scenarios considered, yielding survival estimates close to those of the nonparametric Turnbull estimator. The midpoint method performs adequately when intervals are short or censoring is mild, whereas parametric models are more sensitive to distributional assumptions and may yield biased estimates under heavy censoring. Analyses of real data further revealed greater variability among parametric models under high right censoring and a flattening of survival curves when censoring occurs, mainly at long event times. The proposed scaled linear redistribution method provides a way to map model-based predictions back to their observed censoring intervals while retaining their relative dispersion. The methods considered display complementary strengths across censoring regimes, with no single approach uniformly dominating.
Citation: Gustavo Soutinho, Luís Meira-Machado. Imputation strategies for interval-censored data: from AFT models to machine learning and scaled redistribution[J]. AIMS Mathematics, 2026, 11(3): 5719-5737. doi: 10.3934/math.2026235
Interval-censored data pose challenges in survival analysis because event times are only known to occur within observation intervals. Traditional strategies, such as midpoint imputation, often fail to capture the uncertainty inherent to this censoring. This study compares classical, model-based, and machine learning approaches for imputing interval-censored event times. Specifically, we evaluate (ⅰ) standard midpoint imputation, (ⅱ) accelerated failure time (AFT) model–based imputation, (ⅲ) a machine learning method using XGBoost, and (ⅳ) a new scaled linear redistribution method that constrains model-based imputations within censoring bounds while preserving their relative variability. A comprehensive simulation study under varying levels of right censoring was carried out to assess bias, accuracy, and concordance. Three real datasets were then analyzed to illustrate the practical behavior of the imputation methods. Results show that the XGBoost-based imputation shows stable performance across the different censoring scenarios considered, yielding survival estimates close to those of the nonparametric Turnbull estimator. The midpoint method performs adequately when intervals are short or censoring is mild, whereas parametric models are more sensitive to distributional assumptions and may yield biased estimates under heavy censoring. Analyses of real data further revealed greater variability among parametric models under high right censoring and a flattening of survival curves when censoring occurs, mainly at long event times. The proposed scaled linear redistribution method provides a way to map model-based predictions back to their observed censoring intervals while retaining their relative dispersion. The methods considered display complementary strengths across censoring regimes, with no single approach uniformly dominating.

| [1] | J. P. Klein, M. L. Moeschberger, Survival analysis: techniques for censored and truncated data, Springer-Verlag, 1997. https://doi.org/10.1007/978-1-4757-2728-9 |
| [2] | M. Tableman, J. S. Kim, Survival analysis using S, Chapman & Hall Ltd, 2003. https://doi.org/10.1201/b16988 |
| [3] | D. G. Kleinbaum, M. Klein, Survival analysis: a self-learning text, Springer-Verlag, 2012. https://doi.org/10.1007/978-1-4419-6646-9 |
| [4] |
M. Abrahamowicz, M. E. Beauchamp, C. S. Moura, S. Bernatsky, S. F. Guerra, C. Danieli, Adapting SIMEX to correct for bias due to interval-censored outcomes in survival analysis with time-varying exposure, Biometrical J., 64 (2022), 1467—1485. https://doi.org/10.1002/bimj.202100013 doi: 10.1002/bimj.202100013

|
| [5] | K. Bogaerts, A. Komarek, E. Lesaffre, Survival analysis with interval-censored data: a practical approach with examples in R, SAS, and BUGS, Chapman and Hall/CRC, 2017 https://doi.org/10.1201/9781315116945 |
| [6] |
B. W. Turnbull, The empirical distribution function with arbitrarily grouped, censored and truncated data, J. R. Stat. Soc. Ser. B (Methodol.), 38 (1976), 290–295. https://doi.org/10.1111/J.2517-6161.1976.TB01597.X doi: 10.1111/J.2517-6161.1976.TB01597.X
|
| [7] |
D. R. Cox, Regression models and life-tables, J. R. Stat. Soc. Ser. B (Methodol.), 34 (1972), 187–202. https://doi.org/10.1111/j.2517-6161.1972.tb00899.x doi: 10.1111/j.2517-6161.1972.tb00899.x
|
| [8] | J. F. Lawless, Statistical models and methods for lifetime data, John Wiley & Sons, Inc., 2002. https://doi.org/10.1002/9781118033005 |
| [9] | J. D. Kalbfleisch, R. L. Prentice, The statistical analysis of failure time data, John Wiley & Sons, 2002. http://doi.org/10.1002/9781118032985 |
| [10] | J. W. Bartlett, R. Keogh, E. F. Bonneville, C. T. Ekstrøm, smcfcs: Substantive model compatible fully conditional specification, R package, 2024. Available from: https://cran.r-project.org/package = smcfcs. |
| [11] |
P. Wang, Y. Li, C. K. Reddy, Machine learning for survival analysis: a survey, ACM Comput. Surv., 51 (2019), 1–36. https://doi.org/10.1145/3214306 doi: 10.1145/3214306
|
| [12] |
H. Kvamme, Ø. Borgan, Continuous and discrete-time survival prediction with neural networks, Lifetime Data Anal., 27 (2021), 710–736. http://doi.org/10.1007/s10985-021-09532-6 doi: 10.1007/s10985-021-09532-6
|
| [13] |
Y. Deng, T. Lumley, Multiple imputation through XGBoost, J. Comput. Graph. Stat., 33 (2024), 352–363. https://doi.org/10.1080/10618600.2023.2252501 doi: 10.1080/10618600.2023.2252501
|
| [14] |
Z. Jinbo, L. Yufu, M. Haitao, Handling missing data of using the XGBoost-based multiple imputation by chained equations regression method, Front Artif. Intell., 8 (2025). https://doi.org/10.3389/frai.2025.1553220 doi: 10.3389/frai.2025.1553220
|
| [15] |
I. Štajduhar, B. Dalbelo-Bašić, Uncensoring censored data for machine learning: a likelihood-based approach, Exp. Syst. Appl., 39 (2012), 7226–7234. https://doi.org/10.1016/j.eswa.2012.01.054 doi: 10.1016/j.eswa.2012.01.054
|
| [16] |
L. P. Chen, B. Qiu, Analysis of length-biased and partly interval-censored survival data with mismeasured covariates, Biometrics, 79 (2023), 3929–3940. https://doi.org/10.1111/biom.13898 doi: 10.1111/biom.13898
|
| [17] |
L. P. Chen, B. Qiu, SIMEXBoost: An R package for analysis of high-dimensional error-prone data based on boosting method, R J., 15 (2023), 5–16. https://doi.org/10.32614/RJ-2023-080 doi: 10.32614/RJ-2023-080
|
| [18] | E. L. Kaplan, P. Meier, Nonparametric estimation from incomplete observations, J. Am. Stat. Assoc., 53 (1958), 457–481. |
| [19] | L. Meira-machado, The Kaplan-Meier estimator: new insights and applications in multi-state survival analysis, In: Computational science and its applications – ICCSA 2023 Workshops, Lecture Notes in Computer Science, Springer, Cham, 2023,129–139. http://doi.org/10.1007/978-3-031-37129-5_11 |
| [20] |
V. Kariuki, A. Wanjoya, O. Ngesa, M. M. Mansour, E. M. A. Elrazik, A. Z. Afify, The accelerated failure time regression model under the extended-exponential distribution with survival analysis, AIMS Math., 9 (2024), 15610–15638. https://doi.org/10.3934/math.2024754 doi: 10.3934/math.2024754
|
| [21] |
T. Chen, C. Guestrin, XGBoost: A scalable tree boosting system, Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2016,785–794. https://doi.org/10.1145/2939672.2939785 doi: 10.1145/2939672.2939785
|
| [22] |
K. Borch-Johnsens, P. K. Andersen, T. Decker, The effect of proteinuria on relative mortality in Type Ⅰ (insulin-dependent) diabetes mellitus, Diabetologia, 28 (1985), 590–596. https://doi.org/10.1007/BF00281993 doi: 10.1007/BF00281993
|
| [23] |
D. M. Finkelstein, R. A. Wolfe, A semiparametric model for regression analysis of interval-censored failure time data, Biometrics, 41 (1985), 733–945. https://doi.org/10.2307/2530965 doi: 10.2307/2530965
|
| [24] |
D. G. Hoel, H. E. Walburg, Statistical analysis of survival experiments, J. Natl. Cancer Inst., 49 (1972), 361–372. https://doi.org/10.1093/JNCI/49.2.361 doi: 10.1093/JNCI/49.2.361
|
Figures(1) / Tables(2)

Gustavo Soutinho, Luís Meira-Machado. Imputation strategies for interval-censored data: from AFT models to machine learning and scaled redistribution[J]. AIMS Mathematics, 2026, 11(3): 5719-5737. doi: 10.3934/math.2026235







 DownLoad:
DownLoad: