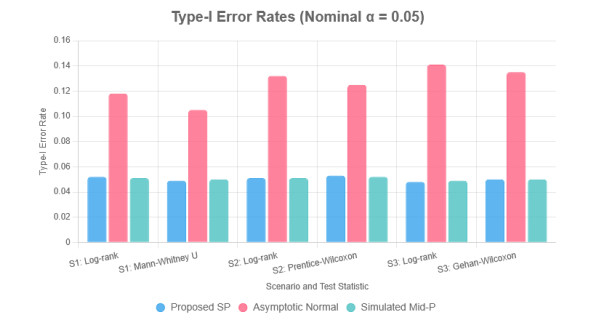
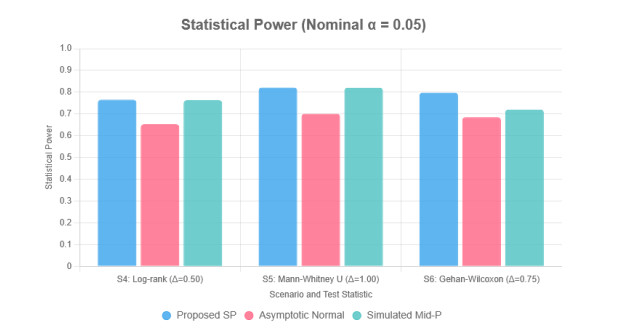
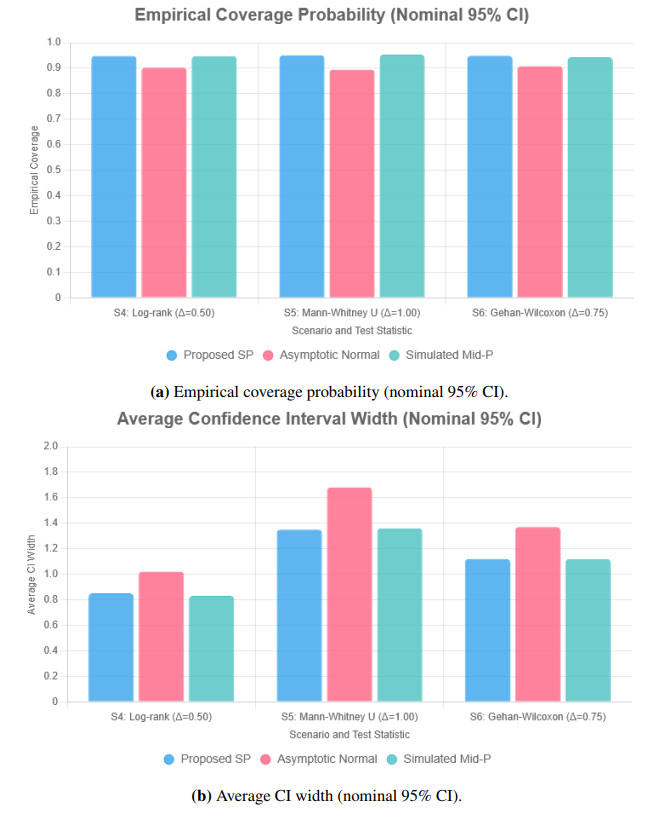
Randomized block urn design is a clinical trial design that is increasingly being used as a means of treatment allocation to balance the treatment allocation. With repeated measures or multi-centre trials though, the corresponding complex structures of dependency invalidate the standard asymptotic approximations, even in small to moderate samples. In this paper, a high-accuracy saddlepoint approximation model of a linear rank test is established with the dual conditions of cluster sampling and adaptive urn randomization. We obtained the joint cumulant generating function of the test statistic conditional in the realized block allocation counts, and the accurate calculation of mid-$ p $-values that takes into consideration the discreteness of rank scores. We have a wide variety of classes of score functions, such as the log-rank, GehanWilcoxon and MannWhitney statistics. Wide-scale simulation experiments showed that the suggested saddlepoint algorithm is much more effective at controlling Type-Ⅰ error rates and preserving nominal coverage probabilities of confidence intervals, and is comparable to computationally-intensive permutation benchmarks even with strong intra-cluster correlation. Its approach was demonstrated by applying it to oncology and ophthalmology trial data demonstrating its soundness in finite-sample cases.
Citation: Haidy A. Newer, Bader S. Alanazi. Accurate saddlepoint approximations for clustered rank tests under randomized block urn design[J]. AIMS Mathematics, 2026, 11(3): 5340-5364. doi: 10.3934/math.2026220
Randomized block urn design is a clinical trial design that is increasingly being used as a means of treatment allocation to balance the treatment allocation. With repeated measures or multi-centre trials though, the corresponding complex structures of dependency invalidate the standard asymptotic approximations, even in small to moderate samples. In this paper, a high-accuracy saddlepoint approximation model of a linear rank test is established with the dual conditions of cluster sampling and adaptive urn randomization. We obtained the joint cumulant generating function of the test statistic conditional in the realized block allocation counts, and the accurate calculation of mid-$ p $-values that takes into consideration the discreteness of rank scores. We have a wide variety of classes of score functions, such as the log-rank, GehanWilcoxon and MannWhitney statistics. Wide-scale simulation experiments showed that the suggested saddlepoint algorithm is much more effective at controlling Type-Ⅰ error rates and preserving nominal coverage probabilities of confidence intervals, and is comparable to computationally-intensive permutation benchmarks even with strong intra-cluster correlation. Its approach was demonstrated by applying it to oncology and ophthalmology trial data demonstrating its soundness in finite-sample cases.

| [1] |
E. F. Abd-Elfattah, Saddlepoint p-values and confidence intervals for the class of linear rank tests for censored data under generalized randomized block design, Computation. Stat., 30 (2015), 593–604. https://doi.org/10.1007/s00180-014-0551-9 doi: 10.1007/s00180-014-0551-9

|
| [2] |
J. G. Booth, R. W. Butler, Randomization distributions and saddlepoint approximations in generalized linear models, Biometrika, 77 (1990), 787–796. https://doi.org/10.1093/biomet/77.4.787 doi: 10.1093/biomet/77.4.787
|
| [3] |
A. Burton, D. G. Altman, P. Royston, D. J. Holder, The design of simulation studies in medical statistics, Stat. Med., 25 (2006), 4277–4292. https://doi.org/10.1002/sim.2673 doi: 10.1002/sim.2673
|
| [4] |
H. Daniels, Saddlepoint approximation in statistics, Ann. Math. Stat., 25 (1954), 631–650. https://doi.org/10.1214/aoms/1177728652 doi: 10.1214/aoms/1177728652
|
| [5] |
A. C. Davison, D. H. Hinkley, Saddlepoint approximations in resampling method, Biometrika, 75 (1988), 417–431. https://doi.org/10.1093/biomet/75.3.417 doi: 10.1093/biomet/75.3.417
|
| [6] |
M. W. Fagerland, S. Lydersen, P. Laake, The McNemar test for binary matched-pairs data: Mid-p and asymptotic are better than exact conditional, BMC Med. Res. Methodol., 13 (2013), 1–8. https://doi.org/10.1186/1471-2288-13-91 doi: 10.1186/1471-2288-13-91
|
| [7] |
B. Friedman, A simple urn model, Commun. Pur. Appl. Math., 2 (1949), 59–70. https://doi.org/10.1002/cpa.3160020103 doi: 10.1002/cpa.3160020103
|
| [8] |
E. A. Gehan, A generalized Wilcoxon test for comparing arbitrarily single censored samples, Biometrika, 52 (1965), 203–223. https://doi.org/10.2307/2333825 doi: 10.2307/2333825
|
| [9] |
R. J. Gray, A class of K-sample tests for comparing the cumulative incidence of a competing risk, Ann. Stat., 16 (1988), 1141–1154. https://doi.org/10.1214/aos/1176350951 doi: 10.1214/aos/1176350951
|
| [10] |
D. D. Hanagal, A. Pandey, Gamma frailty models for bivariate survival data, J. Stat. Comput. Sim, 85 (2015), 3172–3189. https://doi.org/10.1080/00949655.2014.958086 doi: 10.1080/00949655.2014.958086
|
| [11] |
Z. Hu, X. Du, Saddlepoint approximation reliability method for quadratic functions in normal variables, Struct. Saf., 71 (2018), 24–32. https://doi.org/10.1016/j.strusafe.2017.11.001 doi: 10.1016/j.strusafe.2017.11.001
|
| [12] |
J. Jeong, S. Jung, Rank tests for clustered survival data when dependent subunits are randomized, Stat. Med., 25 (2006), 361–373. https://doi.org/10.1002/sim.2218 doi: 10.1002/sim.2218
|
| [13] |
E. L. Kaplan, P. Meier, Nonparametric estimator from incomplete observations, J. Am. Stat. Assoc., 53 (1958), 457–481. https://doi.org/10.2307/2281868 doi: 10.2307/2281868
|
| [14] |
D. Kim, A. Agresti, Improved exact inference about conditional association in three-way contingency tables, J. Am. Stat. Assoc., 90 (1995), 632–639. https://doi.org/10.1080/01621459.1995.10476557 doi: 10.1080/01621459.1995.10476557
|
| [15] |
K. Y. Liang, S. L. Zeger, B. Qaqish, Multivariate regression analyses for categorical data, J. Roy. Stat. Soc. B, 54 (1992), 3–24. https://doi.org/10.1111/j.2517-6161.1992.tb01862.x doi: 10.1111/j.2517-6161.1992.tb01862.x
|
| [16] |
D. Meng, Y. Guo, Y. Xu, S. Yang, Y. Guo, L. Pan, Saddlepoint approximation method in reliability analysis: A review, CMES-Comp. Model. Eng., 139 (2024), 2329–2359. https://doi.org/10.32604/cmes.2024.047507 doi: 10.32604/cmes.2024.047507
|
| [17] |
D. Meng, S. Yang, T. Lin, J. Wang, H. Yang, Z. Lv, RBMDO using Gaussian mixture model-based second-order mean-value saddlepoint approximation, CMES-Comp. Model. Eng., 132 (2022), 553–568. https://doi.org/10.32604/cmes.2022.020756 doi: 10.32604/cmes.2022.020756
|
| [18] |
J. V. Monaco, M. Gorfine, L. Hsu, General semiparametric shared frailty model: Estimation and simulation with frailtySurv, J. Stat. Softw., 86 (2018), 1–42. https://doi.org/10.18637/jss.v086.i04 doi: 10.18637/jss.v086.i04
|
| [19] |
H. A. Newer, Saddle-point p-values and confidence intervals based on log-rank tests when dependent subunits of clustered survival data are randomized by random allocation design, Commun. Stat.-Theor. M., 52 (2023), 4072–4082. https://doi.org/10.1080/03610926.2021.1986532 doi: 10.1080/03610926.2021.1986532
|
| [20] |
H. A. Newer, A. Abd-El-Monem, Saddlepoint approximation for weighted log-rank tests based on block truncated binomial design, J. Biopharm. Stat., 33 (2023), 210–219. https://doi.org/10.1080/10543406.2022.2108825 doi: 10.1080/10543406.2022.2108825
|
| [21] |
H. A. Newer, The weighted log-rank tests based on stratified clustered survival data: Saddle-point p-values and confidence intervals, J. Biopharm. Stat., 33 (2023), 544–554. https://doi.org/10.1080/10543406.2022.2162070 doi: 10.1080/10543406.2022.2162070
|
| [22] | H. A. Newer, Saddlepoint approximation p-values of weighted log-rank tests based on censored clustered data under block Efron's biased-coin design, Stat. Methods Med. Res., 2023, 1–9. https://doi.org/10.1177/09622802221143498 |
| [23] |
H. A. Newer, P-values and confidence intervals for weighted log-rank tests under truncated binomial design based on clustered medical data, J. Biopharm. Stat., 35 (2025), 473–484. https://doi.org/10.1080/10543406.2024.2341676 doi: 10.1080/10543406.2024.2341676
|
| [24] |
H. A. Newer, Accurate and efficient P-values for rank-based independence tests with clustered data using a saddlepoint approximation, Sci. Rep., 15 (2025), 41816. https://doi.org/10.1038/s41598-025-26728-0 doi: 10.1038/s41598-025-26728-0
|
| [25] |
H. A. Newer, A saddlepoint framework for accurate inference in multicenter clinical trials with imbalanced clusters, Stat. Med., 45 (2026), e70408. https://doi.org/10.1002/sim.70408 doi: 10.1002/sim.70408
|
| [26] |
D. Oakes, On the intransitivity of the win ratio, Stat. Probabil. Lett., 216 (2025), 110267. https://doi.org/10.1016/j.spl.2024.110267 doi: 10.1016/j.spl.2024.110267
|
| [27] |
S. J. Pocock, C. A. Ariti, T. J. Collier, D. Wang, The win ratio: A new approach to the analysis of composite endpoints in clinical trials based on clinical priorities, Eur. Heart J., 33 (2012), 176–182. https://doi.org/10.1093/eurheartj/ehr352 doi: 10.1093/eurheartj/ehr352
|
| [28] |
R. L. Prentice, Linear rank tests with right censored data, Biometrika, 65 (1978), 167–179. https://doi.org/10.1093/biomet/65.1.167 doi: 10.1093/biomet/65.1.167
|
| [29] |
J. Robinson, Saddlepoint approximations for permutation tests and confidence intervals, J. Roy. Stat. Soc., 44 (1982), 91–101. https://doi.org/10.1111/j.2517-6161.1982.tb01191.x doi: 10.1111/j.2517-6161.1982.tb01191.x
|
| [30] | W. F. Rosenberger, J. M. Lachin, Randomization in clinical trials: Theory and practice, Wiley, 2015. https://doi.org/10.1002/9781118742112 |
| [31] |
B. Rosner, Multivariate methods in ophthalmology with application to other paired data situations, Biometrics, 40 (1984), 1025–1035. https://doi.org/10.2307/2531153 doi: 10.2307/2531153
|
| [32] |
B. Rosner, D. Grove, Use of the Mann–Whitney U-test for clustered data, Stat. Med., 18 (1999), 1387–1400. https://doi.org/10.1002/(SICI)1097-0258(19990615)18:11%3C1387::AID-SIM126%3E3.0.CO;2-V doi: 10.1002/(SICI)1097-0258(19990615)18:11%3C1387::AID-SIM126%3E3.0.CO;2-V
|
| [33] |
I. Skovgaard, Saddlepoint expansions for conditional distributions, J. Appl. Probab., 24 (1987), 875–887. https://doi.org/10.2307/3214212 doi: 10.2307/3214212
|
| [34] | M. E. Terry, Some rank order tests which are most powerful against specific parametric alternatives, Ann. Math. Stat., (1952), 346–366. Available from: https://www.jstor.org/stable/2236679. |
| [35] | P. H. Van Elteren, On the combination of independent two sample tests of Wilcoxon, Bull. Inst. Internat. Statist., 37 (1960), 351–361. |
| [36] | L. J. Wei, The design for the control of selection bias (technical report), University of South Carolina-Columbia, Department of Mathematics and Computer Science, 1975. |
| [37] |
L. J. Wei, A class of designs for sequential clinical trials, J. Am. Stat. Assoc., 72 (1977), 382–386. https://doi.org/10.1080/01621459.1977.10481005 doi: 10.1080/01621459.1977.10481005
|
| [38] |
L. J. Wei, The accelerated failure time model: A useful alternative to the Cox regression model in survival analysis, Stat. Med., 11 (1992), 1871–1879. https://doi.org/10.1002/sim.4780111409 doi: 10.1002/sim.4780111409
|
| [39] |
Y. Zhang, W. F. Rosenberger, R. T. Smythe, Sequential monitoring of randomization tests: Stratified randomization, Biometrics, 63 (2017), 865–872. https://doi.org/10.1111/j.1541-0420.2006.00735.x doi: 10.1111/j.1541-0420.2006.00735.x
|
| [40] |
W. Zhao, Y. Weng, Block urn design: A new randomization algorithm for sequential trials with two or more treatments and balanced or unbalanced allocation, Contemp. Clin. Trials, 32 (2011), 953–961. https://doi.org/10.1016/j.cct.2011.08.004 doi: 10.1016/j.cct.2011.08.004
|
Figures(3) / Tables(8)

Haidy A. Newer, Bader S. Alanazi. Accurate saddlepoint approximations for clustered rank tests under randomized block urn design[J]. AIMS Mathematics, 2026, 11(3): 5340-5364. doi: 10.3934/math.2026220







 DownLoad:
DownLoad: