Characterizing extremal structural relationships between sets of variables is central to the development of parsimonious models in extreme value analysis, particularly as statistical modeling in high dimensions remains challenging. In this study, we considered recently proposed statistical methods for learning the dependence structure of multivariate variables, with a focus on their ability to capture relationships at extreme levels. We considered complementary approaches that differed in their underlying modeling assumptions. One approach was less model-based and relied on the notion of partial tail correlation to assess extremal dependence between pairs of variables given the others. The other methods were rooted in graphical modeling frameworks, which provided a flexible means of representing complex dependence patterns and facilitated the investigation of higher-order extremal dependencies. We applied the methods to extreme rainfall data from the Lancashire region of the United Kingdom. The resulting dependence structures revealed some spatial heterogeneity, with distinct clustering behavior observed between northern and southern subregions. In particular, evidence of stronger higher-order dependence was concentrated in the southeastern area. These findings suggested that the effectiveness of flood defense and mitigation strategies may vary across subregions, highlighting the importance of accounting for extremal dependence structure in regional risk assessment and infrastructure planning.
Citation: Jeongjin Lee, Yongku Kim. Structure learning for multivariate extremes: A comparative study of regional UK rainfall[J]. AIMS Mathematics, 2026, 11(3): 5322-5339. doi: 10.3934/math.2026219
Characterizing extremal structural relationships between sets of variables is central to the development of parsimonious models in extreme value analysis, particularly as statistical modeling in high dimensions remains challenging. In this study, we considered recently proposed statistical methods for learning the dependence structure of multivariate variables, with a focus on their ability to capture relationships at extreme levels. We considered complementary approaches that differed in their underlying modeling assumptions. One approach was less model-based and relied on the notion of partial tail correlation to assess extremal dependence between pairs of variables given the others. The other methods were rooted in graphical modeling frameworks, which provided a flexible means of representing complex dependence patterns and facilitated the investigation of higher-order extremal dependencies. We applied the methods to extreme rainfall data from the Lancashire region of the United Kingdom. The resulting dependence structures revealed some spatial heterogeneity, with distinct clustering behavior observed between northern and southern subregions. In particular, evidence of stronger higher-order dependence was concentrated in the southeastern area. These findings suggested that the effectiveness of flood defense and mitigation strategies may vary across subregions, highlighting the importance of accounting for extremal dependence structure in regional risk assessment and infrastructure planning.

| [1] | L. de Haan, A. Ferreira, Extreme Value Theory: An Introduction, New York: Springer, 2006. |
| [2] | M. Kim, J. Lee, Hypothesis testing for partial tail correlation inmultivariate extremes, preprint paper, 2025. http://doi.org/10.48550/arXiv.2210.02048 |
| [3] |
T. Bedford, R. M. Cooke, Probability density decomposition for conditionally dependent random variables modeled by vines, Ann. Math. Artific. Intell., 32 (2001), 245–268. https://doi.org/10.1023/A:1016725902970 doi: 10.1023/A:1016725902970

|
| [4] |
T. Bedford, R. M. Cooke, Vines–a new graphical model for dependent random variables, Ann. Statist., 30 (2002), 1031–1068. https://doi.org/10.1214/aos/1031689016 doi: 10.1214/aos/1031689016
|
| [5] |
A. Kiriliouk, J. Lee, J. Segers, X-vine models for multivariate extremes, J. Royal Stat. Soc. Ser. B: Stat. Methodol., 87 (2025), 579–602. https://doi.org/10.1093/jrsssb/qkae105 doi: 10.1093/jrsssb/qkae105
|
| [6] |
S. Engelke, A. S. Hitz, Graphical models for extremes, J. Royal Stat. Soc. Ser. B: Stat. Methodol., 82 (2020), 871–932. https://doi.org/10.1111/rssb.12355 doi: 10.1111/rssb.12355
|
| [7] |
H. Rootzén, N. Tajvidi, Multivariate generalized Pareto distributions, Bernoulli, 12 (2006), 917–930. https://doi.org/10.3150/bj/1161614952 doi: 10.3150/bj/1161614952
|
| [8] | J. Hüsler, R. D. Reiss, Maxima of normal random vectors: Between independence and complete dependence, Stat. Probab. Lett., 7 (1989), 283–286. |
| [9] | S. I. Resnick, Heavy-tail Phenomena: Probabilistic and Statistical Modeling, New York: Springer, 2007. |
| [10] |
D. Cooley, E. Thibaud, Decompositions of dependence for high-dimensional extremes, Biometrika, 106 (2019), 587–604. https://doi.org/10.1093/biomet/asz028 doi: 10.1093/biomet/asz028
|
| [11] |
S. I. Resnick, C. Stărică, Asymptotic behavior of Hill's estimator for autoregressive data, Commun. Statist. Stochast. Models, 13 (1997a), 703–721. https://doi.org/10.1080/15326349708807448 doi: 10.1080/15326349708807448
|
| [12] |
S. I. Resnick, C. Stărică, Smoothing the Hill estimator, Adv. Appl. Probab., 29 (1997), 271–293. https://doi.org/10.2307/1427870 doi: 10.2307/1427870
|
| [13] |
R. Schmidt, U. Stadtmüller, Non-parametric estimation of tail dependence, Scandinavian J. Statist., 33 (2006), 307–335. https://doi.org/10.1111/j.1467-9469.2005.00483.x doi: 10.1111/j.1467-9469.2005.00483.x
|
| [14] |
R. C. Prim, Shortest connection networks and some generalizations, Bell Syst. Techn. J., 36 (1957), 1389–1401. https://doi.org/10.1002/j.1538-7305.1957.tb01515.x doi: 10.1002/j.1538-7305.1957.tb01515.x
|
| [15] |
J. B. Kruskal, On the shortest spanning subtree of a graph and the traveling salesman problem, Proc. Amer. Math. Soc., 7 (1956), 48–50. https://doi.org/10.2307/2033241 doi: 10.2307/2033241
|
| [16] | M. Sibuya, Bivariate extreme statistics, Ann. Inst. Statist. Math., 11 (1960), 195–210. |
| [17] | S. Coles, J. Bawa, L. Trenner, P. Dorazio, An Introduction to Statistical Modeling of Extreme Values, London: Springer, 2001. |
| [18] | C. Claudia, Analyzing Dependent Data with Vine Copulas, Switzerland: Springer, 2019. https://doi.org/10.1007/978-3-030-13785-4 |
| [19] |
T. Nagler, C. Bumann, C. Czado, Model selection in sparse high-dimensional vine copula models with an application to portfolio risk, J. Multivar. Anal., 172 (2019), 180–192. https://doi.org/10.1016/j.jmva.2019.03.004 doi: 10.1016/j.jmva.2019.03.004
|
| [20] |
S. Engelke, S. Volgushev, Structure learning for extremal tree models, J. Royal Statist. Soc.: Ser. B Statist. Methodol., 84 (2022), 2055–2087. https://doi.org/10.1111/rssb.12556 doi: 10.1111/rssb.12556
|
| [21] | S. Engelke, M. Lalancette, S. Volgushev, Learning extremal graphical structures in high dimensions, preprint paper, 2021. https://doi.org/10.48550/arXiv.2111.00840 |
| [22] | Met Office, MIDAS open: UK daily rainfall data, v202507, 2025. |
| [23] |
H. Mann, Nonparametric tests against trend, Econometrica, 13 (1945), 245–259. https://doi.org/10.2307/1907187 doi: 10.2307/1907187
|
| [24] | M. Kendall, Rank Correlation Methods, London: Charles Griffin, 1975. |
| [25] | J. Pickands Ⅲ, Statistical inference using extreme order statistics, Ann. Statist., 3 (1975), 119–131. |
| [26] | S. Engelke, A. Hitz, G. Nicola, M. Hentschel, GraphicalExtremes: Statistical methodology for graphical extreme value models, R package version 0.3.4, 2022. |
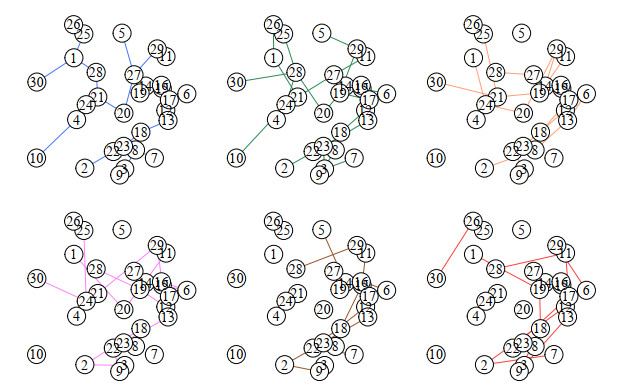
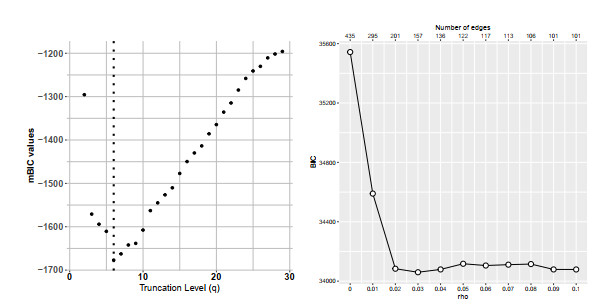
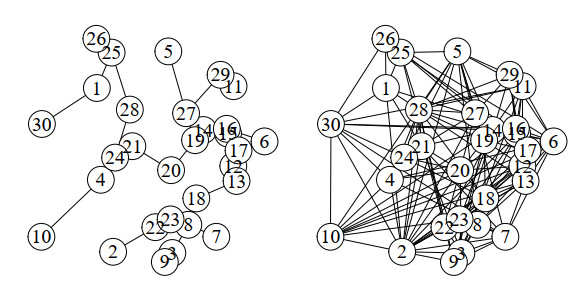
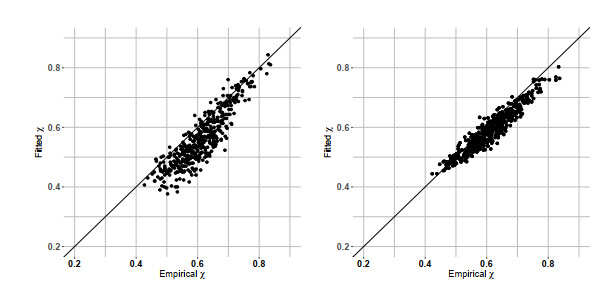
Figures(8) / Tables(1)

Jeongjin Lee, Yongku Kim. Structure learning for multivariate extremes: A comparative study of regional UK rainfall[J]. AIMS Mathematics, 2026, 11(3): 5322-5339. doi: 10.3934/math.2026219







 DownLoad:
DownLoad: