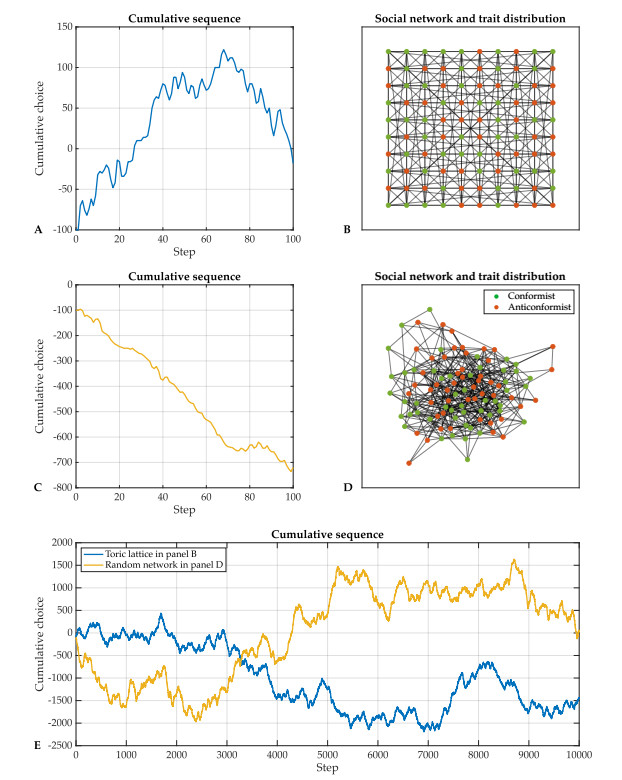
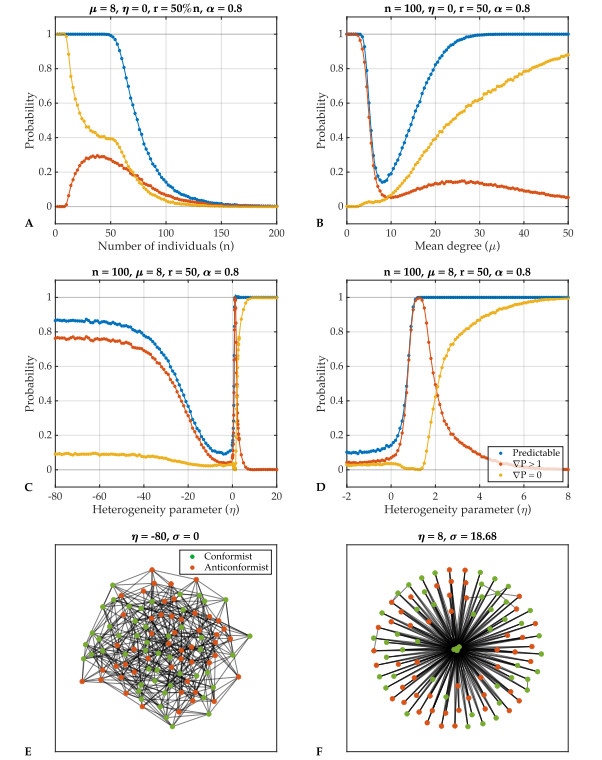
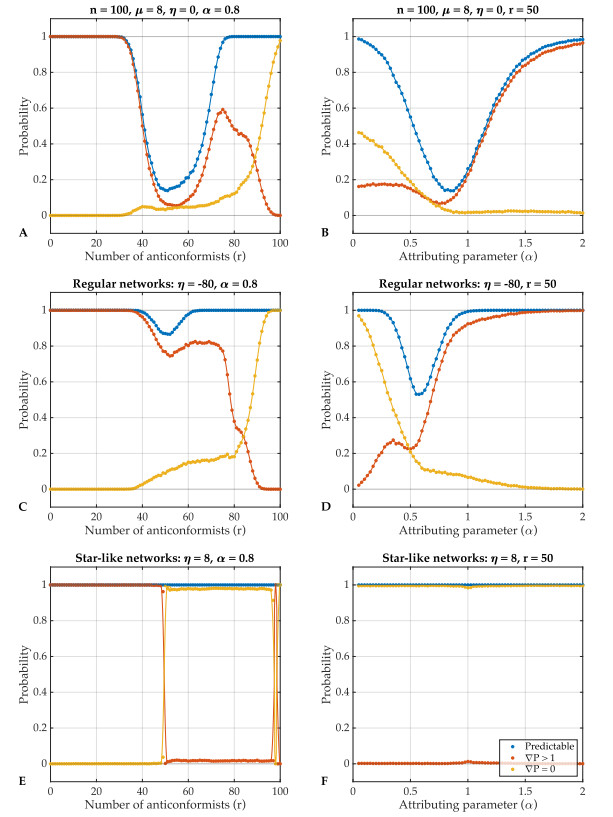
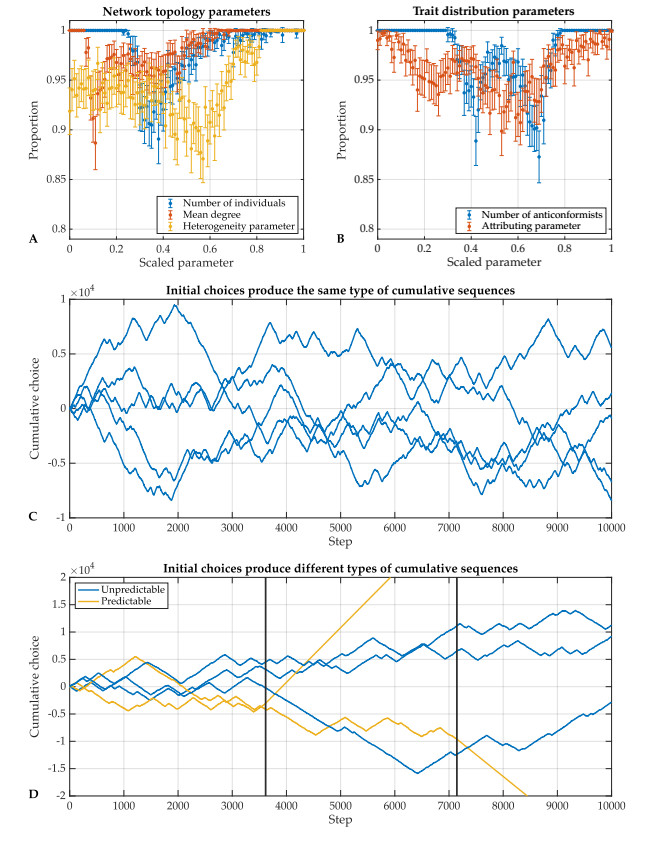
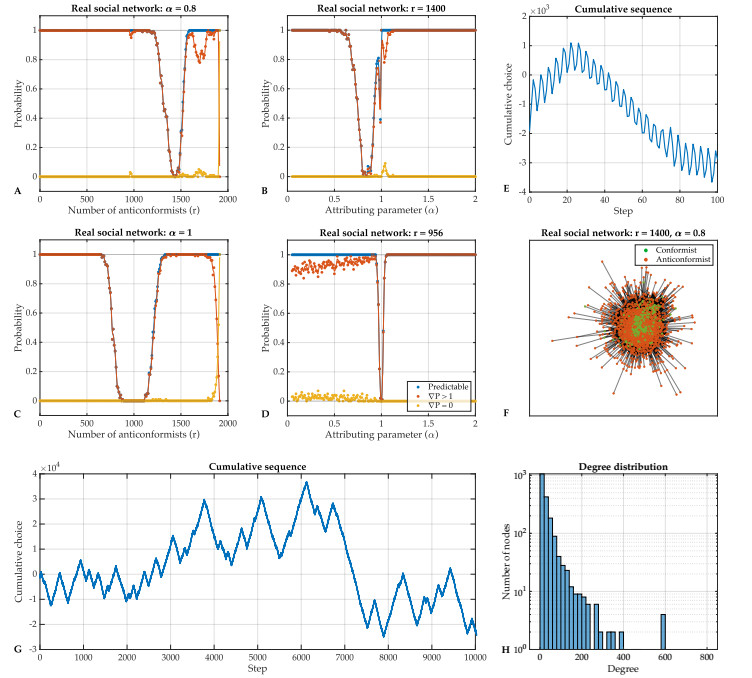
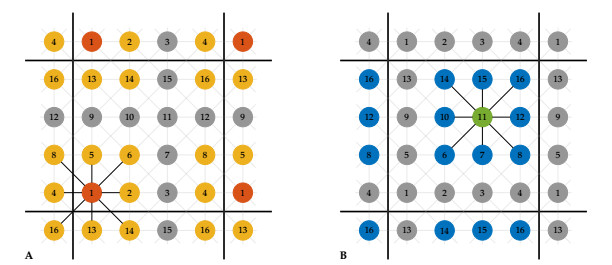
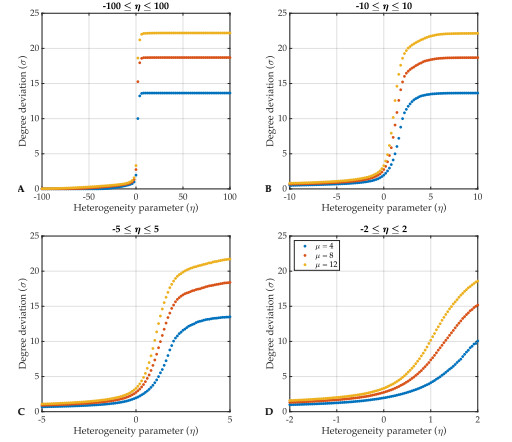
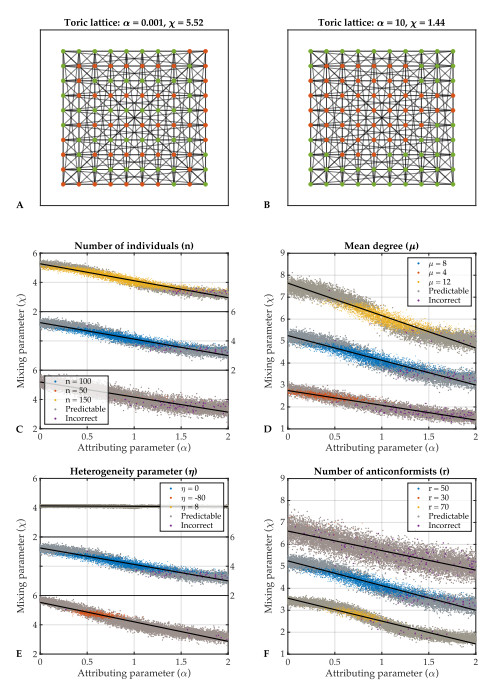
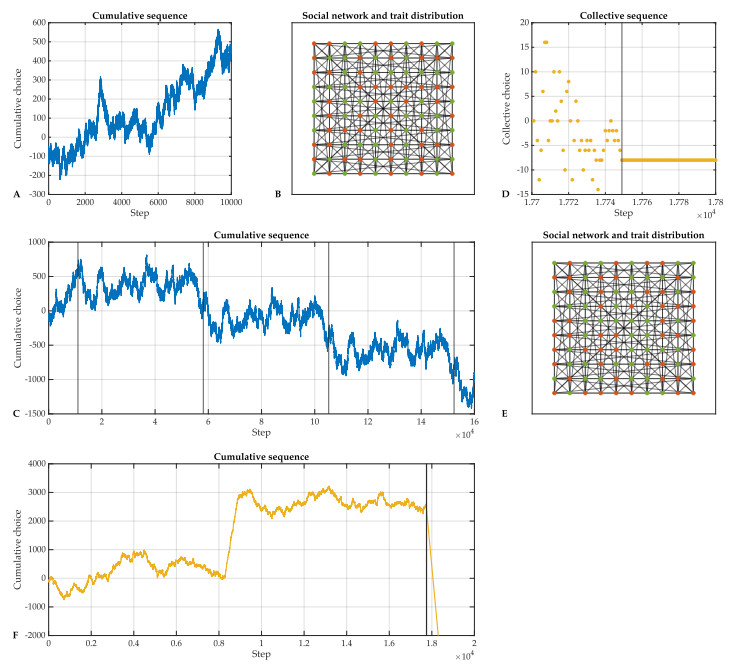
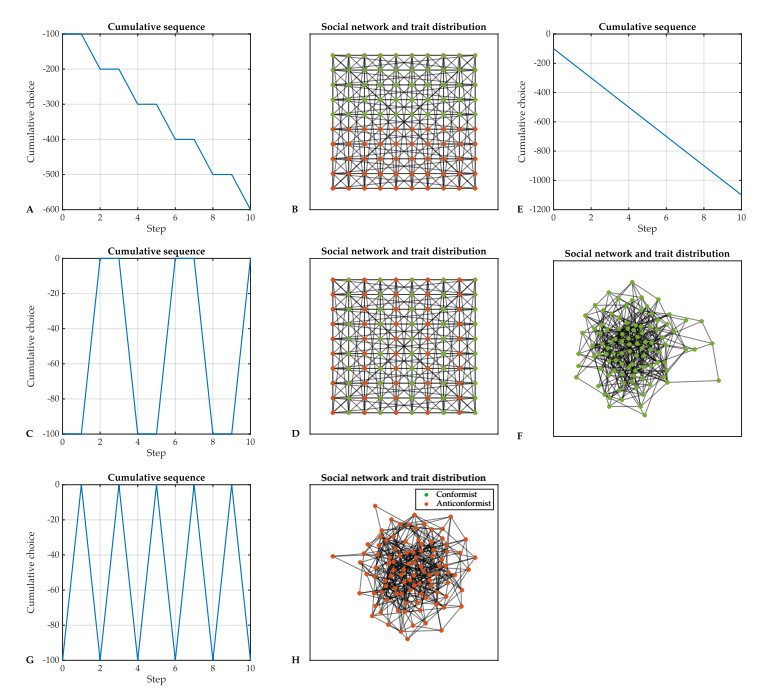
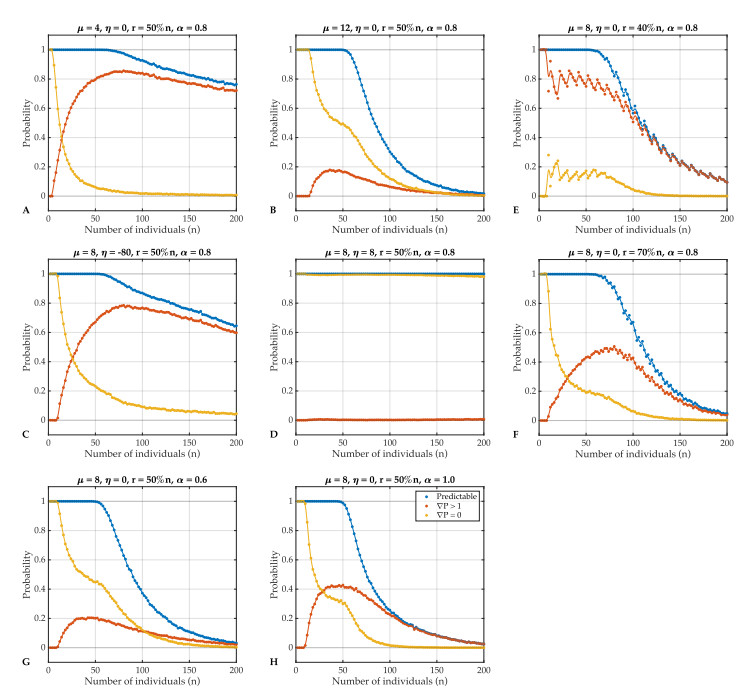
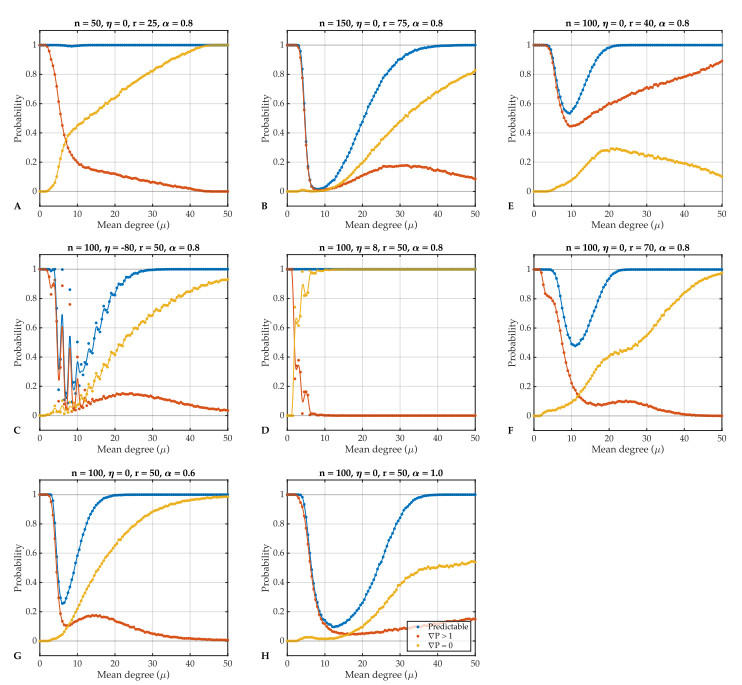
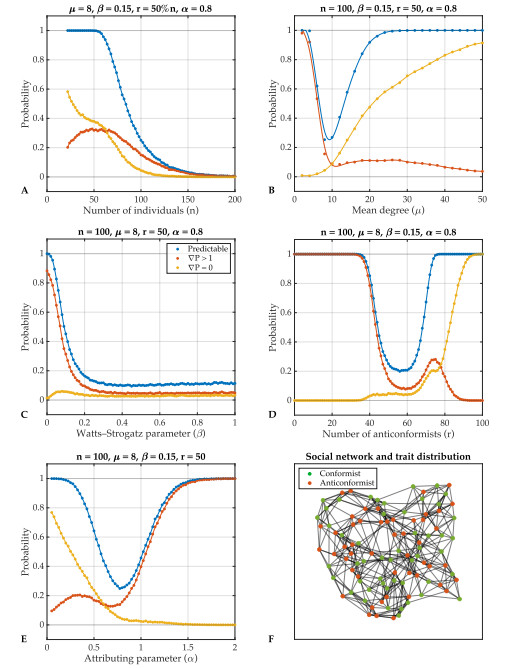
Individual-level interactions shape societal or economic processes, such as infectious diseases spreading, stock prices fluctuating and public opinion shifting. Understanding how the interaction of different individuals affects collective outcomes is more important than ever, as the internet and social media develop. Social networks representing individuals' influence relations play a key role in understanding the connections between individual-level interactions and societal or economic outcomes. Recent research has revealed how the topology of a social network affects collective decision-making in a community. Furthermore, the traits of individuals that determine how they process received information for making decisions also change a community's collective decisions. In this work, we develop stochastic processes to generate networks of individuals with two simple traits: Being a conformist and being an anticonformist. We introduce a novel deterministic voter model for a trait-attributed network, where the individuals make binary choices following simple deterministic rules based on their traits. We show that the simple deterministic rules can drive unpredictable fluctuations of collective decisions which eventually become periodic. We study the effects of network topology and trait distribution on the first passage time for a sequence of collective decisions showing periodicity.
Citation: Pengyu Liu, Jie Jian. Effects of network topology and trait distribution on collective decision making[J]. AIMS Mathematics, 2023, 8(5): 12287-12320. doi: 10.3934/math.2023619
Individual-level interactions shape societal or economic processes, such as infectious diseases spreading, stock prices fluctuating and public opinion shifting. Understanding how the interaction of different individuals affects collective outcomes is more important than ever, as the internet and social media develop. Social networks representing individuals' influence relations play a key role in understanding the connections between individual-level interactions and societal or economic outcomes. Recent research has revealed how the topology of a social network affects collective decision-making in a community. Furthermore, the traits of individuals that determine how they process received information for making decisions also change a community's collective decisions. In this work, we develop stochastic processes to generate networks of individuals with two simple traits: Being a conformist and being an anticonformist. We introduce a novel deterministic voter model for a trait-attributed network, where the individuals make binary choices following simple deterministic rules based on their traits. We show that the simple deterministic rules can drive unpredictable fluctuations of collective decisions which eventually become periodic. We study the effects of network topology and trait distribution on the first passage time for a sequence of collective decisions showing periodicity.

| [1] |
D. M. Abrams, S. H. Strogatz, Modelling the dynamics of language death, Nature, 424 (2003), 900–900. https://doi.org/10.1038/424900a doi: 10.1038/424900a

|
| [2] | S. P. Anderson, A. de Palma, J. F. Thisse, Discrete choice theory of product differentiation, The MIT Press, Cambridge, 1992. https://doi.org/10.7551/mitpress/2450.001.0001 |
| [3] |
W. A. Brock, S. N. Durlauf, Discrete choice with social interactions, Rev. Econ. Stud., 68 (2001), 235–260. https://doi.org/10.1111/1467-937X.00168 doi: 10.1111/1467-937X.00168
|
| [4] |
C. Castellano, M. A. Muñoz, R. Pastor-Satorras, Nonlinear q-voter model, Phys. Rev. E, 80 (2009), 041129. https://doi.org/10.1103/PhysRevE.80.041129 doi: 10.1103/PhysRevE.80.041129
|
| [5] |
T. Cheon, J. Morimoto, Balancer effects in opinion dynamics, Phys. Lett. A, 380 (2016), 429–434. https://doi.org/10.1016/j.physleta.2015.11.012 doi: 10.1016/j.physleta.2015.11.012
|
| [6] |
R. Cont, M. Löwe, Social distance, heterogeneity and social interactions, J. Math. Econ., 46 (2010), 572–590. https://doi.org/10.1016/j.jmateco.2010.03.009 doi: 10.1016/j.jmateco.2010.03.009
|
| [7] |
J. M. Epstein, Learning to be thoughtless: Social norms and individual computation, Comput. Econ., 18 (2001), 9–24. https://doi.org/10.1023/A:1013810410243 doi: 10.1023/A:1013810410243
|
| [8] |
M. Feng, Y. Li, F. Chen, J. Kurths, Heritable deleting strategies for birth and death evolving networks from a queueing system perspective, IEEE T. Syst. Man Cy.-S., 52 (2022), 6662–6673. https://doi.org/10.1109/TSMC.2022.3149596 doi: 10.1109/TSMC.2022.3149596
|
| [9] |
W. C. Fuller, C. F. Manski, D. A. Wise, New evidence on the economic determinants of postsecondary schooling choices, J. Hum. Resour., 17 (1982), 477–498. https://doi.org/10.2307/145612 doi: 10.2307/145612
|
| [10] |
S. Galam, Heterogeneous beliefs, segregation, and extremism in the making of public opinions, Phys. Rev. E, 71 (2005). https://doi.org/10.1103/PhysRevE.71.046123 doi: 10.1103/PhysRevE.71.046123
|
| [11] |
M. Granovetter, The impact of social structure on economic outcomes, J. Econ. Perspect., 19 (2005), 33–50. https://doi.org/10.1257/0895330053147958 doi: 10.1257/0895330053147958
|
| [12] |
R. H. Griffin, C. L. Nunn, Community structure and the spread of infectious disease in primate social networks, Evol. Ecol., 26 (2012), 779–800. https://doi.org/10.1007/s10682-011-9526-2 doi: 10.1007/s10682-011-9526-2
|
| [13] |
R. A. Holley, T. M. Liggett, Ergodic theorems for weakly interacting infinite systems and the voter model, Ann. Probab., 3 (1975), 643–663. https://doi.org/10.1214/aop/1176996306 doi: 10.1214/aop/1176996306
|
| [14] |
N. Horsevad, D. Mateo, R. E. Kooij, A. Barrat, R. Bouffanais, Transition from simple to complex contagion in collective decision-making, Nat. Commun., 13 (2022), 1442. https://doi.org/10.1038/s41467-022-28958-6 doi: 10.1038/s41467-022-28958-6
|
| [15] |
T. Krueger, J. Szwabiński, T. Weron, Conformity, anticonformity and polarization of opinions: Insights from a mathematical model of opinion dynamics, Entropy, 19 (2017). https://doi.org/10.3390/e19070371 doi: 10.3390/e19070371
|
| [16] |
B. Latané, The psychology of social impact, Am. Psychol., 36 (1981), 343–356. https://doi.org/10.1037/0003-066X.36.4.343 doi: 10.1037/0003-066X.36.4.343
|
| [17] | J. Leskovec, A. Krevl, SNAP datasets: Stanford large network dataset collection. Available from: http://snap.stanford.edu/data. |
| [18] |
C. Marr, M. T. Hütt, Outer-totalistic cellular automata on graphs, Phys. Lett. A, 373 (2009), 546–549. https://doi.org/10.1016/j.physleta.2008.12.013 doi: 10.1016/j.physleta.2008.12.013
|
| [19] |
D. Mateo, N. Horsevad, V. Hassani, M. Chamanbaz, R. Bouffanais, Optimal network topology for responsive collective behavior, Sci. Adv., 5 (2019), eaau0999. https://doi.org/10.1126/sciadv.aau0999 doi: 10.1126/sciadv.aau0999
|
| [20] |
A. Nowak, J. Szamrej, B. Latané, From private attitude to public opinion: A dynamic theory of social impact, Psychol. Rev., 97 (1990), 362–376. https://doi.org/10.1037/0033-295X.97.3.362 doi: 10.1037/0033-295X.97.3.362
|
| [21] |
B. Rozemberczki, C. Allen, R. Sarkar, Multi-Scale attributed node embedding, J. Complex Netw., 9 (2021), 5. https://doi.org/10.1093/comnet/cnab014 doi: 10.1093/comnet/cnab014
|
| [22] |
B. J. Singer, R. N. Thompson, M. B. Bonsall, The effect of the definition of 'pandemic' on quantitative assessments of infectious disease outbreak risk, Sci. Rep., 11 (2021), 2547. https://doi.org/10.1038/s41598-021-81814-3 doi: 10.1038/s41598-021-81814-3
|
| [23] |
T. A. Snijders, The degree variance: An index of graph heterogeneity, Soc. Networks, 3 (1981), 163–174. https://doi.org/10.1016/0378-8733(81)90014-9 doi: 10.1016/0378-8733(81)90014-9
|
| [24] |
K. Sznajd-Weron, J. Sznajd, Opinion evolution in closed community, Int. J. Mod. Phys. C, 11 (2000), 1157–1165. https://doi.org/10.1142/S0129183100000936 doi: 10.1142/S0129183100000936
|
| [25] |
K. E. Train, C. Winston, Vehicle choice behavior and the declining market share of US automakers, Int. Econ. Rev., 48 (2007), 1469–1496. https://doi.org/10.1111/j.1468-2354.2007.00471.x doi: 10.1111/j.1468-2354.2007.00471.x
|
| [26] |
D. J. Watts, S. H. Strogatz, Collective dynamics of 'small-world' networks, Nature, 393 (1998), 440–442. https://doi.org/10.1038/30918 doi: 10.1038/30918
|
| [27] |
Z. Zeng, Y. Li, M. Feng. The spatial inheritance enhances cooperation in weak prisoner's dilemmas with agents' exponential lifespan, Physica A, 593 (2022). https://doi.org/10.1016/j.physa.2022.126968 doi: 10.1016/j.physa.2022.126968
|
Figures(17) / Tables(2)

Pengyu Liu, Jie Jian. Effects of network topology and trait distribution on collective decision making[J]. AIMS Mathematics, 2023, 8(5): 12287-12320. doi: 10.3934/math.2023619







 DownLoad:
DownLoad: