Citation: Jonathan P. Hayton, Andrew R.J. Marshall, Michael D. Thompson, Anthony Krier. Characterisation of Ga1-xInxSb quantum wells (x~0.3) grown on GaAs using AlGaSb interface misfit buffer[J]. AIMS Materials Science, 2015, 2(2): 86-96. doi: 10.3934/matersci.2015.2.86

| [1] | Pascal-Delannoy F, Bouganot J, Allogho G, et al. (1992) MOVPE grown Ga0.6In0.4Sb photodiodes for 2.55um detection. Electron Lett 28: 531-532. |
| [2] |
Bertru N, Baranov A, Cuminal Y, et al. (1998) Long-wavelength (Ga, In)Sb/GaSb strained quantum well lasers grown by molecular beam epitaxy. Semicond Sci Technol 13: 936. doi: 10.1088/0268-1242/13/8/019

|
| [3] |
Krier A, Sherstnev V (2000) Powerful interface light emitting diodes for methane gas detection. J Phys D Appl Phys 33: 101. doi: 10.1088/0022-3727/33/2/301
|
| [4] | Refaat T, Abedin M, Koch G, et al. (2003) Infrared detector characterization for CO2 DIAL measurement. in Proc. SPIE 5154, Lidar Remote Sensing for Environmental Monitoring IV, San Diego, California, USA. |
| [5] |
Rotter TJ, Tatebayashi J, Senanayake P, et al. (2009) Continuous-Wave, Room-Temperature Operation of 2-μm Sb-Based Optically-Pumped Vertical-External-Cavity Surface-Emitting Laser Monolithically Grown on GaAs Substrates. Appl Phys Express 2: 112102. doi: 10.1143/APEX.2.112102
|
| [6] |
Demeo D, Shemelya C, Downs C, et al. (2014) GaSb Thermophotovoltaic Cells Grown on GaAs Substrate Using the Interfacial Misfit Array Method. J Electronic Mater 43: 902-908. doi: 10.1007/s11664-014-3029-1
|
| [7] | Craig A, Marshall A, Tian Z, et al. (2013) Mid-infrared InAs0.79Sb0.21-based nBn photodetectors with Al0.9Ga0.2As0.1Sb0.9 barrier layers, and comparisons with InAs0.87Sb0.13 p-i-n diodes, both grown on GaAs using interfacial misfit arrays. Appl Phys Lett 103: 253502. |
| [8] |
Huang S, Balakrishnan G, Huffaker D (2009) Interfacial misfit array formation for GaSb growth on GaAs. J Appl Phys 105: 103104. doi: 10.1063/1.3129562
|
| [9] |
Reyner C, Wang J, Nunna K, et al. (2011) Characterization of GaSb/GaAs interfacial misfit arrays using x-ray diffraction. Appl Phys Lett 99: 231906. doi: 10.1063/1.3666234
|
| [10] | Akahane K, Yamamoto N, Gozu S, et al. (2006) (In)GaSb/AlGaSb quantum wells grown on Si substrates. Thin Solid Films 515: 4467-4470. |
| [11] |
Jin S, Sweeney S (2003) High-Pressure Studies of Recombination Mechanisms in 1.3um GaInNAs Quantum-Well Lasers. IEEE J Sel Top Quantum Electron 9: 1196. doi: 10.1109/JSTQE.2003.819515
|
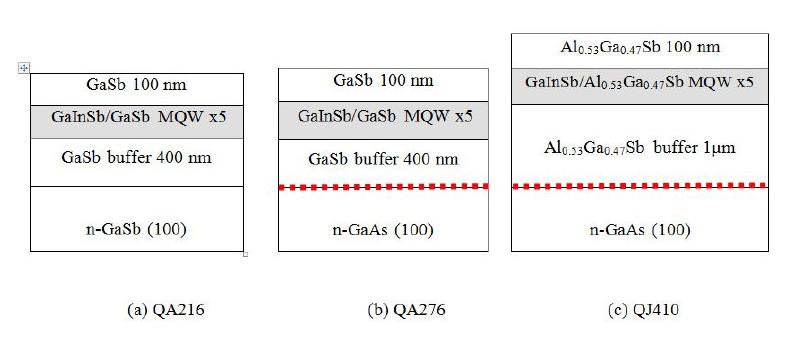
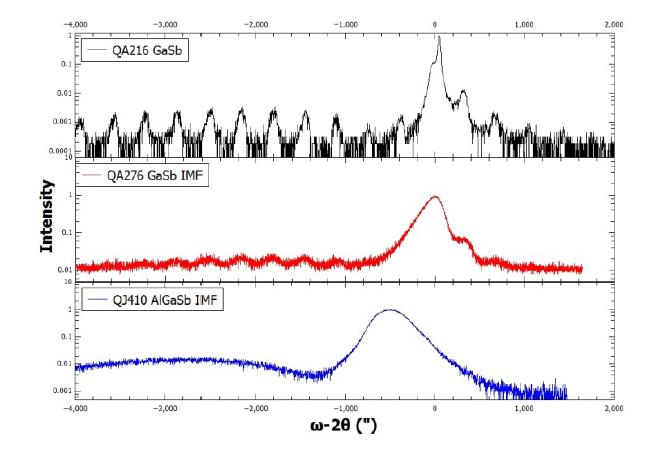

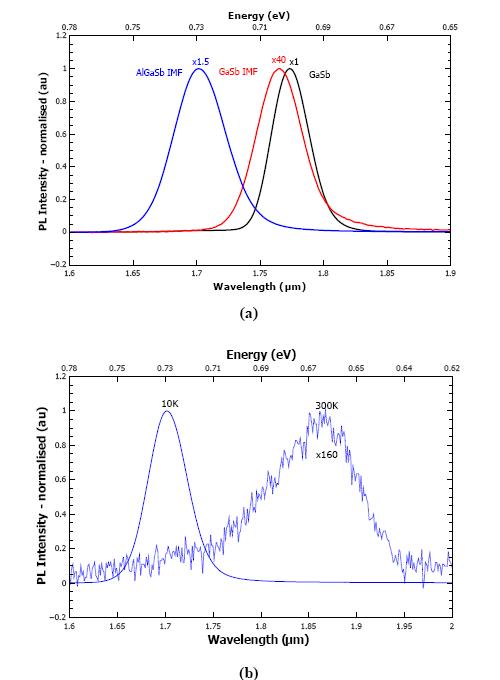
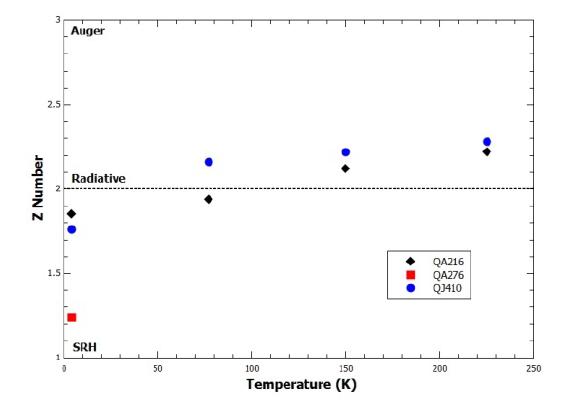
Figures(6) / Tables(1)

Jonathan P. Hayton, Andrew R.J. Marshall, Michael D. Thompson, Anthony Krier. Characterisation of Ga1-xInxSb quantum wells (x~0.3) grown on GaAs using AlGaSb interface misfit buffer[J]. AIMS Materials Science, 2015, 2(2): 86-96. doi: 10.3934/matersci.2015.2.86







 DownLoad:
DownLoad: