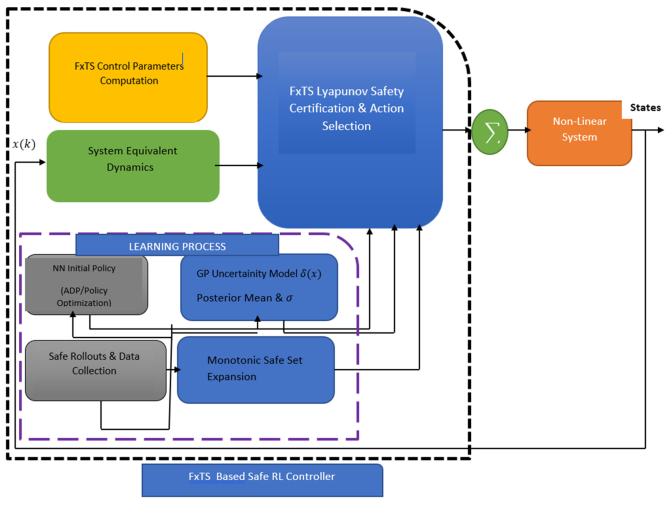
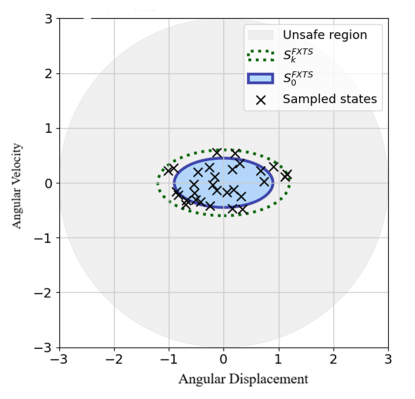
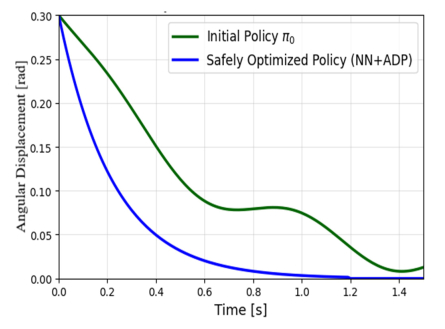
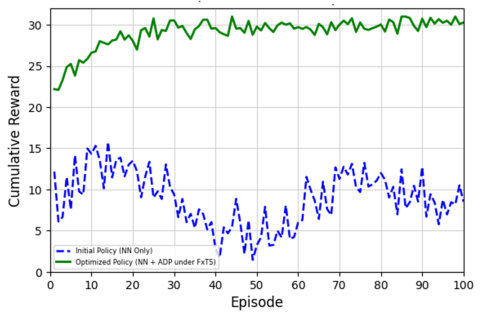
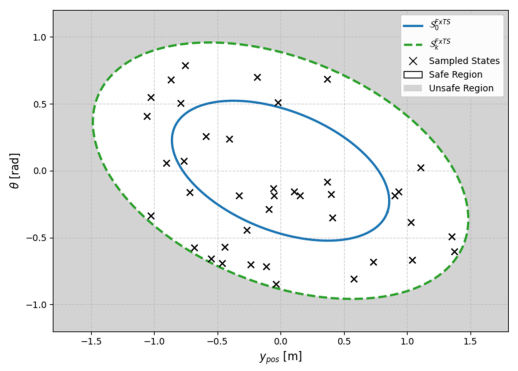
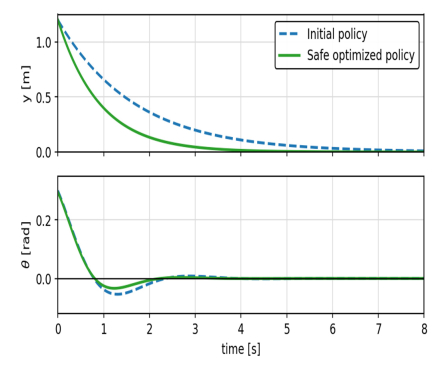
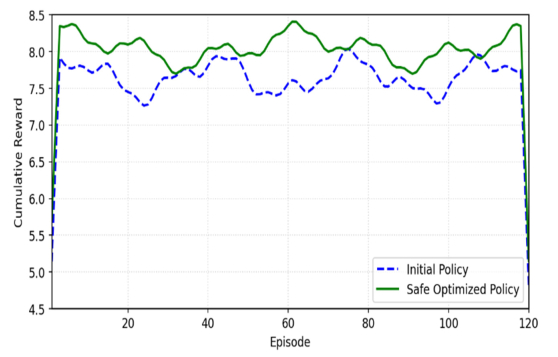
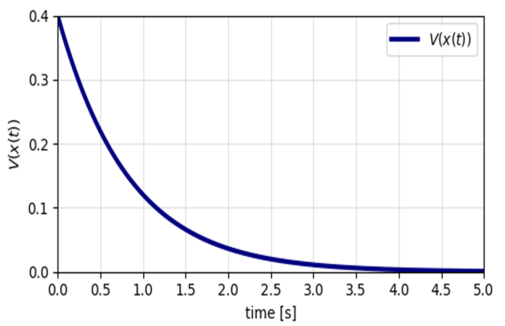
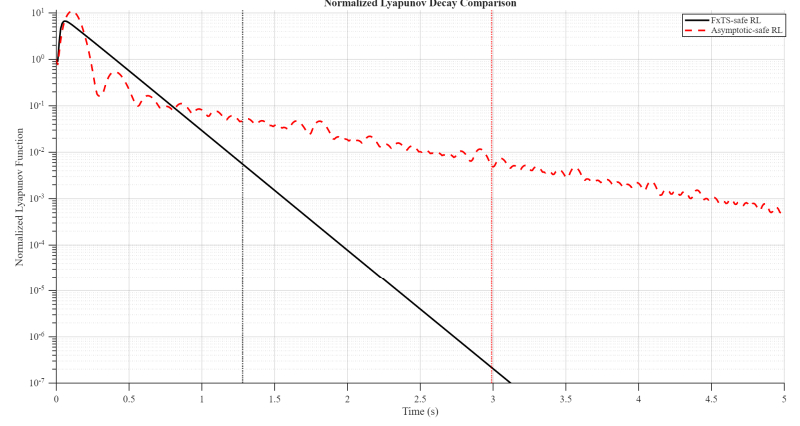
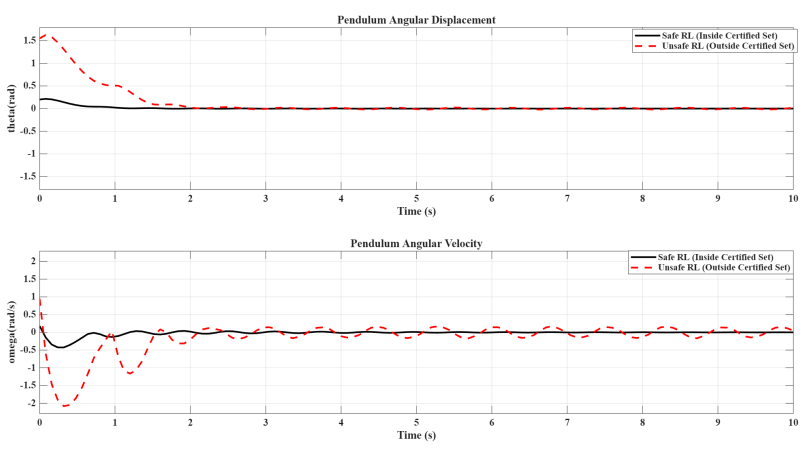
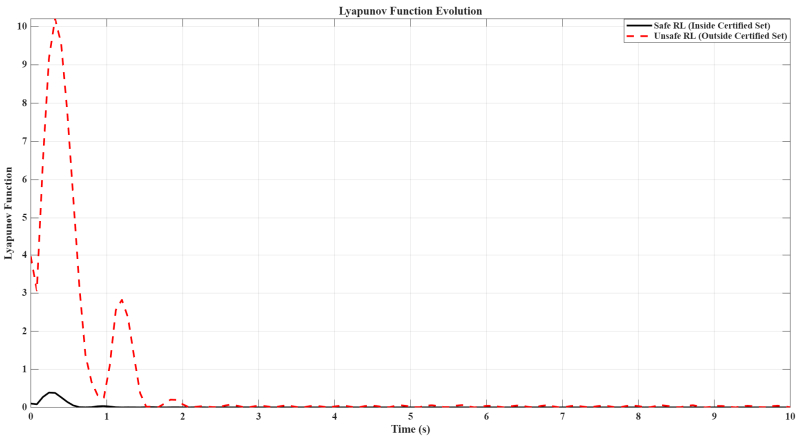
This paper presents novel safe reinforcement-learning-based, fixed-time control framework for a class of discrete time uncertain nonlinear systems which guarantees fixed-time stability (FxTS). This framework is developed to ensure fixed-time convergence for nonlinear systems in the absence of exact model. The main contribution is to present a unified framework by integration of fixed-time Lyapunov-based constraints and Gaussian process-based uncertainty modeling into the safe reinforcement learning loop in a manner that each candidate policy must ensure the fixed-time Lyapunov decrement condition within a uniform bounded convergence time in the entire learning process. The Lyapunov function for the nominal fixed-time stable closed loop system is used for enlarging the safe set for FxTS with accumulation of system data through refining the traditional Gaussian process model for uncertain system dynamics Gaussian process model is used to learn the unknown system dynamics online and to provide probabilistic confidence bounds. These bounds are directly incorporated into the fixed-time Lyapunov condition, leading to safety guarantees and monotonic expansion of the Lyapunov certified safe set. The control policy is then optimized for the enlarged safe set through exploration while ensuring FxTS. The proposed approach is validated through simulated results of inverted pendulum and reduced-order vehicle dynamic model for lateral vehicle dynamics. The validation for both nonlinear systems confirms fixed-time convergence, certified expansion of safe operating region, and improved control performance under safety and Lyapunov constraints.
Citation: Musayyab Ali, Fahad Mumtaz Malik, Naveed Mazhar, Nadia Sultan. Safe reinforcement learning for fixed-time stability of a class of nonlinear systems[J]. Electronic Research Archive, 2026, 34(5): 3193-3222. doi: 10.3934/era.2026144
This paper presents novel safe reinforcement-learning-based, fixed-time control framework for a class of discrete time uncertain nonlinear systems which guarantees fixed-time stability (FxTS). This framework is developed to ensure fixed-time convergence for nonlinear systems in the absence of exact model. The main contribution is to present a unified framework by integration of fixed-time Lyapunov-based constraints and Gaussian process-based uncertainty modeling into the safe reinforcement learning loop in a manner that each candidate policy must ensure the fixed-time Lyapunov decrement condition within a uniform bounded convergence time in the entire learning process. The Lyapunov function for the nominal fixed-time stable closed loop system is used for enlarging the safe set for FxTS with accumulation of system data through refining the traditional Gaussian process model for uncertain system dynamics Gaussian process model is used to learn the unknown system dynamics online and to provide probabilistic confidence bounds. These bounds are directly incorporated into the fixed-time Lyapunov condition, leading to safety guarantees and monotonic expansion of the Lyapunov certified safe set. The control policy is then optimized for the enlarged safe set through exploration while ensuring FxTS. The proposed approach is validated through simulated results of inverted pendulum and reduced-order vehicle dynamic model for lateral vehicle dynamics. The validation for both nonlinear systems confirms fixed-time convergence, certified expansion of safe operating region, and improved control performance under safety and Lyapunov constraints.

| [1] |
S. P. Bhat, D. S. Bernstein, Finite-time stability of continuous autonomous systems, SIAM J. Control Optim., 38 (2000), 751–766. https://doi.org/10.1137/S036301299732126X doi: 10.1137/S036301299732126X

|
| [2] |
C. Zhang, L. Chang, L. Xing, X. Zhang, Fixed-time stabilization of a class of strict-feedback nonlinear systems via dynamic gain feedback control, IEEE/CAA J. Autom. Sin., 10 (2023), 403–410. https://doi.org/10.1109/JAS.2023.123408 doi: 10.1109/JAS.2023.123408
|
| [3] |
W. M. Haddad, K. Verma, V. Chellaboina, Fixed-time stability, uniform strong dissipativity, and stability of nonlinear feedback systems, Mathematics, 13 (2025), 1377. https://doi.org/10.3390/math13091377 doi: 10.3390/math13091377
|
| [4] | K. Garg, D. Panagou, Robust control barrier and control Lyapunov functions with fixed-time convergence guarantees, in 2021 American Control Conference (ACC), (2021), 2292–2297. https://doi.org/10.23919/ACC50511.2021.9482751 |
| [5] |
A. Polyakov, Nonlinear feedback design for fixed-time stabilization of linear control systems, IEEE Ttrans. Autom. Control, 57 (2011), 2106–2110. https://doi.org/10.1109/TAC.2011.2179869 doi: 10.1109/TAC.2011.2179869
|
| [6] |
F. Tatari, H. Modares, Deterministic and stochastic fixed-time stability of discrete-time autonomous systems, IEEE/CAA J. Autom. Sin., 10 (2023), 945–956. https://doi.org/10.1109/JAS.2023.123405 doi: 10.1109/JAS.2023.123405
|
| [7] |
J. Lee, W. M. Haddad, Fixed-time stability and optimal stabilisation of discrete autonomous systems, Int. J. Control, 96 (2023), 2341–2355. https://doi.org/10.1080/00207179.2022.2092557 doi: 10.1080/00207179.2022.2092557
|
| [8] |
J. Gu, Y. Wang, A constrained reinforcement learning based approach for cooperative control of multi-UAV in dense obstacle environments, Sci. China Technol. Sci., 69 (2026), 1120601. https://doi.org/10.1007/s11431-025-3076-2 doi: 10.1007/s11431-025-3076-2
|
| [9] |
X. Liu, L. Zhao, J. Jin, A noise‐tolerant fuzzy‐type zeroing neural network for robust synchronization of chaotic systems, Concurrency Comput. Pract. Exp., 36 (2024), e8218. https://doi.org/10.1002/cpe.8218s doi: 10.1002/cpe.8218s
|
| [10] |
Q. Lu, X. Wu, J. She, F. Guo, L. Yu, Disturbance rejection for systems with uncertainties based on fixed-time equivalent-input-disturbance approach, IEEE/CAA J. Autom. Sin., 11 (2024), 2384–2395. https://doi.org/10.1109/JAS.2024.124650 doi: 10.1109/JAS.2024.124650
|
| [11] |
M. T. Vu, S. H. Kim, D. H. Pham, H. L. N. N. Thanh, V. H. Pham, M. Roohi, Adaptive dynamic programming-based intelligent finite-time flexible SMC for stabilizing fractional-order four-wing chaotic systems, Mathematics, 13 (2025), 2078. https://doi.org/10.3390/math13132078 doi: 10.3390/math13132078
|
| [12] |
M. T. Vu, V. T. Nguyen, Q. T. Do, W. Youn, T. H. Nguyen, Robust non-integer predictive control for wind turbine pitch angle regulation in full load regions using deep on-policy learning, Eng. Appl. Artif. Intell., 156 (2025), 111156. https://doi.org/10.1016/j.engappai.2025.111156 doi: 10.1016/j.engappai.2025.111156
|
| [13] |
M. T. Vu, D. H. Pham, V. T. Nguyen, Q. T. Do, A. K. Alanazi, T. H. Nguyen, Adaptive nonlinear integral-backstepping control for frequency stabilization in cyber-physical shipboard microgrids using double deep Q-learning, Eng. Appl. Artif. Intell., 160 (2025), 111943. https://doi.org/10.1016/j.engappai.2025.111943 doi: 10.1016/j.engappai.2025.111943
|
| [14] |
F. Xu, S. Feng, Y. Wang, J. Chang, C. Zhou, Efficient deep reinforcement learning with expert demonstrations for human-machine shared steering control under emergency obstacle avoidance conditions, IEEE Trans. Veh. Technol., 2025 (2025). https://doi.org/10.1109/TVT.2025.3629701 doi: 10.1109/TVT.2025.3629701
|
| [15] |
W. Yuan, J. Chen, S. Chen, D. Feng, Z. Hu, P. Li, et al., Transformer in reinforcement learning for decision-making: A survey, Front. Inf. Technol. Electronic Eng., 25 (2024), 763–790. https://doi.org/10.1631/FITEE.2300548 doi: 10.1631/FITEE.2300548
|
| [16] |
A. Dong, A. Starr, Y. Zhao, Neural network-based parametric system identification: A review, Int. J. Syst. Sci., 54 (2023), 2676–2688. https://doi.org/10.1080/00207721.2023.2241957 doi: 10.1080/00207721.2023.2241957
|
| [17] |
M. Forgione, D. Piga, Continuous-time system identification with neural networks: Model structures and fitting criteria, Eur. J. Control, 59 (2021), 69–81. https://doi.org/10.1016/j.ejcon.2021.01.008 doi: 10.1016/j.ejcon.2021.01.008
|
| [18] |
M. Forgione, D. Piga, DynoNet: A neural network architecture for learning dynamical systems, Int. J. Adapt. Control Signal Process., 35 (2021), 612–626. https://doi.org/10.1002/acs.3216 doi: 10.1002/acs.3216
|
| [19] |
C. Qin, X. Ran, D. Zhang, Unsupervised image stitching based on generative adversarial networks and feature frequency awareness algorithm, Appl. Soft Comput., 2025 (2025), 113466. https://doi.org/10.1016/j.asoc.2025.113466 doi: 10.1016/j.asoc.2025.113466
|
| [20] |
D. Zhang, X. Hao, L. Liang, W. Liu, C. Qin, A novel deep convolutional neural network algorithm for surface defect detection, J. Comput. Design Eng., 9 (2022), 1616–1632. https://doi.org/10.1093/jcde/qwac071 doi: 10.1093/jcde/qwac071
|
| [21] |
D. Zhang, X. Hao, D. Wang, C. Qin, B. Zhao, et al., An efficient lightweight convolutional neural network for industrial surface defect detection, Artif. Intell. Rev, 56 (2023), 10651–10677. https://doi.org/10.1007/s10462-023-10438-y doi: 10.1007/s10462-023-10438-y
|
| [22] |
D. Zhang, C. Yu, Z. Li, C. Qin, R. Xia, A lightweight network enhanced by attention-guided cross-scale interaction for underwater object detection, Appl. Soft Comput., 2025 (2025), 113811. https://doi.org/10.1016/j.asoc.2025.113811 doi: 10.1016/j.asoc.2025.113811
|
| [23] |
X. Song, D. Zheng, S. Song, V. Stojanovic, I. Tejado, Robust anti-disturbance interval type-2 fuzzy control for interconnected nonlinear PDE systems via conjunct observer, Math. Comput. Simul., 227 (2025), 149–167. https://doi.org/10.1016/j.matcom.2024.07.039 doi: 10.1016/j.matcom.2024.07.039
|
| [24] |
L. Gao, Z. Zhuang, H. Tao, Y. Chen, V. Stojanovic, Non-lifted norm optimal iterative learning control for networked dynamical systems: A computationally efficient approach, J. Franklin Inst., 361 (2024), 107112. https://doi.org/10.1016/j.jfranklin.2024.107112 doi: 10.1016/j.jfranklin.2024.107112
|
| [25] |
J. Fang, C. Ren, H. Wang, V. Stojanovic, S. He, Finite-region asynchronous H∞ filtering for 2-D Markov jump systems in Roesser model, Appl. Math. Comput, 470 (2024), 128573. https://doi.org/10.1016/j.amc.2024.128573 doi: 10.1016/j.amc.2024.128573
|
| [26] |
C. Qin, S. Hou, M. Pang, Z. Wang, D. Zhang, Reinforcement learning-based secure tracking control for nonlinear interconnected systems: An event-triggered solution approach, Eng. Appl. Artif. Intell., 161 (2025), 112243. https://doi.org/10.1016/j.engappai.2025.112243 doi: 10.1016/j.engappai.2025.112243
|
| [27] |
C. Qin, M. Pang, Z. Wang, S. Hou, D. Zhang, Observer based fault tolerant control design for saturated nonlinear systems with full state constraints via a novel event-triggered mechanism, Eng. Appl. Artif. Intell., 161 (2025), 112221. https://doi.org/10.1016/j.engappai.2025.112221 doi: 10.1016/j.engappai.2025.112221
|
| [28] |
C. Qin, X. Qiao, J. Wang, D. Zhang, Y. Hou, et al., Barrier-critic adaptive robust control of nonzero-sum differential games for uncertain nonlinear systems with state constraints, IEEE Trans. Syst. Man Cybern. Syst., 54 (2023), 50–63. https://doi.org/10.1109/TSMC.2023.3302656 doi: 10.1109/TSMC.2023.3302656
|
| [29] |
D. Zhang, Y. Wang, L. Meng, J. Yan, C. Qin, Adaptive critic design for safety-optimal FTC of unknown nonlinear systems with asymmetric constrained-input, ISA Trans., 155 (2024), 309–318. https://doi.org/10.1016/j.isatra.2024.09.018 doi: 10.1016/j.isatra.2024.09.018
|
| [30] |
D. Zhang, Q. Yuan, L. Meng, R. Xia, W. Liu, C. Qin, Reinforcement learning for single-agent to multi-agent systems: From basic theory to industrial application progress, a survey, Artif. Intell. Rev., 2025 (2025). https://doi.org/10.1007/s10462-025-11439-9 doi: 10.1007/s10462-025-11439-9
|
| [31] | G. Dalal, K. Dvijotham, M. Vecerik, T. Hester, C. Paduraru, Y. Tassa, Safe exploration in continuous action spaces, preprint, arXiv: 180108757. https://doi.org/10.48550/arXiv.1801.08757 |
| [32] |
S. Gu, L. Yang, Y. Du, G. Chen, F. Walter, J. Wang, et al., A review of safe reinforcement learning: Methods, theories and applications, IEEE Trans. Pattern Anal. Mach. Intell., 46 (2024), 11216–11235. https://doi.org/10.1109/TPAMI.2024.3457538 doi: 10.1109/TPAMI.2024.3457538
|
| [33] |
I. Salehi, T. Taplin, A. P. Dani, Learning discrete-time uncertain nonlinear systems with probabilistic safety and stability constraints, IEEE Open J. Control Syst., 1 (2022), 354–365. https://doi.org/10.1109/OJCSYS.2022.3216545 doi: 10.1109/OJCSYS.2022.3216545
|
| [34] | F. Berkenkamp, R. Moriconi, A. P. Schoellig, A. Krause, Safe learning of regions of attraction for uncertain, nonlinear systems with gaussian processes, in 2016 IEEE 55th Conference on Decision and Control (CDC), (2016), 4661–4666. https://doi.org/10.1109/CDC.2016.7798979 |
| [35] | J. Schreiter, D. Nguyen-Tuong, M. Eberts, B. Bischoff, H. Markert, M. Toussaint, Safe exploration for active learning with Gaussian processes, in Joint European Conference on Machine Learning and Knowledge Discovery in Databases, (2015), 133–149. https://doi.org/10.1007/978-3-319-23461-8_9 |
| [36] | J. Garcıa, F. Fernández, A comprehensive survey on safe reinforcement learning, J. Mach. Learn. Res., 16 (2015), 1437–1480. |
| [37] |
J. Baxter, P. L. Bartlett, Infinite-horizon policy-gradient estimation, J. Artif. Intell. Res., 15 (2001), 319–350. https://doi.org/10.1613/jair.806 doi: 10.1613/jair.806
|
| [38] |
Y. Wang, Z. Wu, Control lyapunov‐barrier function‐based safe reinforcement learning for nonlinear optimal control, AIChE J., 70 (2024), e18306. https://doi.org/10.1002/aic.18306 doi: 10.1002/aic.18306
|
| [39] |
A. Wachi, W. Hashimoto, X. Shen, K. Hashimoto, Safe exploration in reinforcement learning: A generalized formulation and algorithms, Adv. Neural Inf. Process. Syst., 36 (2023), 29252–29272. https://doi.org/10.52202/075280-1273 doi: 10.52202/075280-1273
|
| [40] | H. K. Khalil, J. W. Grizzle, Nonlinear Systems, Prentice Hall Upper Saddle River, NJ. |
| [41] | F. Berkenkamp, M. Turchetta, A. Schoellig, A. Krause, Safe model-based reinforcement learning withstability guarantees, Adv. Neural Inf. Process. Syst., 30 (2017). |
| [42] | Y. Chow, O. Nachum, E. Duenez-Guzman, M. Ghavamzadeh, A lyapunov-based approach to safe reinforcement learning, Adv. Neural Inf. Process. Syst., 31 (2018). |
| [43] | L. Manda, S. Chen, M. Fazlyab, Learning performance-oriented control barrier functions under complex safety constraints and limited actuation, preprint, arXiv: 240105629. https://doi.org/10.48550/arXiv.2401.05629 |
| [44] | R. Munos, T. Stepleton, A. Harutyunyan, M. Bellemare, Safe and efficient off-policy reinforcement learning, Adv. Neural Inf. Process. Syst., 29 (2016). |
| [45] | D. Bertsekas, Dynamic Programming and Optimal Control: Volume I, Athena Scientific, 2012. |
Figures(19) / Tables(2)
Musayyab Ali, Fahad Mumtaz Malik, Naveed Mazhar, Nadia Sultan. Safe reinforcement learning for fixed-time stability of a class of nonlinear systems[J]. Electronic Research Archive, 2026, 34(5): 3193-3222. doi: 10.3934/era.2026144







 DownLoad:
DownLoad: