Citation: Oleg S. Sukharev. The restructuring of the investment portfolio: the risk and effect of the emergence of new combinations[J]. Quantitative Finance and Economics, 2019, 3(2): 390-411. doi: 10.3934/QFE.2019.2.390

| [1] |
Adami C, Schossau J, Hintze A (2016) Evolutionary game theory using agent-based methods. Phys Life Rev 19: 1–26. doi: 10.1016/j.plrev.2016.08.015

|
| [2] |
Babu S, Mohan U (2018) An integrated approach to evaluating sustainability in supply chains using evolutionary game theory. Comput Oper Res 89: 269–283. doi: 10.1016/j.cor.2017.01.008
|
| [3] |
Barnes B, Giannini F, Arthur A, et al. (2019) Optimal allocation of limited resources to biosecurity surveillance using a portfolio theory methodology. Ecol Econ 161: 153–162. doi: 10.1016/j.ecolecon.2019.03.012
|
| [4] | Bowles S (2006) Microeconomics: Behavior, Institutions, and Evolution, Princeton University Press, Princeton, NJ, 608. |
| [5] |
Brainard WC, Tobin J (1992) On the Internationalization of Portfolios. Oxford Econ Pap 44: 533–565. doi: 10.1093/oxfordjournals.oep.a042065
|
| [6] |
Byers SS, Groth JC, Sakao T (2015) Using portfolio theory to improve resource efficiency of invested capital. J Cleaner Prod 98: 156–165. doi: 10.1016/j.jclepro.2013.11.014
|
| [7] | Elsner W, Heinrich T, Schwardt H (2015) Tools II: More Formal Concepts of Game Theory and Evolutionary Game Theory, The Microeconomics of Complex Economies, 193–226. |
| [8] |
Guerard JB, Markowitz H, Xu G (2015) Earnings forecasting in a global stock selection model and efficient portfolio construction and management. Int J Forecasting 31: 550–560. doi: 10.1016/j.ijforecast.2014.10.003
|
| [9] | Hanusch H, Chakraborty L, Khurana S (2017) Fiscal Policy Economic Growth and Innovation: An Empirical Analysis of G20 Countries. Levy Economics Institute, Working Paper, No. 883, 16. |
| [10] | Hanusch H, Pyka A (2017) Principles of Neo-Schumpeterian Economics. Cambridge J Econ 31: 275–289. |
| [11] | Herbert G (2009) The Bounds of Reason: Game Theory and the Unification of the Behavioral Sciences, Princeton, NJ: Princeton University Press. |
| [12] | Lhabitant FS (2017) Portfolio Diversification, ISTE Press, Elsevier, 274. |
| [13] |
Li J-C, Mei D-C (2014) The returns and risks of investment portfolio in a financial market. Phy A 406: 67–72. doi: 10.1016/j.physa.2014.03.005
|
| [14] | Markowitz H, Dijk E (2008) Risk-return analysis, Handb Asset Liab Manage 1: 139–197. |
| [15] | Markowitz H (1952) Portfolio Selection. J Financ 7: 77–91. |
| [16] |
Markowitz H (1991) Individual versus institutional investing. Financ Serv Rev 1: 1–8. doi: 10.1016/1057-0810(91)90003-H
|
| [17] |
Matthies BD, Jacobsen JB, Knoke T, et al. (2019) Utilising portfolio theory in environmental research-New perspectives and considerations. J Environ Manage 231: 926–939. doi: 10.1016/j.jenvman.2018.10.049
|
| [18] |
Nkeki CI (2018) Optimal investment risks and debt management with backup security in a financial crisis. J Comput Appl Math 338: 129–152. doi: 10.1016/j.cam.2018.01.032
|
| [19] |
Ozkan-Canbolat E, Beraha A, Bas A (2016) Application of Evolutionary Game Theory to Strategic Innovation. Proc-Soc Behav Sci 235: 685–693. doi: 10.1016/j.sbspro.2016.11.069
|
| [20] |
Paut R, Sabatier R, Tchamitchian M (2019) Reducing risk through crop diversification: An application of portfolio theory to diversified horticultural systems. Agric Sys 168: 123–130. doi: 10.1016/j.agsy.2018.11.002
|
| [21] | Ravindran A, Ragsdell KM, Reklaitis GV (1983) Engineering optimization: methods and application, New York: Wiley, 681. |
| [22] |
Sachse K, Jungermann H, Belting JM (2012) Investment risk-The perspective of individual investors. J Econ Psychol 33: 437–447. doi: 10.1016/j.joep.2011.12.006
|
| [23] |
Saviotti PP, Pyka A, Jun B (2016) Education, structural change and economic development. Struct Change Econ Dyn 38: 55–68. doi: 10.1016/j.strueco.2016.04.002
|
| [24] | Schumpeter JA (2008) The Theory of Economic Development: An Inquiry into Profits, Capital, Credit, Interest and the Business Cycle, New Brunswick (U.S.A) and London (U.K.): Transaction Publishers, 267 . |
| [25] | Serletis A (2001) Portfolio Theories of Money Demand, In: The Demand for Money, Springer, Boston, MA, 113–121. |
| [26] | Sharpe WF (1970) Portfolio theory and capital markets, McGraw-Hill, 316. |
| [27] | Sharpe W, Gordon JA, Bailey JW (1998) Investments, Prentice Hall, 962. |
| [28] | Shinzato T (2018) Maximizing and minimizing investment concentration with constraints of budget and investment risk, Phy A 490: 986–993. |
| [29] | Sohrabi MK, Azgomi H (2019) Evolutionary game theory approach to materialized view selection in data warehouses. Know-Based Syst 163: 558–571. |
| [30] | Tobin J, Hester D (1967) Studies of portfolio behavior, Cowles Foundation monograph, No. 20; New York et al.: J. Wiley and Sons. 268. |
| [31] |
Wang H, Liang P, Li H, et al. (2016) Financing Sources, R&D Investment and Enterprise Risk. Proc Comput Sci 91: 122–130. doi: 10.1016/j.procs.2016.07.049
|
| [32] |
Way R, Lafond F, Lillo F, et al. (2019) Wright meets Markowitz: How standard portfolio theory changes when assets are technologies following experience curves. J Econ Dyn Control 101: 211–238. doi: 10.1016/j.jedc.2018.10.006
|
| [33] |
Yi Z, Xin-gang Z, Yu-zhuo Z, et al. (2019) From feed-in tariff to renewable portfolio standards: An evolutionary game theory perspective. J Clea Prod 213: 1274–1289. doi: 10.1016/j.jclepro.2018.12.170
|
| [34] | Zhang S, Zhao T, Xie BC (2018) What is the optimal power generation mix of China? An empirical analysis using portfolio theory. Appl Energy 229: 522–536. |
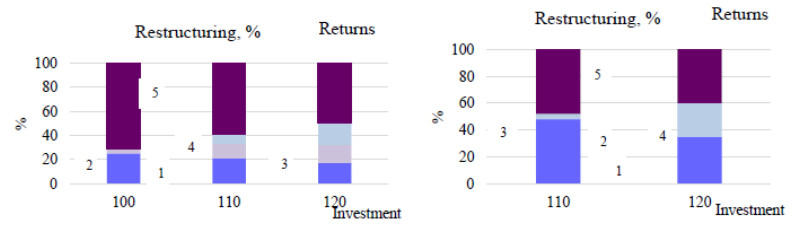
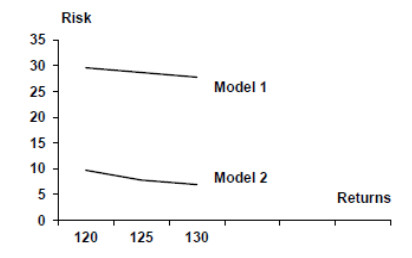
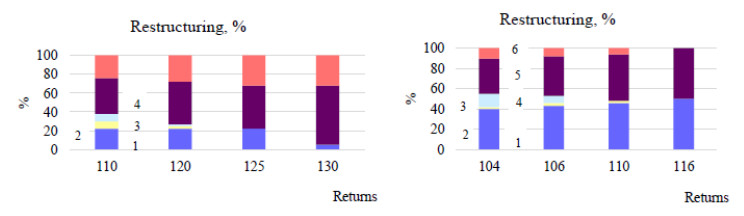
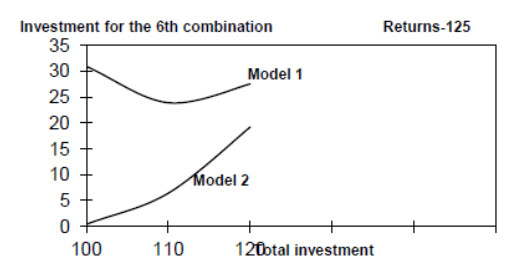
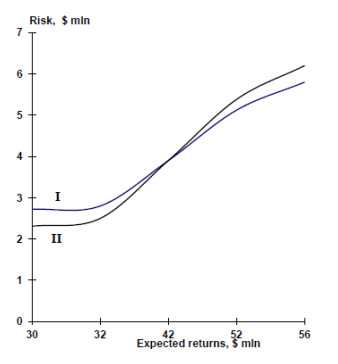
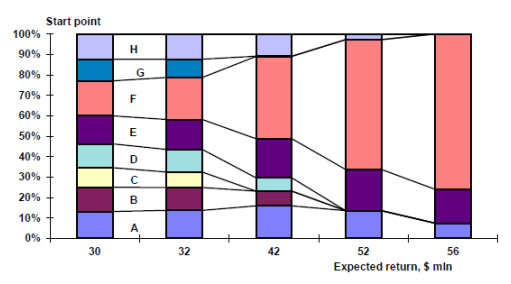
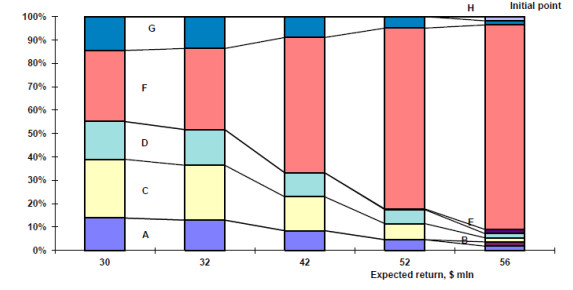
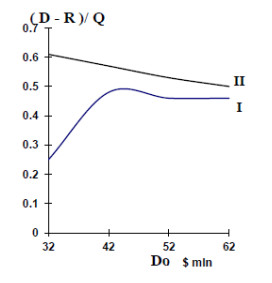
Figures(16) / Tables(4)

Oleg S. Sukharev. The restructuring of the investment portfolio: the risk and effect of the emergence of new combinations[J]. Quantitative Finance and Economics, 2019, 3(2): 390-411. doi: 10.3934/QFE.2019.2.390







 DownLoad:
DownLoad: