Citation: Francesco Audrino, Lorenzo Camponovo, Constantin Roth. Wild multiplicative bootstrap for M and GMM estimators in time series[J]. Quantitative Finance and Economics, 2019, 3(1): 165-186. doi: 10.3934/QFE.2019.1.165

| [1] |
Allen J, Gregory AW, Shimotsu K (2011) Empirical likelihood block bootstrapping. J Econom 161: 110-121. doi: 10.1016/j.jeconom.2010.10.003

|
| [2] | Altonji JG, Segal LM (1996) Small-sample bias in GMM estimation of covariance structures. J Bus Econ Stat 14: 353-366. |
| [3] | Andrews DWK(1991) Heteroskedasticity and autocorrelation consistent covariance matrix estimation. Econometrica 59: 817-858. |
| [4] |
Andrews DWK (2002) Higher-order improvements of a computationally attractive k-step bootstrap for extremum estimators. Econometrica 70: 119-162. doi: 10.1111/1468-0262.00271
|
| [5] |
Bollerslev T, Tauchen G, Zhou H (2009) Expected stock returns and variance risk premia. Rev Financ Stud 22: 4463-4492. doi: 10.1093/rfs/hhp008
|
| [6] |
Bücher A, Kojadinovic I (2016) A dependent multiplier bootstrap for the sequential empirical copula process under strong mixing. Bernoulli 22: 927-968. doi: 10.3150/14-BEJ682
|
| [7] | Campbell JY, Shiller RJ (1988) The dividend ratio model and small sample bias: a Monte Carlo study. Econ Lett 29: 325-331. |
| [8] |
Campbell JY, Yogo M (2006) Efficient tests of stock return predictability. J Financ Econ 81: 27-60. doi: 10.1016/j.jfineco.2005.05.008
|
| [9] |
Camponovo L, Scaillet O, Trojani F (2012) Robust subsampling. J Econom 167: 197-210. doi: 10.1016/j.jeconom.2011.11.005
|
| [10] | Camponovo L, Scaillet O, Trojani F (2015) Predictability hidden by anomalous observations. Working paper. |
| [11] |
Carlstein E (1986) The use of subseries methods for estimating the variance of a general statistic from a stationary time series. Ann Stat 14: 1171-1179. doi: 10.1214/aos/1176350057
|
| [12] | Chernozhukov V, Chetverikov D, Kato K (2014) Central limit theorems and multiplier bootstrap when p is much larger than n. Ann Stat, In press. |
| [13] | Davidson J (1994) Stochastic Limit Theory, Oxford University Press, Oxford. |
| [14] |
De Jong RM, Davidson J (2000) Consistency of kernel estimators of heteroscedastic and autocorrelated covariance matrices. Econometrica 68: 407-424. doi: 10.1111/1468-0262.00115
|
| [15] |
Fama E, French K (1988) Dividend yields and expected stock returns. J Financ Econ 22: 3-25. doi: 10.1016/0304-405X(88)90020-7
|
| [16] |
Geyer C (1994) On the asymptotics of constrained M-estimation. Ann Stat 22: 1993-2010. doi: 10.1214/aos/1176325768
|
| [17] |
Goncalves S, White H (2004) Maximum likelihood and the bootstrap for nonlinear dynamic models. J Econom 119: 199-219. doi: 10.1016/S0304-4076(03)00204-5
|
| [18] |
Götze F, Künsch HR (1996) Second-order correctness of the blockwise bootstrap for stationary observations. Ann Stat 24: 1914-1933. doi: 10.1214/aos/1069362303
|
| [19] |
Hall P (1985) Resampling a coverage process. Stoch Process Their Appl 19: 259-269. doi: 10.1016/0304-4149(85)90028-6
|
| [20] | Hall AR (2005) Generalized Method of Moments, Oxford University Press, Oxford. |
| [21] |
Hall P, Horowitz J (1996) Bootstrap critical values for tests based on Generalized- Method-of-Moment estimators. Econometrica 64: 891-916. doi: 10.2307/2171849
|
| [22] |
Hall P, Horowitz JL, Jing BY (1995) On blocking rules for the bootstrap with dependent data. Biometrika 82: 561-574. doi: 10.1093/biomet/82.3.561
|
| [23] |
Hansen LP (1982) Large sample properties of generalized method of moments estimators. Econometrica 50: 1029-1054. doi: 10.2307/1912775
|
| [24] |
Huber PJ (1964) Robust estimation of a location parameter. Ann Math Stat 35: 73-101. doi: 10.1214/aoms/1177703732
|
| [25] |
Politis DN, Romano JP (1992) A general resampling scheme for triangular arrays of α-mixing random variables with application to the problem of spectral density estimation. Ann Stat 20: 1985-2007. doi: 10.1214/aos/1176348899
|
| [26] | Politis DN, Romano JP (1992) The stationary bootstrap. J Am Stat Assoc 89: 1303-1313. |
| [27] |
Inoue A, Shintani M (2006) Bootstrapping GMM estimators for time series. J Econom 133: 531-555. doi: 10.1016/j.jeconom.2005.06.004
|
| [28] | Kline P, Santos A (2012) A score based approach to wild bootstrap inference. J Econom Method 1: 23-41. |
| [29] |
Künsch H (1989) The jacknife and the bootstrap for general stationary observations. Ann Stat 17: 1217-1241. doi: 10.1214/aos/1176347265
|
| [30] |
Jansson M, Moreira MJ (2006) Optimal inference in regression models with nearly integrated regressors. Econometrica 74: 681-714. doi: 10.1111/j.1468-0262.2006.00679.x
|
| [31] |
Lahiri S (1996) Edgeworth expansion and moving block bootstrap for studentized M-estimators in multiple linear regression models. J Multivar Anal 56: 42-59. doi: 10.1006/jmva.1996.0003
|
| [32] |
Lazarus E, Lewis DJ, Stock JH, et al. (2018) HAR inference: recommendations for practice rejoinder. J Bus Econ Stat 36: 541-559. doi: 10.1080/07350015.2018.1506926
|
| [33] |
Minnier J, Tian L, Cai T (2011) A perturbation method for inference on regularized regression estimates. J Ame Stat Assoc 106: 1371-1382. doi: 10.1198/jasa.2011.tm10382
|
| [34] |
Müller U (2014) HAC corrections for strongly autocorrelated time series. J Bus Econ Stat 32: 311-322. doi: 10.1080/07350015.2014.931238
|
| [35] |
Nelson CR, Kim MJ (1993) Predictable stock returns: the role of small sample bias. J Financ 48: 641-661. doi: 10.1111/j.1540-6261.1993.tb04731.x
|
| [36] |
Newey WK, West KD (1987) A simple, positive semi-definite, heteroskedasticity and autocorrelation consistent covariance matrix. Econometrica 55: 703-708. doi: 10.2307/1913610
|
| [37] |
Polk C, Thompson S, Vuolteenaho T (2006) Cross-sectional forecast of the equity premium. J Financ Econ 81: 101-141. doi: 10.1016/j.jfineco.2005.03.013
|
| [38] |
Rozeff M (1984) Dividend yields are equity risk premium. J Portf Manage 11: 68-75. doi: 10.3905/jpm.1984.408980
|
| [39] | Salibian-Barrera M, Zamar R (2002) Boostrapping robust estimates of regression. Dividend yields are equity risk premium. Ann Stat 30: 556-582. |
| [40] |
Shao X (2010) The dependent wild bootstrap. J Am Stat Assoc 105: 218-235. doi: 10.1198/jasa.2009.tm08744
|
| [41] | Shiller RJ (2000) . Princeton The dependent wild bootstrap, University Press, Princeton, NJ. |
| [42] | Singh K (1998) Breakdown theory for bootstrap quantiles. Ann Stat 26: 1719-1732. |
| [43] |
Zhu K (2016) Breakdown Bootstrapping the portmanteau tests in weak autoregressive moving average models. J Royal Stat Soc 78: 463-485. doi: 10.1111/rssb.12112
|
| [44] | Zhu K (2019) Statistical inference for autoregressive models under heteroskedasticity of unknown form. Ann Stat, In press. |
| [45] |
Zhu K, Li WK (2015) A bootstrapped spectral test for adequacy in weak ARMA models. J Econom 187: 113-130. doi: 10.1016/j.jeconom.2015.02.005
|
| [46] |
Zhu K, Ling S (2015) LADE-based inference for ARMA models with unspecified and heavy-tailed heteroskedastic noises. J Am Stat Assoc 110: 784-794. doi: 10.1080/01621459.2014.977386
|
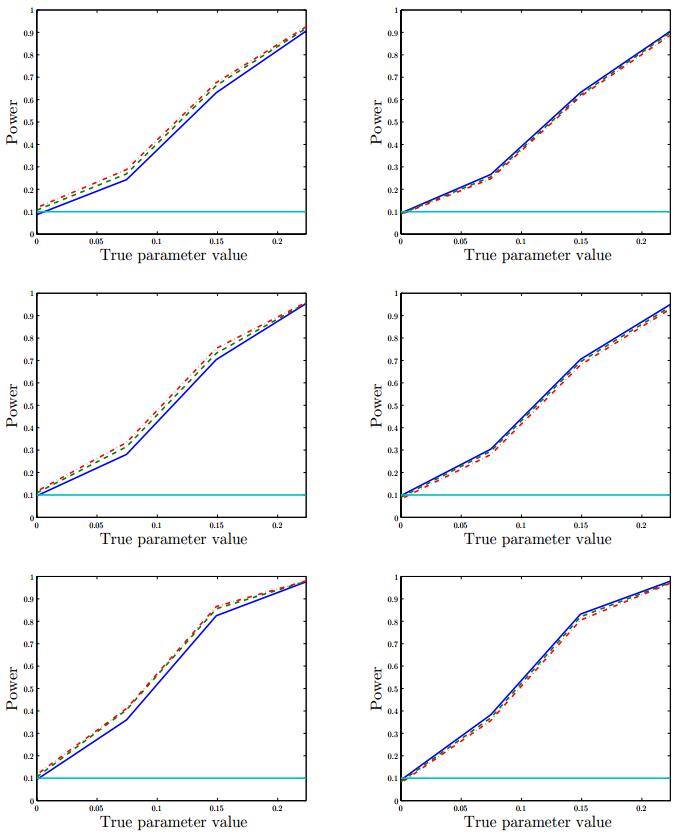
Figures(1) / Tables(5)

Francesco Audrino, Lorenzo Camponovo, Constantin Roth. Wild multiplicative bootstrap for M and GMM estimators in time series[J]. Quantitative Finance and Economics, 2019, 3(1): 165-186. doi: 10.3934/QFE.2019.1.165







 DownLoad:
DownLoad: