Citation: Andres Fernandez, Norman R. Swanson. Further Evidence on the Usefulness of Real-Time Datasets for Economic Forecasting[J]. Quantitative Finance and Economics, 2017, 1(1): 2-25. doi: 10.3934/QFE.2017.1.2

| [1] | Amato J, Swanson NR (2001) The Real-Time Predictive Content of Money for Output. J Monet Econ 48: 324. |
| [2] | Aruoba SB (2008) Real-Time Measurement of Business Conditions. J Bus Econ Stat, forthcom. |
| [3] |
Aruoba SB, Diebold FX, Scotti C (2008) Data Revisions are not Well-Behaved. J Money, Credit and Banking 40: 319-340. doi: 10.1111/j.1538-4616.2008.00115.x

|
| [4] | Ashley R, Granger, Schmalensee R (1980) Advertising and Aggregate Consumption: An Analysis of Causality, Econometrica. 48: 1149-1167. |
| [5] | Bernanke BS, Boivin J (2003) Monetary Policy in a Data-Rich Environment, J Monet Econ 50: 525546. |
| [6] | Chao J, Corradi V, Swanson NR (2001) An out-of-sample Test for Granger Causality, Macroeconomic Dynamics 5: 598-620. |
| [7] | Clark TE, McCrackenMW(2001) Tests of Equal Forecast Accuracy and Encompassing for Nested Models. J Econ 105: 85-110. |
| [8] |
Clark TE, McCracken MW (2005) Evaluating Direct Multistep Forecasts. Econ Reviews 24: 369-404. doi: 10.1080/07474930500405683
|
| [9] | Clark TE, McCracken MW (2009) Tests of Equal Predictive Ability with Real-Time Data. J Business & Economic Stat 27: 441-454. |
| [10] |
Corradi V, Swanson NR (2002) A Consistent Test for Out of Sample Nonlinear Predictive Ability. J Econ 110:353-381. doi: 10.1016/S0304-4076(02)00099-4
|
| [11] | Corradi VA, Fernandez, Swanson NR (2009) Information in the Revision Process of Real-Time Datasets. J Business & Economic Stat 27: 455-467. |
| [12] | Corradi V, Swanson NR (2006) Predictive Density Evaluation, in: Handbook of Economic Forecasting, eds. Clive W.J. Granger, Graham Elliot and Allan Timmermann, Elsevier, Amsterdam, 197-284. |
| [13] | Croushore D (2006) Forecasting with Real-Time Macroeconomic Data, in: Handbook of Economic Forecasting, eds. CliveW.J. Granger, Graham Elliot and Allan Timmermann, Elsevier, Amsterdam, 961982. |
| [14] | Croushore D, Stark T (2001) A Real-Time Dataset for Macroeconomists. J Econ 105: 111130. |
| [15] | Croushore D, Stark T (2003) A Real-Time Dataset for Macroeconomists: Does Data Vintage Matter? Rev Econ and Stat 85: 605617. |
| [16] | Diebold FX, Mariano RS (1995) Comparing Predictive Accuracy. J Business and Economic Stat 13: 253-263. |
| [17] | Diebold FX, Rudebusch GD (1991) Forecasting Output with the Composite Leading Index: A Real-Time Analysis. J American Stat Assoc 86: 603610. |
| [18] | Faust J, Wright J (2009) Comparing Greenbook and Reduced Form Forecasts using a Large Realtime Dataset. J Business & Economic Stat. |
| [19] |
Franses PH (2013) Data Revisions and Periodic Properties of Macroeconomic Data. Econ Letters 120: 139-141. doi: 10.1016/j.econlet.2013.04.014
|
| [20] | Franses PH, Segers R (2010) Seasonality in Revisions in Macroeconomic Data. J O cial Stat 26: 361-369. |
| [21] | Gallo GM, Marcellino M (1999) Ex Post and Ex Ante Analysis of Provisional Data. J Forec 18: 421433. |
| [22] |
Garratt A, Koop G, Mise E, et al. (2009) Real-Time Prediction with UK Monetary Aggregates in the Presence of Model Uncertainty. J Business and Economic Stat 27: 480-491. doi: 10.1198/jbes.2009.07208
|
| [23] | Ghysels E, Swanson NR, Callan M (2002), Monetary Policy Rules with Model and Data Uncertainty. Southern Econ J 69, 239-265. |
| [24] | Gilbert T (2011), Information Aggregation Around Macroeconomic Announcements: Revisions Matter. J Financial Econ 101: 114-131. |
| [25] | Hamilton JD, Perez-Quiros G (1996) What Do the Leading Indicators Lead? J Business 69: 2749. |
| [26] | Kavajecz KA, Collins S (1995) Rationality of Preliminary Money Stock Estimates. Rev Econ and Stat 77: 3241. |
| [27] | Keane MP, Runkle DE (1990) Testing the Rationality of Price Forecasts: New Evidence from Panel Data. American Econ Rev 80: 714735. |
| [28] | Mankiw NG, Runkle DE, Shapiro MD(1984) Are Preliminary Announcements of the Money Stock Rational Forecasts? J Monetary Econ 14: 1527. |
| [29] | Mankiw NG, Shapiro MD (1986) News or Noise: an Analysis of GNP Revisions. Surv of Current Bus 66: 2025. |
| [30] | Mariano RS, Tanizaki H (1995) Prediction of Final Data with Use of Preliminary and/or Revised Data. J Forec 14: 351380. |
| [31] | Mork KA (1987) Aint Behavin: Forecast Errors and Measurement Errors in Early GNP Estimates. J Business & Economic Stat 5: 165175. |
| [32] |
Rathjens P, Robins RP (1995) Do Government Agencies Use Public Data: the Case of GNP. Rev Econ and Stat 77: 170-172. doi: 10.2307/2110002
|
| [33] | Robertson JC, Tallman EW (1998) Data Vintages and Measuring Forecast Performance, Federal Reserve Bank of Atlanta Economic Review 83 (Fourth Quarter), 420. |
| [34] |
Stock JH, Watson MW (1989) Interpreting the Evidence on Money-Income Causality. J Econ 40: 161-181. doi: 10.1016/0304-4076(89)90035-3
|
| [35] | Swanson NR, Ghysels E, Callan M (1999) A Multivariate Time Series Analysis of the Data Revision Process for Industrial Production and the Composite Leading Indicator, in R.F. Engle and H. White, eds., Cointegration, Causality, and Forecasting: A Festschrift in Honour of Clive W.J. Granger, Oxford: Oxford University Press, 45-75. |
| [36] | Swanson NR, Dijk D(2006) Are Statistical Reporting Agencies Getting It Right? Data Rationality and Business Cycle Asymmetry. J Business & Economic Stat 24: 2442. |
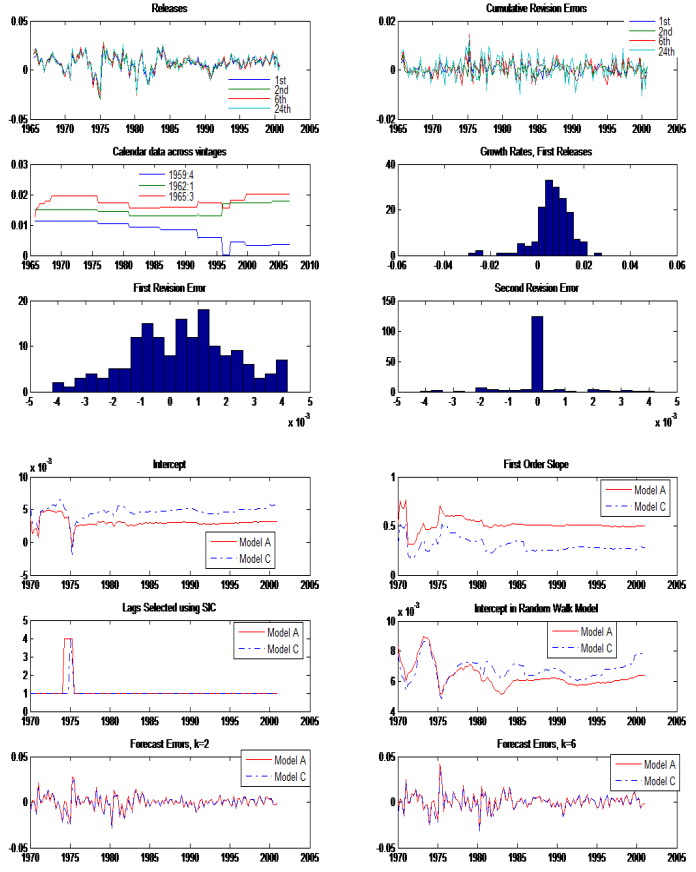
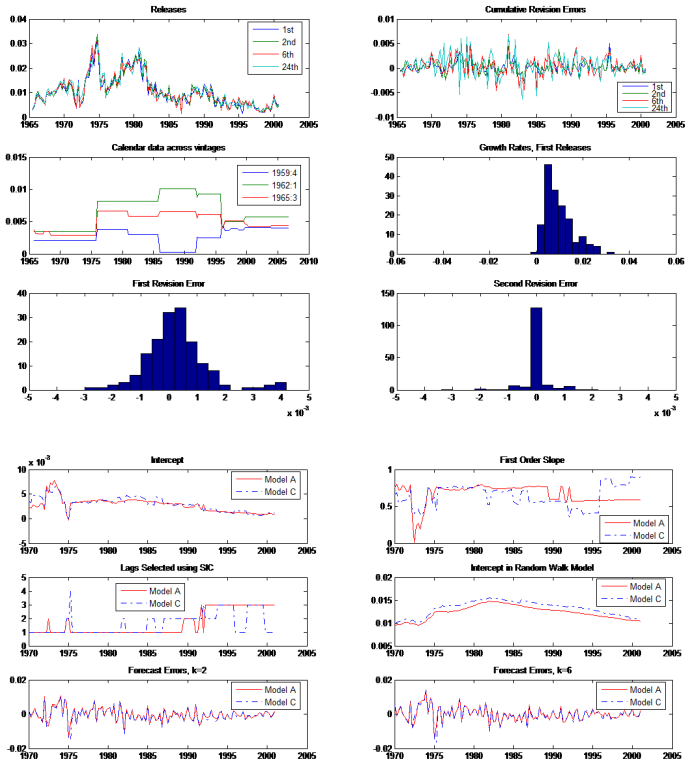
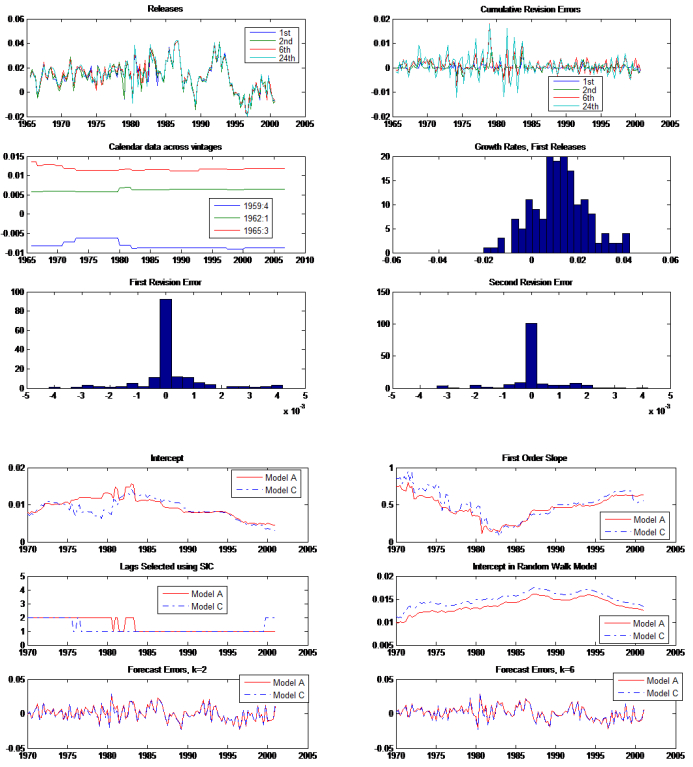
Figures(3) / Tables(8)

Andres Fernandez, Norman R. Swanson. Further Evidence on the Usefulness of Real-Time Datasets for Economic Forecasting[J]. Quantitative Finance and Economics, 2017, 1(1): 2-25. doi: 10.3934/QFE.2017.1.2







 DownLoad:
DownLoad: