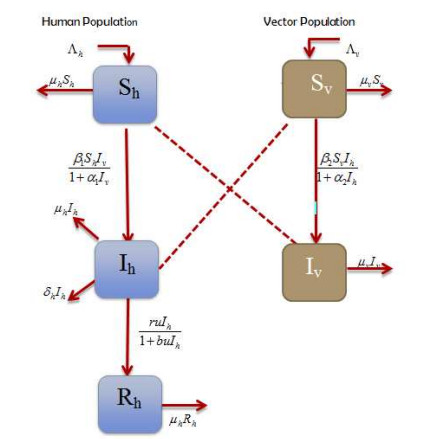
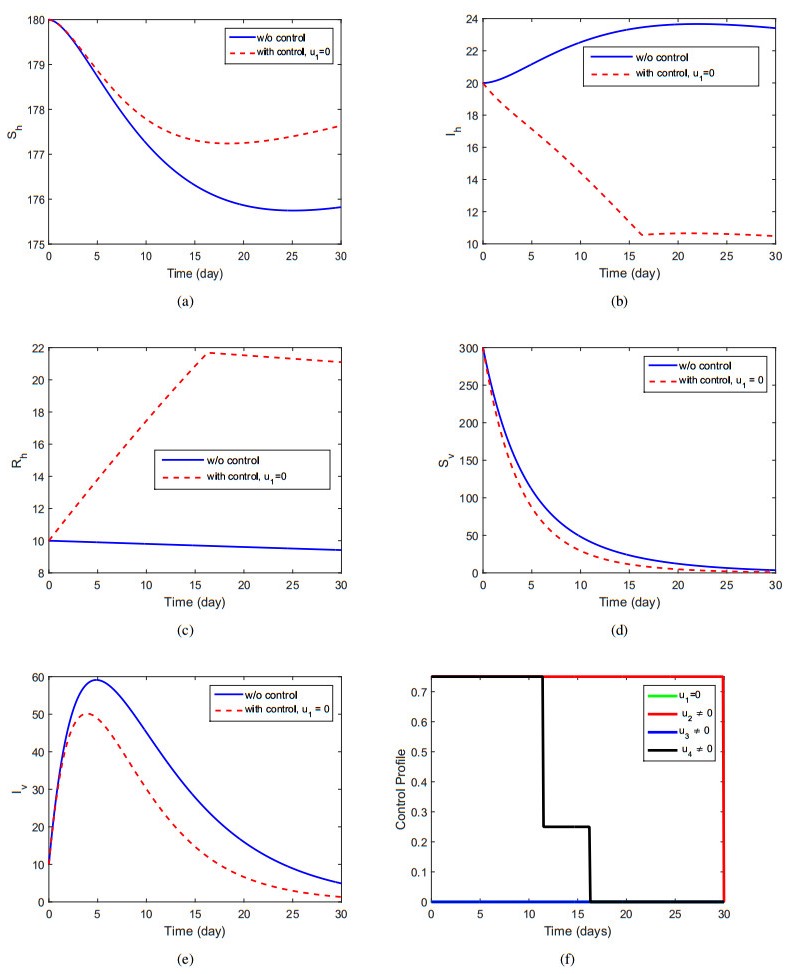
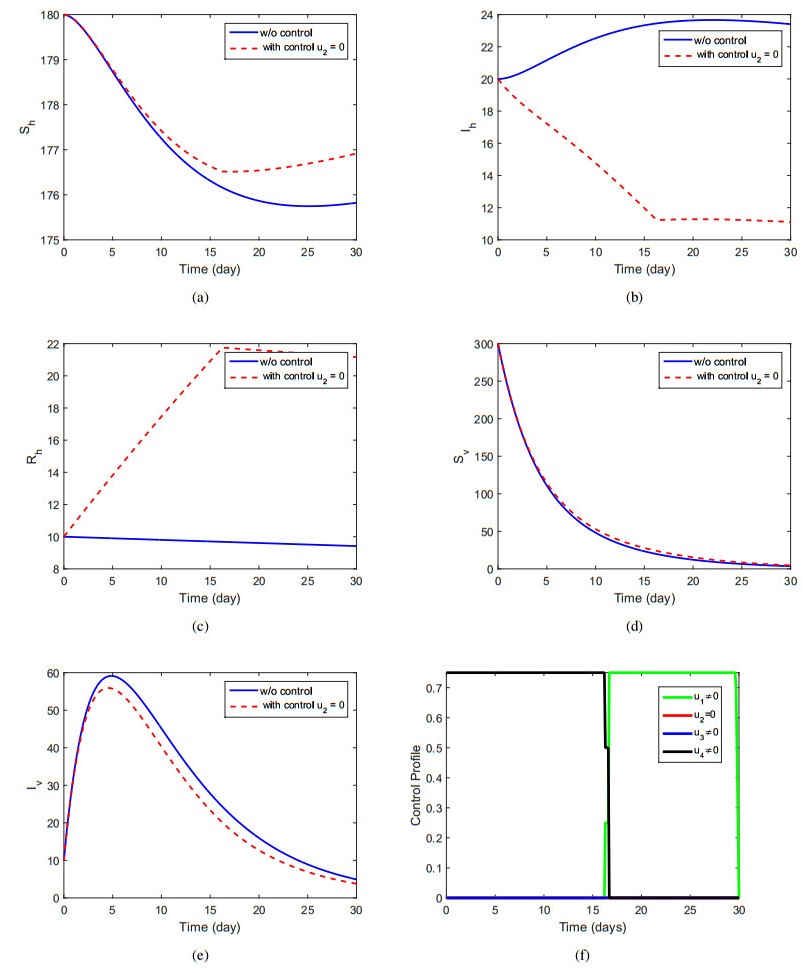
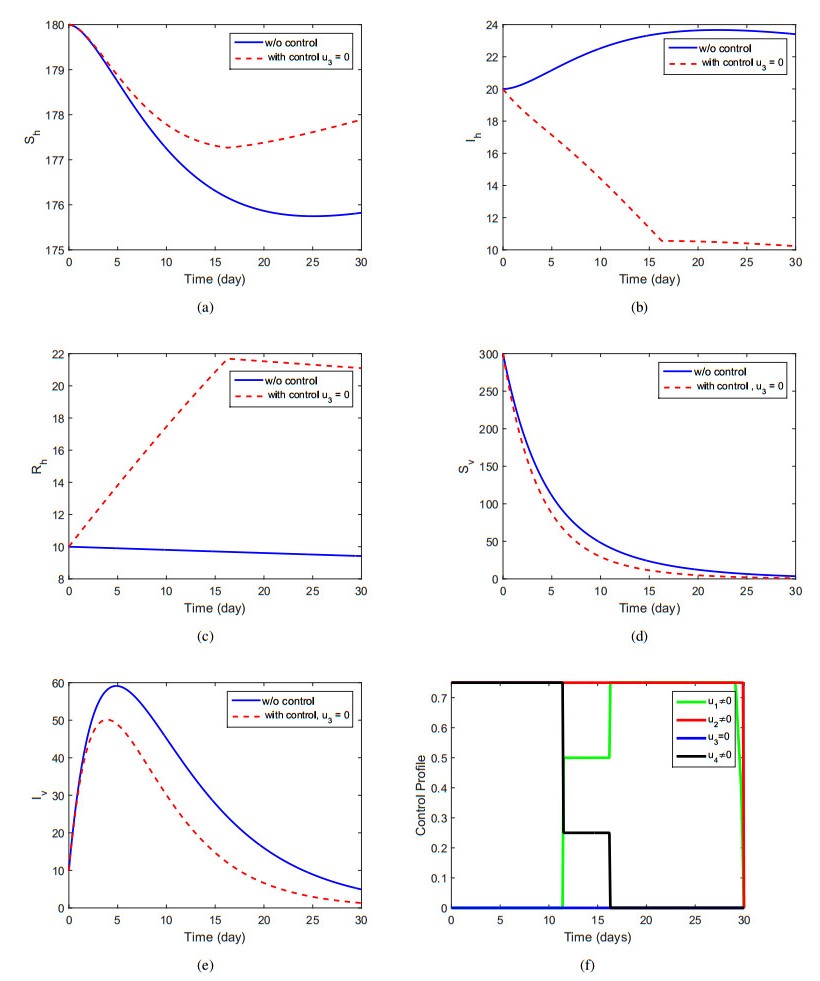
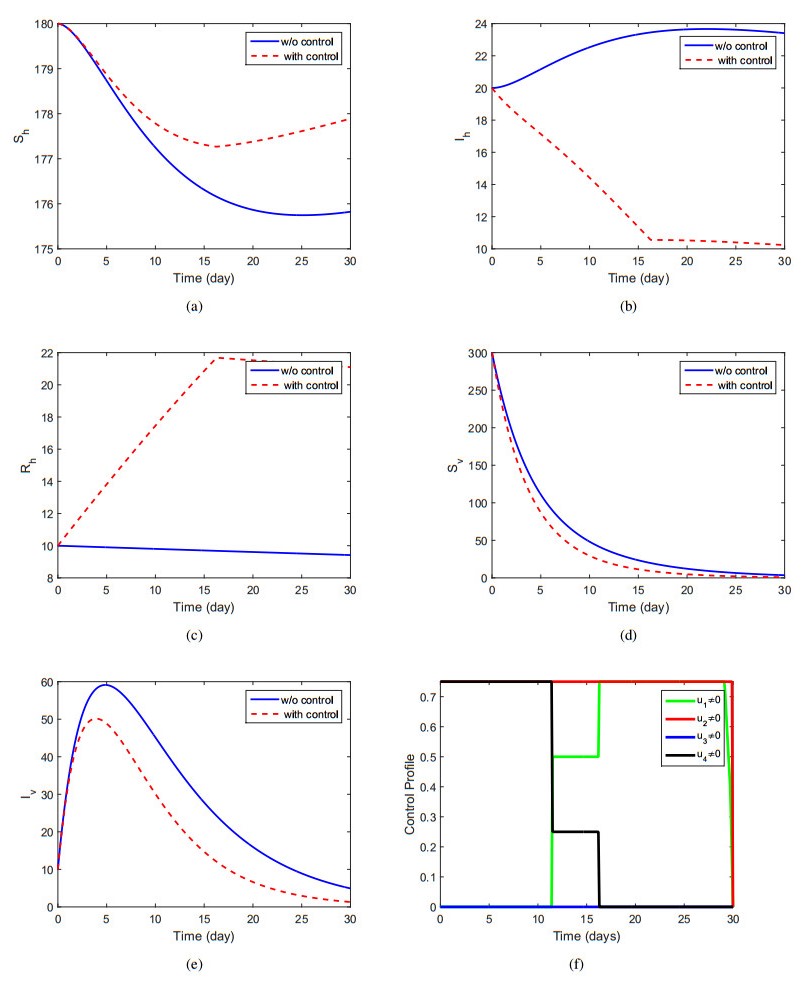
The aims of this paper to explore the dynamics of the vector-host disease with saturated treatment function. Initially, we formulate the model by considering three different classes for human and two for the vector population. The use of the treatment function in the model and their brief analysis for the case of disease-free and endemic case are briefly shown. We show that the basic reproduction number (<or >) than unity, the disease-free and endemic cases are stable locally and globally. Further, we apply the optimal control technique by choosing four control variables in order to maximize the population of susceptible and recovered human and to minimize the population of infected humans and vector. We discuss the results in details of the optimal controls model and show their existence. Furthermore, we solve the optimality system numerically in connection with the system of no control and the optimal control characterization together with adjoint system, and consider a set of different controls to simulate the models. The considerable best possible strategy that can best minimize the infection in human infected individuals is the use of all controls simultaneously. Finally, we conclude that the work with effective control strategies.
Citation: Muhammad Altaf Khan, Navid Iqbal, Yasir Khan, Ebraheem Alzahrani. A biological mathematical model of vector-host disease with saturated treatment function and optimal control strategies[J]. Mathematical Biosciences and Engineering, 2020, 17(4): 3972-3997. doi: 10.3934/mbe.2020220
The aims of this paper to explore the dynamics of the vector-host disease with saturated treatment function. Initially, we formulate the model by considering three different classes for human and two for the vector population. The use of the treatment function in the model and their brief analysis for the case of disease-free and endemic case are briefly shown. We show that the basic reproduction number (<or >) than unity, the disease-free and endemic cases are stable locally and globally. Further, we apply the optimal control technique by choosing four control variables in order to maximize the population of susceptible and recovered human and to minimize the population of infected humans and vector. We discuss the results in details of the optimal controls model and show their existence. Furthermore, we solve the optimality system numerically in connection with the system of no control and the optimal control characterization together with adjoint system, and consider a set of different controls to simulate the models. The considerable best possible strategy that can best minimize the infection in human infected individuals is the use of all controls simultaneously. Finally, we conclude that the work with effective control strategies.

| [1] | http://www.who.int/mediacentre/factsheets/fs387/en/ |
| [2] |
N. Surapol, T. Korkiatsakul, I. M. Tang, Dynamical model for determining human susceptibility to dengue fever, Am. J. Appl. Sci., 8 (2011), 1101. doi: 10.3844/ajassp.2011.1101.1106

|
| [3] | M. Rafiq, M. O. Ahmad, Numerical modeling of dengue disease with incubation period of virus, Pak. J. Eng. Appl. Sci., (2016). |
| [4] |
R. Rebeca, L. M. Harrison, R. A. Salas, D. Tovar, A. Nisalak, C. Ramos, et al., Origins of dengue type 2 viruses associated with increased pathogenicity in the Americas, Virology, 230 (1997), 244-251. doi: 10.1006/viro.1997.8504
|
| [5] | R. Ronald, The prevention of malaria, (2012). |
| [6] |
W. Hui-Ming, X. Z. Li, M. Martcheva, An epidemic model of a vector-borne disease with direct transmission and time delay, J. Math. Anal. Appl., 342 (2008), 895-908. doi: 10.1016/j.jmaa.2007.12.058
|
| [7] | F. Zhilan, J. X. Velasco-Hernndez, Competitive exclusion in a vector-host model for the dengue fever, J. Math. Biol., 35 (1997), 523-544. |
| [8] |
Q. Zhipeng, Dynamical behavior of a vector-host epidemic model with demographic structure, Comput. Math. Appl., 56 (2008), 3118-3129. doi: 10.1016/j.camwa.2008.09.002
|
| [9] | W. Viroj, Unusual mode of transmission of dengue, J. Inf. Devel. Coun., 4 (2009), 51-54. |
| [10] | G. S. Mohammed, A. B. Gumel, M. R. Abu Bakar, Backward bifurcations in dengue transmission dynamics, Math. Biosci., 215 (2008), 11-25. |
| [11] | C. Liming, X. Li, Analysis of a simple vector-host epidemic model with direct transmission, Disc. Dyna. Nat. Soc., 2010 (2010). |
| [12] |
M. Derouich, A. Boutayeb, Mathematical modelling and computer simulations of Dengue fever, App. Math. Comput., 177 (2006), 528-544. doi: 10.1016/j.amc.2005.11.031
|
| [13] |
F. B. Agusto, M. A. Khan, Optimal control strategies for dengue transmission in Pakistan, Math. Biosci., 305 (2018), 102-121. doi: 10.1016/j.mbs.2018.09.007
|
| [14] | E. Lourdes, C. Vargas, A model for dengue disease with variable human population, J. Math. Bio., 38 (1999), 220-240. |
| [15] | A. A. Lashari, S. Aly, K. Hattaf, G. Zaman, I. H. Jung, X. Z. Li, Presentation of malaria epidemics using multiple optimal controls, J. Appl. Math., 2012 (2012). |
| [16] | A. A. Lashari, K. Hattaf, G. Zaman, A delay differential equation model of a vector borne disease with direct transmission, Int. J. Ecol. Econ. Stat., (27), (2012), 25-35. |
| [17] | A. A. Lashari, K. Hattaf, G. Zaman G, X. Z. Li, Backward bifurcation and optimal control of a vector borne disease, Appl. Math. Infor. Sci., 7 (2013), 301-309. |
| [18] |
L. Zhou, M. Fan, Dynamics of an SIR epidemic model with limited resources visited, Nonl. Anal. Real. World. Appl., 13 (2012), 312-324. doi: 10.1016/j.nonrwa.2011.07.036
|
| [19] | C. H. Li, A. M. Yousef, Bifurcation analysis of a network-based SIR epidemic model with saturated treatment function, Chaos An Interdiscipl. J Nonl. Sci., 29(2019), 10.1063/1.5079631. |
| [20] | K. Hattaf, Y. Yang, Global dynamics of an age-structured viral infection model with general incidence function and absorptionm, Int. J. Biomath., 11, (2018), https://doi.org/10.1142/S1793524518500651. |
| [21] |
P. Jia, C. Wang, G. Zhang, J. Ma, A rumor spreading model based on two propagation channels in social networks, Phys. A Statist. Mechan. Appl., 524 (2019), 342-353. doi: 10.1016/j.physa.2019.04.163
|
| [22] | J. Yang, X. Wang, Threshold dynamics of an SIR model with nonlinear incidence rate and agedependent susceptibility, Complexity, 2018 (2018). |
| [23] | G. Birkhoff, G. C. Rota, Ordinary Differential Eqnarrays [M1]. Boston: Ginn (1982). |
| [24] |
V. D. D. Pauline, J. Watmough, Reproduction numbers and sub-threshold endemic equilibria for compartmental models of disease transmission, Math. Biosci, 180 (2002), 29-48. doi: 10.1016/S0025-5564(02)00108-6
|
| [25] |
C. Castillo-Chavez, B. Song, Dynamical models of tuberculosis and their applications, Math. Biosci. Eng., 1 (2004), 361-404. doi: 10.3934/mbe.2004.1.361
|
| [26] | L. Salle, P. Joseph, The stability of dynamical systems, Soc. Indus. Appl. Math., 1976. |
| [27] |
Y. Li. Michael, J. S. Muldowney, A geometric approach to global-stability problems, Siam. J. Math. Anal., 27 (1996), 1070-1083. doi: 10.1137/S0036141094266449
|
| [28] |
R. H. Martin, Logarithmic norms and projections applied to linear differential systems, J. Math. Anal. Appl., 45 (1974), 432-454. doi: 10.1016/0022-247X(74)90084-5
|
| [29] | K. O. Okosun, R. Smith, Optimal control analysis of malaria-schistosomiasis co-infection dynamics, Math. Biosci. Eng., 14 (2017), 377-405. |
| [30] |
K. O. Okosun, O. D. Makinde, A co-infection model of malaria and cholera diseases with optimal control, Math. Biosci., 258 (2014), 19-32. doi: 10.1016/j.mbs.2014.09.008
|
| [31] |
S. F. Saddiq, M. A. Khan, S. Islam, G. Zaman, I. I. H. Jung, et al. Optimal control of an epidemic model of leptospirosis with nonlinear saturated incidences, Ann. Res. Rev. Bio., 4 (2014), 560. doi: 10.9734/ARRB/2014/6378
|
| [32] |
M. A. Khan, R. Khan, Y. Khan, S. Islam, A mathematical analysis of Pine Wilt disease with variable population size and optimal control strategies, Chaos Solit. Fract., 108 (2018), 205-217. doi: 10.1016/j.chaos.2018.02.002
|
| [33] | M. A. Khan, K. Ali, E. Bonyah, K. O. Okosun, S. Islam & A. Khan, Mathematical modeling and stability analysis of Pine Wilt Disease with optimal control, Sci. Rep., 7 (2017), 3115. |
| [34] | F. H. Wendell, R. W. Rishel, Deterministic and stochastic optimal control, 1, Springer Science & Business Media, 2012. |
| [35] | F. K. Renee, S. Lenhart, J. S. McNally, Optimizing chemotherapy in an HIV model, Elec. J. Diff. Eqn., 32, (1998), 1-12. |
| [36] | L. S. Pontryagin, F. Moscow, Y. E. F. Mishchenko, et al, The mathematical theory of optimal processes, (1962). |

Figures(6) / Tables(1)

Muhammad Altaf Khan, Navid Iqbal, Yasir Khan, Ebraheem Alzahrani. A biological mathematical model of vector-host disease with saturated treatment function and optimal control strategies[J]. Mathematical Biosciences and Engineering, 2020, 17(4): 3972-3997. doi: 10.3934/mbe.2020220







 DownLoad:
DownLoad: