Citation: Kori Blankenship, Leonardo Frid, James L. Smith. A state-and-transition simulation modeling approach for estimating the historical range of variability[J]. AIMS Environmental Science, 2015, 2(2): 253-268. doi: 10.3934/environsci.2015.2.253

| [1] | Keane RE, Hessburg PF, Landres PB, et al. (2009) The use of historical range and variability (HRV) in landscape management. Forest Ecol Manag 258: 1025-1037. |
| [2] |
Forbis T, Provencher L, Frid L, et al. (2006) Great Basin land management planning using ecological modeling. Environ Manag 38: 62-83. doi: 10.1007/s00267-005-0089-2

|
| [3] |
Provencher L, Forbis T, Frid L, et al. (2007) Comparing alternative management strategies of fire, grazing, and weed control using spatial modeling. Ecol Model 209: 249-263. doi: 10.1016/j.ecolmodel.2007.06.030
|
| [4] | Low G, Provencher L, Abele S (2010) Enhanced conservation action planning: Assessing landscape condition and predicting benefits of conservation strategies. J Conserv Plan 6: 36-60. |
| [5] |
Hann WJ, Bunnell DL (2001) Fire and land management planning and implementation across multiple scales. Int J Wildland Fire 10: 389-403. doi: 10.1071/WF01037
|
| [6] | Shedd M, Gallagher J, Jiménez M, et al. (2012) Incorporating HRV in Minnesota National Forest Land and Resource Management Plans: A Practitioner's Story. In: Historical Environmental Variation in Conservation and Natural Resource Management Chichester, UK: John Wiley & Sons, Ltd. 176-193. |
| [7] | MacKinnon A, Saunders S (2012) Incorporating Concepts of Historical Range of Variation in Ecosystem-Based Management of British Columbia's Coastal Temperate Rainforest. In: Historical Environmental Variation in Conservation and Natural Resource Management. Chichester, UK: John Wiley & Sons, Ltd. 166-175. |
| [8] | Higgs E, Falk A, Guerrini A, et al. (2014) The changing role of history in restoration ecology. Front Ecol Environ 12: 499-506. |
| [9] | Landres PB, Morgan PM, Swanson FJ (1999) Overview of the use of natural variability concepts in managing ecological systems. Ecol Appl 9: 1179-1188. |
| [10] | Romme WH, Wiens JA, Safford HD (2012) Setting the Stage: Theoretical and Conceptual Background of Historical Range of Variation. In: Historical Environmental Variation in Conservation and Natural Resource Management. Chichester, UK: John Wiley & Sons, Ltd. 3-18. |
| [11] | Wong CM, Iverson K (2004) Range of natural variability: applying the concept to forest management in central British Columbia, BC. JEM Extension 4: 1-56. |
| [12] | Hayward GD, Veblen TT, Suring LH, et al. (2012) Historical Ecology, Climate Change, and Resource Management: Can the Past Still Inform the Future? In: Historical Environmental Variation in Conservation and Natural Resource Management Chichester, UK: John Wiley & Sons, Ltd. 32-45. |
| [13] |
Haugo R, Zanger C, DeMeo T, et al. (2015) A new approach to evaluate forest structure restoration needs across Oregon and Washington, USA. Forest Ecol Manag 335: 37-50. doi: 10.1016/j.foreco.2014.09.014
|
| [14] |
Hemstrom M, Merzenich J, Reger A, et al. (2007) Integrated analysis of landscape management scenarios using state and transition models in the upper Grande Ronde River Subbasin, Oregon, USA. Landscape Urban Plan 80: 198-211. doi: 10.1016/j.landurbplan.2006.10.004
|
| [15] | Daniel CJ, Frid L (2012) Predicting Landscape Vegetation Dynamics Using State-and-Transition Simulation Models. In: Proceedings of the First Landscape State-and-Transition Simulation Modeling Conference. Portland, OR: U.S. Department of Agriculture, Forest Service, Pacific Northwest Research Station 5-22. |
| [16] | ESSA Technologies Ltd. (2010) Vegetation Dynamics Development Tool. Available from: http://essa.com/tools/vddt/. |
| [17] | Apex Resource Management Solutions Ltd. (2014) ST-Sim: State-and-Transition Simulation Model Framework. Available from: http://www.apexrms.com/. |
| [18] | Barrett S, Havlina D, Jones J, et al. (2010) Interagency Fire Regime Condition Class Guidebook. Version 3.0. Available from: http://www.frcc.gov. |
| [19] |
Rollins MG (2009) LANDFIRE: a nationally consistent vegetation, wildland fire, and fuel assessment. Int J Wildland Fire 18: 235-249. doi: 10.1071/WF08088
|
| [20] | Lolley M, McNicoll C, Encinas J, et al. (2006) Restoring the functionality of fire adapted ecosystems, Gila National Forest, restoration need and opportunity. Unpublished report. Gila National Forest. |
| [21] |
Provencher L, Campbell J, Nachlinger J (2008) Implementation of mid-scale fire regime condition class mapping at Mt. Grant, Nevada. Int J Wildland Fire 17: 390-406. doi: 10.1071/WF07066
|
| [22] | Helmbrecht D, Williamson M, Abendroth D (2012) Bridger-Teton National Forest Vegetation Condition Assessment. Prepared for Bridger-Teton National Forest. U.S. Department of Agriculture. Unpublished report. 38 p. Available from: https://www.conservationgateway.org/Files/Pages/BridgerTetonHelmbrecht.aspx. |
| [23] | Shlisky AJ, Guyette RP, Ryan KC (2005) Modeling reference conditions to restore altered fire regimes in oak-hickory-pine forests: validating coarse models with local fire history data. In: EastFire Conference Proceedings. George Mason University. Fairfax, VA. 4 p. |
| [24] | Weisz R, Tripeke J, Truman R (2009) Evaluating the ecological sustainability of a ponderosa pine ecosystem on the Kaibab Plateau in Northern Arizona. Fire Ecol 5: 100-114. |
| [25] |
Swetnam TL, Brown PM (2010) Comparing selected fire regime condition class (FRCC) and LANDFIRE vegetation model results with tree-ring data. Int J Wildland Fire 19: 1-13. doi: 10.1071/WF08001
|
| [26] | McGarigal K, Romme W, Goodwin D, et al. (2003) Simulating the dynamics in landscape structure and wildlife habitat in Rocky Mountain landscapes: The Rocky Mountain Landscape Simulator (RMLANDS) and associated models. Department of Natural Resources Conservation, University of Massachusetts, Amherst, MA. Unpublished report. 19 p. Available from: http://www.umass.edu/landeco/research/rmlands/documents/RMLANDS_overview.pdf. |
| [27] | Keane RE, Holsinger LM, Pratt SD (2006) Simulating historical landscape dynamics using the landscape fire succession model LANDSUM version 4.0. Gen. Tech. Rep. RMRS-GTR-171CD. Fort Collins, CO: U.S. Department of Agriculture, Forest Service, Rocky Mountain Research Station. 73 p. |
| [28] | LANDFIRE (2014) LANDFIRE Vegetation Dynamics Models. U.S. Department of Agriculture, Forest Service; U.S. Department of Interior. April 8, 2014. Available from: http://www.landfire.gov/index.php. |
| [29] | Johnson NL, Kotz S, Balakrishnan N (1995) Chapter 21: Beta Distributions. In: Continuous Univariate Distributions Vol. 2 (2nd ed.) New York, NY: Wiley. John Wiley & Sons, Ltd. |
| [30] | LANDFIRE (2014) LANDFIRE 1.2.0 Biophysical Settings layer. U.S. Department of Interior, Geological Survey. April 8, 2014. Available from: http://landfire.cr.usgs.gov/viewer/. |
| [31] | LANDFIRE (2014) LANDFIRE 1.2.0 Succession Class layer. U.S. Department of Interior, Geological Survey. April 8, 2014. Available from: http://landfire.cr.usgs.gov/viewer/. |
| [32] |
Skinner CN (1995) Change in spatial characteristics of forest openings in the Klamath Mountains of northwestern California, USA. Landscape Ecol 10: 219-228. doi: 10.1007/BF00129256
|
| [33] | Hessburg PF, Smith BG, Kreiter SG, et al. (1999) Historical and current forest and range landscapes in the Interior Columbia River Basin and portions of the Klamath and Great Basins. Part 1. Linking vegetation patterns and landscape vulnerability to potential insect and pathogen disturbances. Gen. Tech. Rep. PNW-GTR-458. Portland, OR: U.S. Department of Agriculture, Forest Service, Pacific Northwest Research Station. 357 p. |
| [34] | Hessburg PF, Smith BG, Salter RB, et al. (2000) Recent changes (1930s–1990s) in spatial patterns of interior northwest forests, USA. Forest Ecol Manag136: 53-83. |
| [35] |
Turner MG, Romme WH, Gardner RH, et al. (1993) A revised concept of landscape equilibrium: Disturbance and stability on scaled landscapes. Landscape Ecol 8: 213-227. doi: 10.1007/BF00125352
|
| [36] |
Wimberly MC, Spies TA, Long CJ, et al. (2000) Simulating Historical Variability in the amount of old forests in the Oregon Coast Range. Conserv Biol 14: 167-180. doi: 10.1046/j.1523-1739.2000.98284.x
|
| [37] | Meyer CB, Knight DH, Dillon GK (2010) Use of the historic range of variability to evaluate ecosystem sustainability. In: Climate Change and Sustainable Development. Urbana, IL: Linton Atlantic Books, Ltd. 251-261. |
| [38] | Blankenshi, K, Smith J, Swaty R, et al. (2012) Modeling on the Grand Scale: LANDFIRE Lessons Learned. In: Proceedings of the First Landscape State-and-Transition Simulation Modeling Conference. Portland, OR: U.S. Department of Agriculture, Forest Service, Pacific Northwest Research Station 43-56. |
| [39] |
Czembor CA, Morris WK, Wintle BA, et al. (2011) Quantifying variance components in ecological models based on expert opinion. J Appl Ecol 48: 736-745. doi: 10.1111/j.1365-2664.2011.01971.x
|
| [40] |
Czembor CA, Vesk PA (2009) Incorporating between-expert uncertainty into state-and-transition simulation models for forest restoration. Forest Ecol Manag 259: 165-175. doi: 10.1016/j.foreco.2009.10.002
|
| [41] | Millar CI, Stephenson NL, Stephens SL (2007) Climate change and forests of the future: managing in the face of uncertainty. Ecol Appl 17: 2145-2151. |
| [42] |
Millar CI (2014) Historic variability: informing restoration strategies, not prescribing targets. J Sustain Forest 33: S28-S42. doi: 10.1080/10549811.2014.887474
|
| [43] |
Balaguer L, Escudero A, Martín-Duque J, et al. (2014) The historical reference in restoration ecology: Re-defining a cornerstone concept. Biol Conserv 176: 12-20. doi: 10.1016/j.biocon.2014.05.007
|
| [44] |
Millar CI, Woolfenden WB (1999) The role of climate change in interpreting historical variability. Ecol Appl 9:1207-1216. doi: 10.1890/1051-0761(1999)009[1207:TROCCI]2.0.CO;2
|
| [45] | Safford HD, Hayward GD, Heller NE, et al. (2012) Historical Ecology, Climate Change, and Resource Management: Can the Past Still Inform the Future? In: Historical Environmental Variation in Conservation and Natural Resource Management Chichester, UK: John Wiley & Sons, Ltd. 46-62. |
| [46] | Myer G (2013) The Rogue Basin Action Plan for Resilient Watersheds and Forests in a Changing Climate. Thaler, T, Griffith, G, Perry, A, Crossett, T, et al. (Eds). Model Forest Policy Program in Association with the Southern Oregon Forest Restoration Collaborative, the Cumberland River Compact and Headwaters Economics. Sagle, ID. |
| [47] |
North M, Hurteau M, Innes J (2009) Fire suppression and fuels treatment effects on mixed-conifer carbon stocks and emissions. Ecol Appl 19: 1385-1396. doi: 10.1890/08-1173.1
|
| [48] | Hessburg PF, Salter RB, Reynolds KM, et al. (2014) Landscape Evaluation and Restoration Planning. USDA Forest Service / UNL Faculty Publications. Paper 268. Available from: http://digitalcommons.unl.edu/usdafsfacpub/268. |
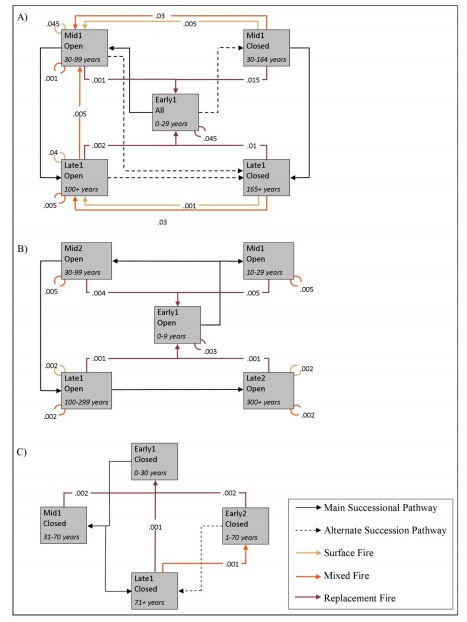
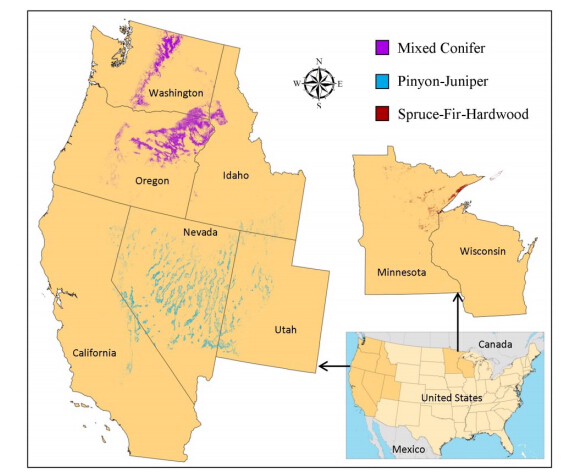
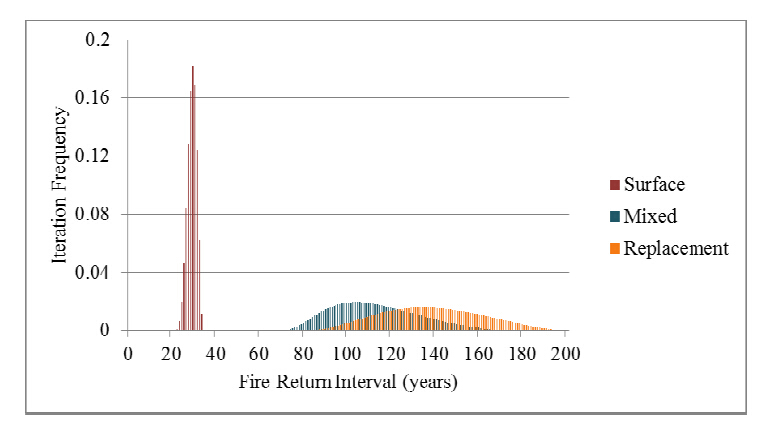
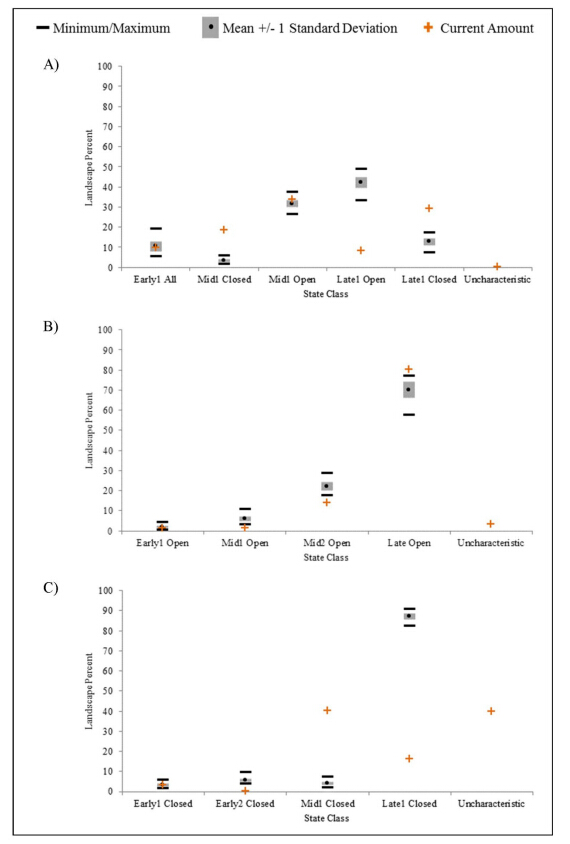
Figures(4)

Kori Blankenship, Leonardo Frid, James L. Smith. A state-and-transition simulation modeling approach for estimating the historical range of variability[J]. AIMS Environmental Science, 2015, 2(2): 253-268. doi: 10.3934/environsci.2015.2.253







 DownLoad:
DownLoad: