Citation: Virginia Agostiniani, Antonio DeSimone, Alessandro Lucantonio, Danka Lučić. Foldable structures made of hydrogel bilayers[J]. Mathematics in Engineering, 2019, 1(1): 204-223. doi: 10.3934/Mine.2018.1.204

| [1] | Agostiniani V, Lucantonio A, Lučić D (2018) Heterogeneous elastic plates with in-plane modulation of the target curvature and applications to thin gel sheets. ESAIM Contr Optim Ca in press. |
| [2] | Agostiniani V, DeSimone A (2017) Rigorous derivation of active plate models for thin sheets of nematic elastomers. Math Mech Solids in press. |
| [3] |
Agostiniani V, DeSimone A (2017) Dimension reduction via Γ-convergence for soft active materials. Meccanica 52: 3457–3470. doi: 10.1007/s11012-017-0630-4

|
| [4] |
Klein Y, Efrati E, Sharon E (2007) Shaping of elastic sheets by prescription of non-Euclidean metrics. Science 315: 1116–1120. doi: 10.1126/science.1135994
|
| [5] |
Aharoni H, Sharon E, Kupferman R (2014) Geometry of thin nematic elastomer sheets. Phys Rev Lett 113: 257801. doi: 10.1103/PhysRevLett.113.257801
|
| [6] |
Hamouche W, Maurini C, Vincenti A, et al. (2017) Multi-parameter actuation of a neutrally stable shell: a flexible gear-less motor. Proc R Soc A 473: 20170364. doi: 10.1098/rspa.2017.0364
|
| [7] |
Armon S, Efrati E, Sharon E, et al. (2011) Geometry and mechanics in the opening of chiral seed pods. Science 333: 1726–1730. doi: 10.1126/science.1203874
|
| [8] | Dawson C, Vincent JFV, Rocca AM (1997) How pine cones open. Nature 290: 668. |
| [9] |
Hu Z, Zhang X, Li Y (1995) Synthesis and application of modulated polymer gels. Science 269: 525–527. doi: 10.1126/science.269.5223.525
|
| [10] |
Ionov L (2011) Soft microorigami: self-folding polymer films. Soft Matter 7: 6786–6791. doi: 10.1039/c1sm05476g
|
| [11] |
Guo W, Li M, Zhou J (2013) Modeling programmable deformation of self-folding all-polymer structures with temperature-sensitive hydrogels. Smart Mater Struct 22: 115028. doi: 10.1088/0964-1726/22/11/115028
|
| [12] |
Mao Y, Yu K, Isakov MS, et al. (2015) Sequential self-folding structures by 3D printed digital shape memory polymers. Sci Rep-UK 5: 13616. doi: 10.1038/srep13616
|
| [13] |
Na JH, Evans AA, Bae J, et al. (2015) Programming reversibly self-folding origami with micropatterned photo-crosslinkable polymer trilayers. Adv Mater 27: 79–85. doi: 10.1002/adma.201403510
|
| [14] |
Liu Y, Shaw B, Dickey MD, et al. (2017) Sequential self-folding of polymer sheets. Sci Adv 3: e1602417. doi: 10.1126/sciadv.1602417
|
| [15] |
Hawkes W, An B, Benbernou NM, et al. (2010) Programmable matter by folding. P Natl Acad Sci USA 107: 12441–12445. doi: 10.1073/pnas.0914069107
|
| [16] |
Yoon C, Xiao R, Park J, et al. (2014) Functional stimuli responsive hydrogel devices by self-folding. Smart Mater Struct 23: 094008. doi: 10.1088/0964-1726/23/9/094008
|
| [17] |
Doi M (2009) Gel dynamics. J Phys Soc Jpn 78: 052001. doi: 10.1143/JPSJ.78.052001
|
| [18] |
Schmidt B (2007) Plate theory for stressed heterogeneous multilayers of finite bending energy. J Math Pure Appl 88: 107–122. doi: 10.1016/j.matpur.2007.04.011
|
| [19] |
Lucantonio A, Nardinocchi P, Stone HA (2014) Swelling dynamics of a thin elastomeric sheet under uniaxial pre-stretch. J Appl Phys 115: 083505. doi: 10.1063/1.4866576
|
| [20] |
Dai HH, Song Z (2011) Some analytical formulas for the equilibrium states of a swollen hydrogel shell. Soft Matter 7: 8473–8483. doi: 10.1039/c1sm05425b
|
| [21] | Topsøe F (2007) Some bounds for the logarithmic function, In: Cho YJ, Kim JK, Dragomir SS Editors, Inequality theory and applications 4, New York: Nova Science Publishers, 137. |
| [22] |
DeSimone A, Teresi L (2009) Elastic energies for nematic elastomers. Eur Phys J E 29: 191–204. doi: 10.1140/epje/i2009-10467-9
|
| [23] |
DeSimone A (1999) Energetics of fine domain structures. Ferroelectrics 222: 275–284. doi: 10.1080/00150199908014827
|
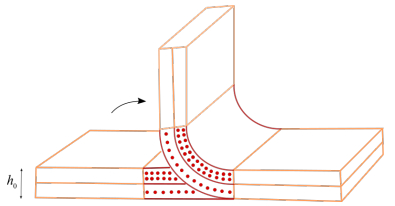
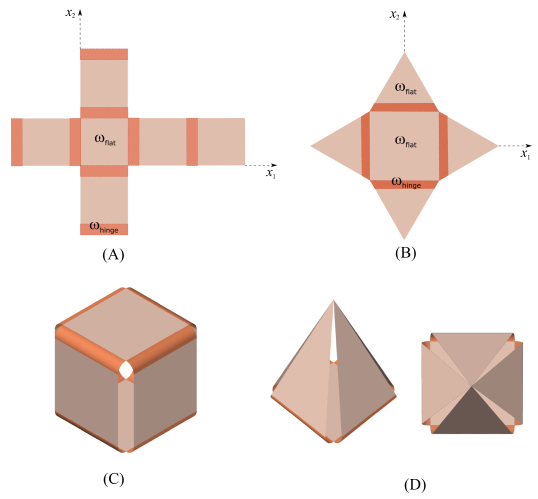
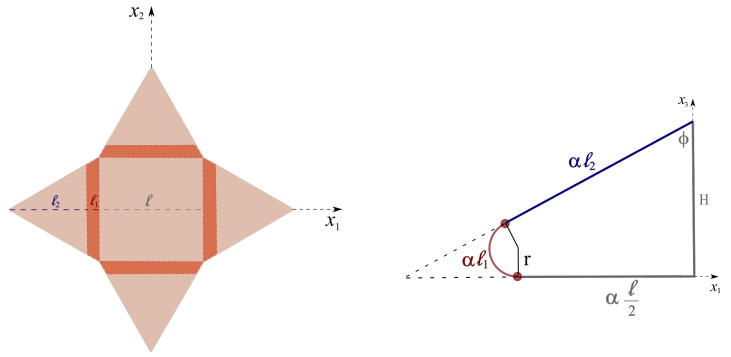
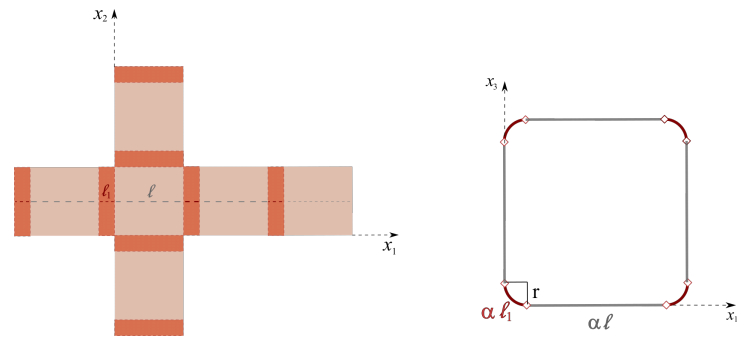
Figures(4)

Virginia Agostiniani, Antonio DeSimone, Alessandro Lucantonio, Danka Lučić. Foldable structures made of hydrogel bilayers[J]. Mathematics in Engineering, 2019, 1(1): 204-223. doi: 10.3934/Mine.2018.1.204







 DownLoad:
DownLoad: