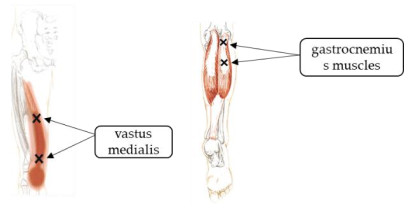
The purpose of this study was to examine the effect of neuromuscular electrical stimulation (NMES) immediate intervention training on the countermovement jump (CMJ) height and to explore kinematic differences in the CMJ at each instant. A total of 15 male students who had never received electrical stimulation were randomly selected as the research participants. In the first test, the CMJ performance was completed with an all-out effort. The second experiment was best performed immediately to complete the CMJ operation after NMES for 30 min. Both experiments used a high-speed camera optical capture system to collect kinematic data. The results of this experiment revealed that after im-mediate NMES training, neuromuscular activation causes post-activation potentiation, which increases the height of the center of gravity of the CMJ and affects the angular velocity of the hip joint, the velocity and acceleration of the thigh and the shank and the velocity of the soles of the feet. The use of NMES interventional training based on the improvement of technical movements and physical exercises is recommended in the future.
Citation: Chao-Fu Chen, Shu-Fan Wang, Xing-Xing Shen, Lei Liu, Hui-Ju Wu. Kinematic analysis of countermovement jump performance in response to immediate neuromuscular electrical stimulation[J]. Mathematical Biosciences and Engineering, 2023, 20(9): 16033-16044. doi: 10.3934/mbe.2023715
The purpose of this study was to examine the effect of neuromuscular electrical stimulation (NMES) immediate intervention training on the countermovement jump (CMJ) height and to explore kinematic differences in the CMJ at each instant. A total of 15 male students who had never received electrical stimulation were randomly selected as the research participants. In the first test, the CMJ performance was completed with an all-out effort. The second experiment was best performed immediately to complete the CMJ operation after NMES for 30 min. Both experiments used a high-speed camera optical capture system to collect kinematic data. The results of this experiment revealed that after im-mediate NMES training, neuromuscular activation causes post-activation potentiation, which increases the height of the center of gravity of the CMJ and affects the angular velocity of the hip joint, the velocity and acceleration of the thigh and the shank and the velocity of the soles of the feet. The use of NMES interventional training based on the improvement of technical movements and physical exercises is recommended in the future.

| [1] |
G. Papaiakovou, Kinematic and kinetic differences in the execution of vertical jumps between people with good and poor ankle joint dorsiflexion, J. Sports Sci., 31 (2013), 1789–1796. https://doi.org/10.1080/02640414.2013.803587 doi: 10.1080/02640414.2013.803587

|
| [2] |
W. C. Dobbs, D. V. Tolusso, M. V. Fedewa, M. R. Esco, Effect of postactivation potentiation on explosive vertical jump: A systematic review and meta-analysis, J. Strength Cond. Res., 33 (2019), 2009–2018. https://doi.org/10.1519/JSC.0000000000002750 doi: 10.1519/JSC.0000000000002750
|
| [3] |
G. P. Berriel, A. S. Cardoso, R. R. Costa, R. G. Rosa, H. B. Oliveira, L. F. M. Kruel, et al., Effects of postactivation performance enhancement on the vertical jump in high-level volleyball athletes, J. Hum. Kinet., 82(2022), 145–153. https://doi.org/10.2478/hukin-2022-0041 doi: 10.2478/hukin-2022-0041
|
| [4] |
F. Bello, E. Aedo-Muñoz, D. Moreira, C. Brito, B. Miarka, E. Cabello, Beach and indoor volleyball athletes present similar lower limb muscle activation during a countermovement jump, Hum. Mov., 21(2019), 42–50. https://doi.org/10.5114/hm.2020.89913 doi: 10.5114/hm.2020.89913
|
| [5] |
M. A. Mina, A. J. Blazevich, T. Tsatalas, G. Giakas, L. B. Seitz, A. D. Kay, Variable, but not free-weight, resistance back squat exercise potentiates jump performance following a comprehensive task-specific warm-up, Scand. J. Med. Sci. Sports, 29 (2019), 380–392. https://doi.org/10.1111/sms.13341 doi: 10.1111/sms.13341
|
| [6] |
R. J. Downey, D. A. Deprez, P. D. Chilibeck, Effects of postactivation potentiation on maximal vertical jump performance after a conditioning contraction in upper-body and lower-body muscle groups, J. Strength Cond. Res., 36 (2022), 259–261. https://doi.org/10.1519/JSC.0000000000004171 doi: 10.1519/JSC.0000000000004171
|
| [7] |
D. G. Sale, Postactivation potentiation: role in performance, Br. J. Sports Med., 38 (2004), 386–387. https://doi.org/10.1136/bjsm.2002.003392 doi: 10.1136/bjsm.2002.003392
|
| [8] |
S. Vuk, G. Markovic, S. Jaric, External loading and maximum dynamic output in vertical jumping: The role of training history, Hum. Mov. Sci., 31 (2012), 139–151. https://doi.org/10.1016/j.humov.2011.04.007 doi: 10.1016/j.humov.2011.04.007
|
| [9] |
J. J. McMahon, T. J. Suchomel, J. P. Lake, P. Comfort, Understanding the key phases of the countermovement jump force-time curve, Strength Cond. J., 40 (2018), 96–106. https://doi.org/10.1519/SSC.0000000000000375 doi: 10.1519/SSC.0000000000000375
|
| [10] |
Z. Anicic, D. Janicijevic, O. M. Knezevic, A. Garcia-Ramos, M. R. Petrovic, D. Cabarkapa, et al., Assessment of countermovement jump: What should we report?, Life, 13 (2023), 190. https://doi.org/10.3390/life13010190 doi: 10.3390/life13010190
|
| [11] |
D. G. Sale, Postactivation potentiation: role in human performance, Exercise Sport Sci. Rev., 30 (2002), 138–143. https://doi.org/10.1097/00003677-200207000-00008 doi: 10.1097/00003677-200207000-00008
|
| [12] |
M. Spieszny, R. Trybulski, P. Biel, A. Zając, M. Krzysztofik, Post-Isometric back squat performance enhancement of squat and countermovement jump, Int. J. Environ. Res. Public Health, 19 (2022), 12720. https://doi.org/10.3390/ijerph191912720 doi: 10.3390/ijerph191912720
|
| [13] |
L. Villalon-Gasch, A. Penichet-Tomas, S. Sebastia-Amat, B. Pueo, J. M. Jimenez-Olmedo, Postactivation performance enhancement (PAPE) increases vertical jump in elite female volleyball players, Int. J. Environ. Res. Public Health, 19 (2022), 462. https://doi.org/10.3390/ijerph19010462 doi: 10.3390/ijerph19010462
|
| [14] |
R. G. Gheller, J. Dal Pupo, L. A. P. D. Lima, B. M. D. Moura, S. G. D. Santos, A influência da profundidade de agachamento no desempenho e em parâmetros biomecânicos do salto com contra movimento, Revista Brasileira Cineantropometria Desempenho Humano, 16 (2014), 658–668. https://doi.org/10.5007/1980-0037.2014v16n6p658 doi: 10.5007/1980-0037.2014v16n6p658
|
| [15] |
R. G. Gheller, J. Dal Pupo, J. Ache-Dias, D. Detanico, J. Padulo, S. G. dos Santos, Effect of different knee starting angles on intersegmental coordination and performance in vertical jumps, Hum. Mov. Sci., 42 (2015), 71–80. https://doi.org/10.1016/j.humov.2015.04.010 doi: 10.1016/j.humov.2015.04.010
|
| [16] |
T. B. M. A. Moura, V. H. A. Okazaki, Kinematic and kinetic variable determinants on vertical jump performance: A review, MOJ Sports Med., 5 (2022), 25–33. https://doi.org/10.15406/mojsm.2022.05.00113 doi: 10.15406/mojsm.2022.05.00113
|
| [17] |
M. J. Bade, J. E. Stevens-Lapsley, Restoration of physical function in patients following total knee arthroplasty: An update on rehabilitation practices, Curr. Opin. Rheumatol., 24 (2012), 208–214. https://doi.org/10.1097/BOR.0b013e32834ff26d doi: 10.1097/BOR.0b013e32834ff26d
|
| [18] |
T. E. Cayot, J. W. Bellew, S. Kennedy, E. Pursley, N. Smith, K. Stemme, Acute effects of 3 neuromuscular electrical stimulation waveforms on exercising and recovery microvascular oxygenation responses, J. Sport Rehabil., 31 (2022), 554–561. https://doi.org/10.1123/jsr.2021-0326 doi: 10.1123/jsr.2021-0326
|
| [19] | M. Behringer, M. Moser, J. Montag, M. McCourt, D. Tenner, J. Mester, Electrically induced muscle cramps induce hypertrophy of calf muscles in healthy adults, J. Musculoskeletal Neuronal Interact., 15 (2015), 227–236. |
| [20] | M. Pantović, B. Popović, D. Madić, J. Obradović, Effects of neuromuscular electrical stimulation and resistance training on knee extensor/flexor muscles, Coll. Antropol., 39 (2015), 153–157. |
| [21] | C. He, X. X. Shen, X. X. Xie, X. Y. Chen, C. F. Chen, The influence of NMES intervention on martial arts flying double flying feet, Phys. Educ. Kaohsiung Univ. Appl. Sci., 5 (2022), 29–39. |
| [22] |
Y. Lima, O. Ozkaya, G. A. Balci, R. Aydinoglu, C. Islegen, Electromyostimulation application on peroneus longus muscle improves balance and strength in American football players, J. Sport Rehabil., 31(2022), 599–604. https://doi.org/10.1123/jsr.2021-0264 doi: 10.1123/jsr.2021-0264
|
| [23] |
Ş. Şimşek, A. N. O. Soysal, A. K. Özdemir, Ãœ. B. Aslan, M. B. Korkmaz, Effect of superimposed Russian current on quadriceps strength and lower-extremity endurance in healthy males and females, J. Sport Rehabil., 32 (2022), 46–52. https://doi.org/10.1123/jsr.2021-0437 doi: 10.1123/jsr.2021-0437
|
| [24] | B. Andrew, Trail Guide To The Body’S Quick Reference To Trigger Points, Books of Discovery, 2019. |
| [25] |
W. T. Dempster, The anthropometry of body action, Ann. New York Acad. Sci., 63 (1955), 559–585. https://doi.org/10.1111/j.1749-6632.1955.tb32112.x doi: 10.1111/j.1749-6632.1955.tb32112.x
|
| [26] |
C. F. Chen, H. J. Wu, The effect of an 8-week rope skipping intervention on standing long jump performance, Int. J. Environ. Res. Pub. Health, 19 (2022), 8472. https://doi.org/10.3390/ijerph19148472 doi: 10.3390/ijerph19148472
|
| [27] |
C. F. Chen, H. J. Wu, Z. S. Yang, H. Chen, H. T. Peng, Motion analysis for jumping discus throwing correction, Int. J. Environ. Res. Pub. Health, 18 (2021), 13414. https://doi.org/10.3390/ijerph182413414 doi: 10.3390/ijerph182413414
|
| [28] |
C. F. Chen, H. J. Wu, C. Liu, S. C. Wang, Kinematics analysis of male runners via forefoot and rearfoot strike strategies: A preliminary study, Int. J. Environ. Res. Pub. Health, 19 (2022), 15924. https://doi.org/10.3390/ijerph192315924 doi: 10.3390/ijerph192315924
|
| [29] | C. F. Chen, M. H. Chuang, H. J. Wu, Joint energy and shot mechanical energy of glide-style shot put, in Proceedings of the Institution of Mechanical Engineers, Part P: Journal of Sports Engineering and Technology, (2022). https://doi.org/10.1177/17543371221123168 |
| [30] | J. Cohen, Statistical Power Analysis for the Behavioral Sciences, 2nd edition, Academic Press, New York, 1988. |
| [31] |
K. Mackala, J. Stodólka, A. Siemienski, M. Coh, Biomechanical analysis of squat jump and countermovement jump from varying starting positions, J. Strength Cond. Res., 27 (2013), 2650–2661. https://doi.org/10.1519/JSC.0b013e31828909ec doi: 10.1519/JSC.0b013e31828909ec
|
| [32] |
M. Billot, A. Martin, C. Paizis, C. Cometti, N. Babault, Effects of an electrostimulation training program on strength, jumping, and kicking capacities in soccer players, J. Strength Cond. Res., 24 (2010), 1407–1413. https://doi.org/10.1519/JSC.0b013e3181d43790 doi: 10.1519/JSC.0b013e3181d43790
|
| [33] |
S. Rtolomei, R. De Luca, S. M. Marcora, May a nonlocalized postactivation performance enhancement exist between the upper and lower body in trained men, J. Strength Cond. Res., 37 (2023), 68–73. https://doi.org/10.1519/JSC.0000000000004243 doi: 10.1519/JSC.0000000000004243
|
| [34] | R. M. Enoka, Neuromechanics of Human Movement 5th Edition, Champaign, 2015. https://doi.org/10.5040/9781492595632 |



Figures(4) / Tables(4)

Chao-Fu Chen, Shu-Fan Wang, Xing-Xing Shen, Lei Liu, Hui-Ju Wu. Kinematic analysis of countermovement jump performance in response to immediate neuromuscular electrical stimulation[J]. Mathematical Biosciences and Engineering, 2023, 20(9): 16033-16044. doi: 10.3934/mbe.2023715







 DownLoad:
DownLoad: