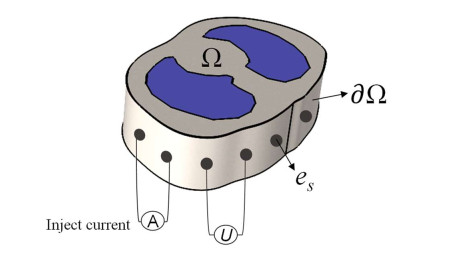
Electrical impedance tomography (EIT) is an imaging technique that non-invasively acquires the electrical conductivity distribution within a field. The ill-posed and nonlinear nature of the image reconstruction process results in lower quality of the obtained images. To solve this problem, an EIT image reconstruction method based on DenseNet with multi-scale convolution named MS-DenseNet is proposed. In the proposed method, three different multi-scale convolutional dense blocks are incorporated to replace the conventional dense blocks; they are placed in parallel to improve the generalization ability of the network. The connection layer between dense blocks adopts a hybrid pooling structure, which reduces the loss of information in the traditional pooling process. A learning rate setting achieves reduction in two stages and optimizes the fitting ability of the network. The input of the constructed network is the boundary voltage data, and the output is the conductivity distribution of the imaging area. The network was trained and tested on a simulated dataset, and it was further tested using actual measurement data. The images reconstructed via this method were evaluated by employing root mean square error, structural similarity index measure, mean absolute error and image correlation coefficient in comparison with conventional DenseNet and Gauss-Newton. The results show that the method improves the artifact and edge blur problems, achieves higher values on the image metrics and improves the EIT image quality.
Citation: Dan Yang, Shijun Li, Yuyu Zhao, Bin Xu, Wenxu Tian. An EIT image reconstruction method based on DenseNet with multi-scale convolution[J]. Mathematical Biosciences and Engineering, 2023, 20(4): 7633-7660. doi: 10.3934/mbe.2023329
Electrical impedance tomography (EIT) is an imaging technique that non-invasively acquires the electrical conductivity distribution within a field. The ill-posed and nonlinear nature of the image reconstruction process results in lower quality of the obtained images. To solve this problem, an EIT image reconstruction method based on DenseNet with multi-scale convolution named MS-DenseNet is proposed. In the proposed method, three different multi-scale convolutional dense blocks are incorporated to replace the conventional dense blocks; they are placed in parallel to improve the generalization ability of the network. The connection layer between dense blocks adopts a hybrid pooling structure, which reduces the loss of information in the traditional pooling process. A learning rate setting achieves reduction in two stages and optimizes the fitting ability of the network. The input of the constructed network is the boundary voltage data, and the output is the conductivity distribution of the imaging area. The network was trained and tested on a simulated dataset, and it was further tested using actual measurement data. The images reconstructed via this method were evaluated by employing root mean square error, structural similarity index measure, mean absolute error and image correlation coefficient in comparison with conventional DenseNet and Gauss-Newton. The results show that the method improves the artifact and edge blur problems, achieves higher values on the image metrics and improves the EIT image quality.

| [1] | A. Adler, A. Boyle, Electrical impedance tomography: Tissue properties to image measures, in IEEE Transactions on Biomedical Engineering, 64 (2017), 2494–2504. https://doi.org/10.1109/TBME.2017.2728323 |
| [2] |
A. Shono, T. Kotani, Clinical implication of monitoring regional ventilation using electrical impedance tomography, J. Intensive Care, 4 (2019). https://doi.org/10.1186/s40560-019-0358-4 doi: 10.1186/s40560-019-0358-4

|
| [3] | E. K. Murphy, A. Mahara, R. J. Halter, Absolute reconstructions using rotational electrical impedance tomography for breast cancer imaging, in IEEE Transactions on Medical Imaging, 36 (2017), 892–903. https://doi.org/10.1109/TMI.2016.2640944 |
| [4] |
K. Y. Aristovich, B. C. Packham, H. Koo, G. S. dos Santos, A. McEvoy, D. S. Holder, Imaging fast electrical activity in the brain with electrical impedance tomography, NeuroImage, 124 (2016), 204–213. https://doi.org/10.1016/j.neuroimage.2015.08.071 doi: 10.1016/j.neuroimage.2015.08.071
|
| [5] |
Y. Luo, P. Abiri, S. C. Zhang, C. Chang, A. H. Kaboodrangi, R. Li, et al., Non-invasive electrical impedance tomography for multi-scale detection of liver fat content, Theranostics, 8 (2018), 1636. https://doi.org/10.7150/thno.22233 doi: 10.7150/thno.22233
|
| [6] | B. Sun, S. Yue, Z. Cui, H. Wang, A new linear back projection algorithm to electrical tomography based on measuring data decomposition, Meas. Sci. Technol., 26 (2015), 125402. |
| [7] |
Z. Xu, J. Yao; Z. Wang, Y. Liu, H. Wang, B. Chen, et al., Development of a portable electrical impedance tomography system for biomedical applications, IEEE Sensors J., 18 (2018), 8117–8124. https://doi.org/10.1109/JSEN.2018.2864539 doi: 10.1109/JSEN.2018.2864539
|
| [8] | Q. Wang, K. Sun, J. Wang, R. Zhang, H. Wang, Reconstruction of EIT images via patch based sparse representation over learned dictionaries, in 2015 IEEE International Instrumentation and Measurement Technology Conference (I2MTC) Proceedings, (2015), 2044–2048, https://doi.org/10.1109/I2MTC.2015.7151597. |
| [9] |
T. A. Khan, S. H. Ling, Review on electrical impedance tomography: Artificial intelligence methods and its applications, Algorithms, 12 (2019), 88. https://doi.org/10.3390/a12050088 doi: 10.3390/a12050088
|
| [10] |
J. Kim, B. Y. Choi, U. Z. Ijaz, B. S. Kim, S. Kim, Directional algebraic reconstruction technique for electrical impedance tomography, J. Korean Phys. Soc., 54 (2009), 1439–1447. https://doi.org/10.3938/jkps.54.1439 doi: 10.3938/jkps.54.1439
|
| [11] |
S. Agatonovic-Kustrin, R. Beresford, Basic concepts of artificial neural network (ANN) modeling and its application in pharmaceutical research, J. Pharm. Biomed. Anal., 22 (2000), 717–727. https://doi.org/10.1016/S0731-7085(99)00272-1 doi: 10.1016/S0731-7085(99)00272-1
|
| [12] |
B. S. Kim, K. Y. Kim, Resistivity imaging of binary mixture using weighted Landweber method in electrical impedance tomography, Flow Meas. Instrum., 53 (2017), 39–48. https://doi.org/10.1016/j.flowmeasinst.2016.05.002 doi: 10.1016/j.flowmeasinst.2016.05.002
|
| [13] | M. R. Islam, M. A. Kiber, Electrical impedance tomography imaging using Gauss-Newton algorithm, in 2014 International Conference on Informatics, Electronics & Vision (ICIEV), (2014), 1–4. https://doi.org/10.1109/ICIEV.2014.6850719 |
| [14] |
B. Jin, P. Maass, An analysis of electrical impedance tomography with applications to Tikhonov regularization, Control, Optim. Cal. Vari., 18 (2012), 1027–1048. https://doi.org/10.1051/cocv/2011193 doi: 10.1051/cocv/2011193
|
| [15] | A. Borsic, B. M. Graham, A. Adler, WRB Lionheart Total variation regularization in electrical impedance tomography, Total Var. Regularization Electric. Impedance Tomogr., 2007 (2007). |
| [16] |
T. K. Bera, S. K. Biswas, K. Rajan, J. Nagaraju, Projection error propagation-based regularization (PEPR) method for resistivity reconstruction in electrical impedance tomography (EIT), Measurement, 49 (2014), 329–350.https://doi.org/10.1016/j.measurement.2013.11.003 doi: 10.1016/j.measurement.2013.11.003
|
| [17] |
D. M. Nguyen, P. Qian, T. Barry, A. McEwan, Self-weighted NOSER-prior electrical impedance tomography using internal electrodes in cardiac radiofrequency ablation, Physiol. Meas., 40 (2019), 065006. https://doi.org/10.1088/1361-6579/ab1937 doi: 10.1088/1361-6579/ab1937
|
| [18] |
B. Sun, S. Yue, Z. Hao, Z. Cui, H. Wang, An improved tikhonov pegularization method for lung cancer monitoring using electrical impedance tomography, IEEE Sensors J., 19 (2019), 3049–3057. https://doi.org/10.1109/JSEN.2019.2892179 doi: 10.1109/JSEN.2019.2892179
|
| [19] |
B. Jin, P. Maass, Sparsity regularization for parameter identification problems, Inverse Probl., 28 (2012), 123001. https://doi.org/10.1088/0266-5611/28/12/123001 doi: 10.1088/0266-5611/28/12/123001
|
| [20] |
F. Margotti, Mixed gradient-Tikhonov methods for solving nonlinear ill-posed problems in Banach spaces, Inverse Probl., 32 (2016), 125012. https://doi.org/10.1088/0266-5611/32/12/125012 doi: 10.1088/0266-5611/32/12/125012
|
| [21] | D. Hu, K. Lu, Y. Yang, Image reconstruction for electrical impedance tomography based on spatial invariant feature maps and convolutional neural network, in 2019 IEEE International Conference on Imaging Systems and Techniques (IST), (2019), 1–6. https://doi.org/10.1109/IST48021.2019.9010151 |
| [22] |
T. A. Khan, S. H. Ling, Review on electrical impedance tomography: Artificial intelligence methods and its applications, Algorithms, 12 (2019), 88. https://doi.org/10.3390/a12050088 doi: 10.3390/a12050088
|
| [23] | S. W. Huang, H. M. Cheng, S. F. Lin, Improved imaging resolution of electrical impedance tomography using artificial neural networks for image reconstruction, in 2019 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), (2019), 1551–1554. https://doi.org/10.1109/EMBC.2019.8856781 |
| [24] |
H. Wang, K. Liu, Y. Wu, S. Wang, Z. Zhang, F. Li, et al., Image reconstruction for electrical impedance tomography using radial basis function neural network based on hybrid particle swarm optimization algorithm, IEEE Sensors J., 21 (2021), 1926–1934. https://doi.org/10.1109/JSEN.2020.3019309 doi: 10.1109/JSEN.2020.3019309
|
| [25] | T. Huuhtanen, A. Jung, Anomaly location detection with electrical impedance tomography using multilayer perceptrons, in 2020 IEEE 30th International Workshop on Machine Learning for Signal Processing (MLSP), (2020), 1–6. https://doi.org/10.1109/MLSP49062.2020.9231818 |
| [26] |
C. Tan, S. Lv, F. Dong, M. Takei, Image reconstruction based on convolutional neural network for electrical resistance tomography, IEEE Sensors J., 19 (2019), 196–204. https://doi.org/10.1109/JSEN.2018.2876411 doi: 10.1109/JSEN.2018.2876411
|
| [27] | Y. Gao, EIT-CDAE: A 2-D electrical impedance tomography image reconstruction method based on auto encoder technique, in 2019 IEEE Biomedical Circuits and Systems Conference (BioCAS), (2019), 1–4. https://doi.org/10.1109/BIOCAS.2019.8918979 |
| [28] |
S. J. Hamilton, A. Hauptmann, Deep D-bar: real-time electrical impedance tomography imaging with deep neural networks, IEEE Trans. Med. Imaging, 37 (2018), 2367–2377. https://doi.org/10.1109/TMI.2018.2828303 doi: 10.1109/TMI.2018.2828303
|
| [29] |
Z. Wei, D. Liu, X. Chen, Dominant-current deep learning scheme for electrical impedance tomography, IEEE Trans. Biomed. Eng., 66 (2019), 2546–2555. https://doi.org/10.1109/TBME.2019.2891676 doi: 10.1109/TBME.2019.2891676
|
| [30] | M. De Hoop, D. Huang, E. Qian, A. M. Stuart., The cost-accuracy trade-off in operator learning with neural networks, preprint, arXiv: 2203.13181. |
| [31] | D. Nganyu Tanyu, J. Ning, T. Freudenberg, N. Heilenkö tter, A. Rademacher, U. Iben, et al., Deep learning methods for partial differential equations and related parameter identification problems, preprint, arXiv: 2212.03130. |
| [32] | G. Huang, Y. Sun, L. Zhang, D. Sedra, K. Q. Weinberger, Deep networks with stochastic depth, preprint, arXiv: 1603.09382. |
| [33] |
M. Bakator, D. Radosav, Deep learning and medical diagnosis: a review of literature, Multimod. Technol. Interact., 2 (2018), 47. https://doi.org/10.1016/j.mri.2019.05.009 doi: 10.1016/j.mri.2019.05.009
|
| [34] | K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, in 2016 Proceedings of the IEEE conference on computer vision and pattern recognition, (2016), 770–778. |
| [35] | G. Huang, Z. Liu, L. Van Der Maaten, K. Q. Weinberger, Densely connected convolutional networks, in 2017 Proceedings of the IEEE conference on computer vision and pattern recognition, (2017), 4700–4708. |
| [36] |
P. J. Vauhkonen, M. Vauhkonen, T. Savolainen, J. P. Kaipio, Three-dimensional electrical impedance tomography based on the complete electrode model, IEEE Trans. Biomed. Eng., 46 (1999), 1150–1160. https://doi.org/10.1109/10.784147 doi: 10.1109/10.784147
|
| [37] |
M. Vauhkonen, W. R. B. Lionheart, L. M. Heikkinen, P. J. Vauhkonen, J. P. Kaipio, A MATLAB package for the EIDORS project to reconstruct two-dimensional EIT images, Physiol. Meas., 22 (2001), 107. https://doi.org/10.1088/0967-3334/22/1/314 doi: 10.1088/0967-3334/22/1/314
|
| [38] | C. Gabriel, Compilation of the dielectric properties of body tissues at RF and microwave frequencies, King's Coll London (United Kingdom) Dept of Physics, 1996. |
| [39] | D. P. Kingma, J. Ba, Adam: A method for stochastic optimization, preprint, arXiv: 1412.6980. |
| [40] |
D. Yang, G. Huang, B. Xu, X. Wang, Z. Wang, Z. Wei, A DSP-based EIT system with adaptive boundary voltage acquisition, IEEE Sensors J., 22 (2022), 5743–5754. https://doi.org/10.1109/JSEN.2022.3146372 doi: 10.1109/JSEN.2022.3146372
|
| [41] | C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, et al., Going deeper with convolutions, in 2015 Proceedings of the IEEE conference on computer vision and pattern recognition, (2015), 1–9. |
| [42] | C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, Z. Wojna, Rethinking the inception architecture for computer vision, in 2016 Proceedings of the IEEE conference on computer vision and pattern recognition, (2016), 2818–2826. |
| [43] | J. T. Springenberg, A. Dosovitskiy, T. Brox, M. Riedmiller, Striving for simplicity: The all convolutional net, preprint, arXiv: 1412.6806. |
| [44] |
D. Liu, Y. Zhao, A. K. Khambampati, A. Seppänen; J. Du, A parametric level set method for imaging multiphase conductivity using electrical impedance tomography, IEEE Trans. Comput. Imaging, 4 (2018), 552–561. https://doi.org/10.1109/TCI.2018.2863038 doi: 10.1109/TCI.2018.2863038
|
| [45] |
Y. Shi, X. Zhang, M. Wang, F. Fu, Z. Tian, An adaptive non-convex hybrid total variation regularization method for image reconstruction in electrical impedance tomography, Flow Meas. Instrum., 79 (2021), 101937. https://doi.org/10.1016/j.flowmeasinst.2021.101937 doi: 10.1016/j.flowmeasinst.2021.101937
|
| [46] | Y. Wu, T. Zhou, B. Chen, K. Liu, R. Wang, H. Pan, et al., Bayesian shape reconstruction using b-spline level set in electrical impedance tomography, IEEE Sensors J., 19 (2022), 19010–19019. https://doi.org/10.1109/JSEN.2022.3199436 |
| [47] |
Z. Chen, Z. Liu, L. Ai, S. Zhang, Y. Yang, Mask-guided spatial–temporal graph neural network for multifrequency electrical impedance tomography, IEEE Trans. Instrum. Meas., 71 (2022), 1–10. https://doi.org/10.1109/TIM.2022.3197804 doi: 10.1109/TIM.2022.3197804
|
| [48] | H. Zhang, Q. Wang, R. Zhang, X. Li, X. Duan, Y. Sun, et al., Image reconstruction for electrical impedance tomography (EIT) with improved wasserstein generative adversarial network (WGAN), IEEE Sensors J., 2022 (2022), forthcoming. https://doi.org/10.1109/JSEN.2022.3197663 |














Figures(15) / Tables(11)

Dan Yang, Shijun Li, Yuyu Zhao, Bin Xu, Wenxu Tian. An EIT image reconstruction method based on DenseNet with multi-scale convolution[J]. Mathematical Biosciences and Engineering, 2023, 20(4): 7633-7660. doi: 10.3934/mbe.2023329







 DownLoad:
DownLoad: