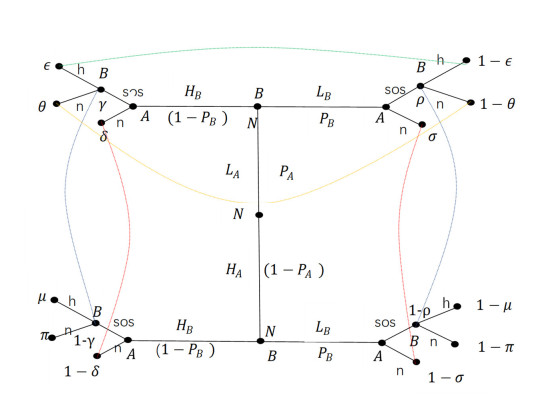
This study aims to link two related social psychology concepts, self-awareness and politeness, with human helping behavior and demonstrate it from the perspective of psychological game theory. By establishing a game theory model, and adding politeness and self-awareness as influencing factors, the Bayesian Nash equilibrium clarified people's help-seeking and help-giving behavior. As a result, we explained the relationship between politeness, self-awareness, and the willingness of the help seekers, as well as the helpers, and we can thus understand why some people do not seek help or give help. Specifically, on the one hand, from the perspective of help seekers, we found that people with a high level of self-awareness and politeness tend not to ask others for help. On the other hand, from the perspective of helpers, we found that people with a high level of self-awareness and politeness tend to help others. To the best of our knowledge, this is the first application of Bayesian Nash equilibrium based on psychological game theory in studying human help-seeking and help-giving behavior.
Citation: Huanhuan Guo, Biao Gao. Game theory analysis of self-awareness and politeness[J]. Mathematical Biosciences and Engineering, 2022, 19(10): 10493-10532. doi: 10.3934/mbe.2022491
This study aims to link two related social psychology concepts, self-awareness and politeness, with human helping behavior and demonstrate it from the perspective of psychological game theory. By establishing a game theory model, and adding politeness and self-awareness as influencing factors, the Bayesian Nash equilibrium clarified people's help-seeking and help-giving behavior. As a result, we explained the relationship between politeness, self-awareness, and the willingness of the help seekers, as well as the helpers, and we can thus understand why some people do not seek help or give help. Specifically, on the one hand, from the perspective of help seekers, we found that people with a high level of self-awareness and politeness tend not to ask others for help. On the other hand, from the perspective of helpers, we found that people with a high level of self-awareness and politeness tend to help others. To the best of our knowledge, this is the first application of Bayesian Nash equilibrium based on psychological game theory in studying human help-seeking and help-giving behavior.

| [1] | D. G. Myers, J. M. Twenge, Social Psychology, McGraw-Hill Education, New York, 2022. |
| [2] | J. A. Piliavin, Doing well by doing good: Benefits for the benefactor, in Flourishing: Positive Psychology and The Life Well-Lived, (2003), 227–247. https://doi.org/10.1037/10594-010 |
| [3] | J. A. Piliavin, D. E. Evans, P. Callero, Learning to "give to unnamed strangers": The process of commitment to regular blood donation, in The Development and Maintenance of Prosocial Behavior: International Perspectives, (1984), 471–492. |
| [4] |
J. Carden, R. J. Jones, J. Passmore, Defining self-awareness in the context of adult development: a systematic literature review, J. Manage. Educ., 46 (2022), 140–177. https://doi.org/10.1177/1052562921990065 doi: 10.1177/1052562921990065

|
| [5] | J. Carden, R. J. Jones, J. Passmore, An exploration of the role of coach training in developing self-awareness: a mixed methods study, Curr. Psychol., 2021. https://doi.org/10.1007/s12144-021-01929-8 |
| [6] | J. Carden, Self-Awareness and Coach Development, Ph.D thesis, University of Reading, 2022. Available from: https://centaur.reading.ac.uk/104446/. |
| [7] |
J. Carden, J. Passmore, R. J. Jones, Exploring the role of self-awareness in coach development: a grounded theory study, Int. J. Train. Dev., 26 (2022), 343–363. https://doi.org/10.1111/ijtd.12261 doi: 10.1111/ijtd.12261
|
| [8] |
A. Fenigstein, M. F. Scheier, A. H. Buss, Public and private self-consciousness: assessment and theory, J. Consult. Clin. Psychol., 43 (1975), 522–527. https://doi.org/10.1037/h0076760 doi: 10.1037/h0076760
|
| [9] |
W. J. Froming, C. S. Carver, Divergent influences of private and public self-consciousness in a compliance paradigm, J. Res. Pers., 15 (1981), 159–171. https://doi.org/10.1016/0092-6566(81)90015-5 doi: 10.1016/0092-6566(81)90015-5
|
| [10] |
P. D. Trapnell, J. D. Campbell, Private self-consciousness and the five-factor model of personality: distinguishing rumination from reflection, J. Pers. Soc. Psychol., 76 (1999), 284–304. https://doi.org/10.1037/0022-3514.76.2.284 doi: 10.1037/0022-3514.76.2.284
|
| [11] |
K. Mylonas, P. Veligekas, A. Gari, D. Kontaxopoulou, Development and psychometric properties of the scale for self-conscious assessment, Psychol. Rep., 111 (2012), 233–252. https://doi.org/10.2466/08.02.07.PR0.111.4.233-252 doi: 10.2466/08.02.07.PR0.111.4.233-252
|
| [12] |
L. E. Alden, M. Teschuk, K. Tee, Public self-awareness and withdrawal from social interactions, Cognit. Ther. Res., 16 (1992), 249–267. https://doi.org/10.1007/BF01183280 doi: 10.1007/BF01183280
|
| [13] |
K. White, M. Stackhouse, J. J. Argo, When social identity threat leads to the selection of identity-reinforcing options: the role of public self-awareness, Organ. Behav. Hum. Decis. Processes, 144 (2018), 60–73. https://doi.org/10.1016/j.obhdp.2017.09.007 doi: 10.1016/j.obhdp.2017.09.007
|
| [14] | M. Van Bommel, J. W. Van Prooijen, H. Elffers, P. A. Van Lange, Be aware to care: public self-awareness leads to a reversal of the bystander effect, J. Exp. Soc. Psychol., 48 (2012), 926–930. https://doi.org/10.1016/j.jesp.2012.02.011 |
| [15] |
R. K. Ratner, B. E. Kahn, The impact of private versus public consumption on variety seeking behavior, J. Consum. Res., 29 (2002), 246–257. https://doi.org/10.1086/341574 doi: 10.1086/341574
|
| [16] |
K. White, J. Peloza, Self-benefit versus other-benefit marketing appeals: their effectiveness in generating charitable support, J. Mark., 73 (2009), 109–124. https://doi.org/10.1509/jmkg.73.4.109 doi: 10.1509/jmkg.73.4.109
|
| [17] |
C. C. Yin, Y. C. Hsieh, H. C. Chiu, J. L. Yu, Dissatisfied with your choices? How to align online consumer's self-awareness, time pressure and self-consciousness, Eur. J. Mark., 55 (2021), 2367–2388. https://doi.org/10.1108/EJM-03-2020-0187 doi: 10.1108/EJM-03-2020-0187
|
| [18] |
S. Pfattheicher, J. Keller, The watching eyes phenomenon: the role of a sense of being seen and public self-awareness, Eur. J. Soc. Psychol., 45 (2015), 560–566. https://doi.org/10.1002/ejsp.2122 doi: 10.1002/ejsp.2122
|
| [19] |
V. H. Duval, S. Duval, R. Neely, Self-focus, felt responsibility, and helping behavior, J. Pers. Soc. Psychol., 37 (1979), 1769–1778. https://doi.org/10.1037/0022-3514.37.10.1769 doi: 10.1037/0022-3514.37.10.1769
|
| [20] |
M. Carlson, N. Miller, Explanation of the relation between negative mood and helping, Psychol. Bull., 102 (1987), 91–108. https://doi.org/10.1037/0033-2909.102.1.91 doi: 10.1037/0033-2909.102.1.91
|
| [21] |
F. X. Gibbons, R. A. Wicklund, Self-focused attention and helping behavior, J. Pers. Soc. Psychol., 43 (1982), 462–474. https://doi.org/10.1037/0022-3514.43.3.462 doi: 10.1037/0022-3514.43.3.462
|
| [22] |
C. S. Abbate, A. Isgró, R. A. Wicklund, S. Boca, A field experiment on perspective-taking, helping, and self-awareness, Basic Appl. Soc. Psychol., 28 (2006), 283–287. https://doi.org/10.1207/s15324834basp2803_7 doi: 10.1207/s15324834basp2803_7
|
| [23] |
C. W. Hoover, E. E. Wood, E. S. Knowles, Forms of social awareness and helping, J. Exp. Soc. Psychol., 19 (1983), 577–590. https://doi.org/10.1016/0022-1031(83)90017-3 doi: 10.1016/0022-1031(83)90017-3
|
| [24] |
A. P. Barbee, T. L. Rowatt, M. R. Cunningham, When a friend is in need: feelings about seeking, giving, and receiving social support, Handb. Commun. Emotion, 10 (1996), 281–301. https://doi.org/10.1016/B978-012057770-5/50012-6 doi: 10.1016/B978-012057770-5/50012-6
|
| [25] |
A. Nadler, D. Jeffrey, The role of threat to self-esteem and perceived control in recipient reaction to help: theory development and empirical validation, Adv. Exp. Soc. Psychol., 19 (1986), 81–122. https://doi.org/10.1016/S0065-2601(08)60213-0 doi: 10.1016/S0065-2601(08)60213-0
|
| [26] |
M. E. Schneider, B. Major, R. Luhtanen, J. Crocker, Social stigma and the potential costs of assumptive help, Pers. Soc. Psychol. Bull., 22 (1996), 201–209. https://doi.org/10.1177/0146167296222009 doi: 10.1177/0146167296222009
|
| [27] |
R. M. Shell, N. Eisenberg, A developmental model of recipients' reactions to aid, Psychol. Bull., 111 (1992), 413–433. https://doi.org/10.1037/0033-2909.111.3.413 doi: 10.1037/0033-2909.111.3.413
|
| [28] |
B. Fraser, Perspectives on politeness, J. Pragmatics, 14 (1990), 219–236. https://doi.org/10.1016/0378-2166(90)90081-N doi: 10.1016/0378-2166(90)90081-N
|
| [29] |
T. Holtgraves, Social psychology, cognitive psychology, and linguistic politeness, J. Politeness. Res-Lan., 1 (2005), 73–93. https://doi.org/10.1515/jplr.2005.1.1.73 doi: 10.1515/jplr.2005.1.1.73
|
| [30] | R. Brown, Politeness theory: exemplar and exemplary, in The Legacy of Solomon Asch: Essays in Cognition and Social Psychology, (1990), 23–38. |
| [31] | P. Brown, S. Levinson, Politeness: Some Universals in Language Usage, Cambridge University Press, England, 1987. https://doi.org/10.1017/CBO9780511813085 |
| [32] | E. Stephan, N. Liberman, Y. Trope, Politeness and psychological distance: a construal level perspective, J. Pers. Soc. Psychol., 98 (2010), 268–280. https://doi.org/10.1037/a0016960 |
| [33] |
A. M. Grant, D. M. Mayer, Good soldiers and good actors: prosocial and impression management motives as interactive predictors of affiliative citizenship behaviors, J. Appl. Psychol., 94 (2009), 900–912. https://doi.org/10.1037/a0013770 doi: 10.1037/a0013770
|
| [34] |
S. M. Rioux, L. A. Penner, The causes of organizational citizenship behavior: a motivational analysis, J. Appl. Psychol., 86 (2001), 1306–1314. https://doi.org/10.1037/0021-9010.86.6.1306 doi: 10.1037/0021-9010.86.6.1306
|
| [35] | V. K. Bohns, F. J. Flynn, Empathy gaps between helpers and help-seekers: implications for cooperation, Emerging Trends Soc. Behav. Sci., 2015. https://doi.org/10.1002/9781118900772.etrds0113 |
| [36] | S. K. N. Bendixsen, T. Wyller, Contested Hospitalities in a Time of Migration: Religious and Secular Counterspaces in the Nordic Region, Routledge, London, 2019. https://doi.org/10.4324/9780429273773 |
| [37] | T. Hashimoto, The amplifying effect of the norm of reciprocity on the relationship between sense of contribution and help-seeking, Jpn. J. Soc. Psychol., 31(2015), 35–45. |
| [38] |
R. Trestian, O. Ormond, G. M. Muntean, Game theory-based network selection: solutions and challenges, IEEE Commun. Surv. Tutorials, 14(2012), 1212–1231. https://doi.org/10.1109/SURV.2012.010912.00081 doi: 10.1109/SURV.2012.010912.00081
|
| [39] |
C. F. Camerer, Does strategy research need game theory? Strategic Manage. J., 12(1991), 137–152. https://doi.org/10.1002/smj.4250121010 doi: 10.1002/smj.4250121010
|
| [40] |
Y. Chen, S. X. Li, T. X. Liu, M. Shih, Which hat to wear? Impact of natural identities on coordination and cooperation, Games Econ. Behav., 84 (2014), 58–86. https://doi.org/10.1016/j.geb.2013.12.002 doi: 10.1016/j.geb.2013.12.002
|
| [41] |
J. C. Harsanyi, Games with incomplete information played by "Bayesian" players, I–III Part I. the basic model, Manage. Sci., 14 (1967), 159–182. https://doi.org/10.1287/mnsc.14.3.159 doi: 10.1287/mnsc.14.3.159
|
| [42] |
D. P. Myatt, C. C. Wallace, Adaptive play by idiosyncratic agents, Games Econ. Behav., 48 (2004), 124–138. https://doi.org/10.1016/j.geb.2003.07.004 doi: 10.1016/j.geb.2003.07.004
|
| [43] |
L. Huang, Q. Zhu, A dynamic games approach to proactive defense strategies against Advanced Persistent Threats in cyber-physical systems, Comput. Secur., 89(2020), 101660. https://doi.org/10.1016/j.cose.2019.101660 doi: 10.1016/j.cose.2019.101660
|
| [44] |
N. Kaldor, A classificatory note on the determinateness of equilibrium, Rev. Econ. Stud., 1 (1934), 122–136. https://doi.org/10.2307/2967618 doi: 10.2307/2967618
|
| [45] |
R. Gibbons, An introduction to applicable game theory, J. Econ. Perspect., 11 (1997), 127–149. https://doi.org/10.1257/jep.11.1.127 doi: 10.1257/jep.11.1.127
|
| [46] |
L. Almeida, J. Cruz, H. Ferreira, A. A. Pinto, Bayesian–Nash equilibria in theory of planned behaviour, J. Differ. Equations Appl., 17 (2011), 1085–1093. https://doi.org/10.1080/10236190902902331 doi: 10.1080/10236190902902331
|
| [47] |
T. Cheon, A. Iqbal, Bayesian Nash equilibria and bell inequalities, J. Phys. Soc. Jpn., 77 (2008), 684–706. https://doi.org/10.1143/JPSJ.77.024801 doi: 10.1143/JPSJ.77.024801
|
| [48] | M. R. Leary, The Curse of the Self: Self-awareness, Egotism, and the Quality of Human Life, Oxford University Press, 2007. |
| [49] |
M. A. Whatley, J. M. Webster, R. H. Smith, A. Rhodes, The effect of a favor on public and private compliance: how internalized is the norm of reciprocity? Basic Appl. Soc. Psychol., 21 (1999), 251–259. https://doi.org/10.1207/S15324834BASP2103_8 doi: 10.1207/S15324834BASP2103_8
|
























































Figures(57)

Huanhuan Guo, Biao Gao. Game theory analysis of self-awareness and politeness[J]. Mathematical Biosciences and Engineering, 2022, 19(10): 10493-10532. doi: 10.3934/mbe.2022491







 DownLoad:
DownLoad: