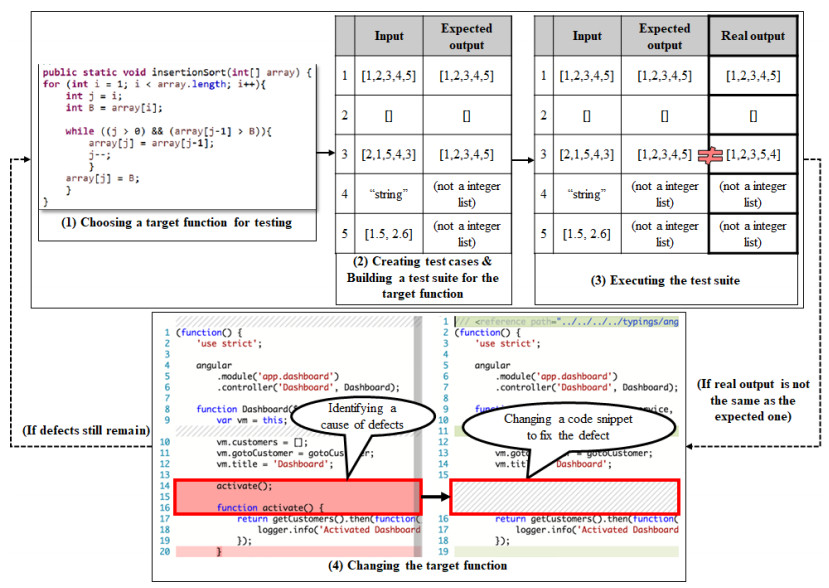
In software engineering, testing has long been a research area of software maintenance. Testing is extremely expensive, and there is no guarantee that all defects will be found within a single round of testing. Therefore, fixing defects that are not discovered by a single round of testing is important for reducing the test costs. During the software maintenance process, testing is conducted within the scope of a set of test cases called a test suite. Mutation testing is a method that uses mutants to evaluate whether the test cases of the test suite are appropriate. In this paper, an approach is proposed that uses the mutants of a mutation test to identify defects that are not discovered through a single round of testing. The proposed method simultaneously applies two or more mutants to a single program to define and record the relationships between different lines of code. In turn, these relationships are examined using the defects that were discovered by a single round of testing, and possible defects are recommended from among the recorded candidates. To evaluate the proposed method, a comparative study was conducted using the fault localization method, which is commonly employed in defect prediction, as well as the Defects4J defect prediction dataset, which is widely used in software defect prediction. The results of the evaluation showed that the proposed method achieves a better performance than seven other fault localization methods (Tarantula, Ochiai, Opt2, Barinel, Dstar2, Muse, and Jaccard).
Citation: Dong-Gun Lee, Yeong-Seok Seo. Identification of propagated defects to reduce software testing cost via mutation testing[J]. Mathematical Biosciences and Engineering, 2022, 19(6): 6124-6140. doi: 10.3934/mbe.2022286
In software engineering, testing has long been a research area of software maintenance. Testing is extremely expensive, and there is no guarantee that all defects will be found within a single round of testing. Therefore, fixing defects that are not discovered by a single round of testing is important for reducing the test costs. During the software maintenance process, testing is conducted within the scope of a set of test cases called a test suite. Mutation testing is a method that uses mutants to evaluate whether the test cases of the test suite are appropriate. In this paper, an approach is proposed that uses the mutants of a mutation test to identify defects that are not discovered through a single round of testing. The proposed method simultaneously applies two or more mutants to a single program to define and record the relationships between different lines of code. In turn, these relationships are examined using the defects that were discovered by a single round of testing, and possible defects are recommended from among the recorded candidates. To evaluate the proposed method, a comparative study was conducted using the fault localization method, which is commonly employed in defect prediction, as well as the Defects4J defect prediction dataset, which is widely used in software defect prediction. The results of the evaluation showed that the proposed method achieves a better performance than seven other fault localization methods (Tarantula, Ochiai, Opt2, Barinel, Dstar2, Muse, and Jaccard).

| [1] |
R. H. Ur, R. Mushtaq, A. Palwasha, K. Mukhtaj, I. Nadeem, K. H. Ullah, Making the sourcing decision of software maintenance and information technology, IEEE Access, 9 (2021), 11492-11510. https://doi.org/10.1109/ACCESS.2021.3051023 doi: 10.1109/ACCESS.2021.3051023

|
| [2] |
F.S. Ana M, M. R. Chaudron, M. Genero, An industrial case study on the use of UML in software maintenance and its perceived benefits and hurdles, Empirical Software Eng., 23 (2018), 3281-3345. https://doi.org/10.1007/s10664-018-9599-4 doi: 10.1007/s10664-018-9599-4
|
| [3] |
E. Vahid, O. Bushehrian, G. Robles, Task assignment to counter the effect of developer turnover in software maintenance: A knowledge diffusion model, Inf. Software Technol., 143 (2022), 106786. https://doi.org/10.1016/j.infsof.2021.106786 doi: 10.1016/j.infsof.2021.106786
|
| [4] |
K. Jang, W. Kim, A method of activity-based software maintenance cost estimation for package software, J. Supercomput., 78 (2021), 8151-8171. https://doi.org/10.1007/s11227-020-03610-6 doi: 10.1007/s11227-020-03610-6
|
| [5] |
T. Masateru, M. Akito, M. Kenichi, O. Sawako, O. Tomoki, Analysis of work efficiency and quality of software maintenance using cross-company dataset, IEICE Trans. Inf. Syst., 104 (2021), 76-90. https://doi.org/10.1587/transinf.2020MPP0004 doi: 10.1587/transinf.2020MPP0004
|
| [6] | K.W. Kim, Y. Son, Software weakness evaluation method for secure software development, in Proceedings on 2021 International Conferences on Multimedia Information Technology and Applications, (2021), 322-325. |
| [7] | C. Kim, D. Kim, H. Kang, Detecting defect in headlamp housing with machine learning techniques, in Proceedings on 2021 International Conferences on Multimedia Information Technology and Applications, (2021), 428-430. |
| [8] |
Y. J. Choi, Y. W. Lee, B. G Kim, Residual-based graph convolutional network for emotion recognition in conversation for smart Internet of Things, Big Data, 9 (2021), 279-288. https://doi.org/10.1089/big.2020.0274 doi: 10.1089/big.2020.0274
|
| [9] |
P. P. Roy, P. Kumar, B.G. Kim, An efficient sign language recognition (SLR) system using Camshift tracker and hidden Markov model (hmm), SN Comput. Sci., 2 (2021), 1-15. https://doi.org/10.1007/s42979-021-00485-z doi: 10.1007/s42979-021-00485-z
|
| [10] | B. George, F. Stefan, M. Michael, P. Josef, An early investigation of unit testing practices of component-based software systems, in 2020 IEEE Workshop on Validation, Analysis and Evolution of Software Tests, (2020), 12-15. https://doi.org/10.1109/VST50071.2020.9051632 |
| [11] | M. Alcon, H. Tabani, J. Abella, F. J. Cazorla, Enabling Unit Testing of Already-Integrated AI Software Systems: The Case of Apollo for Autonomous Driving, in 2021 24th Euromicro Conference on Digital System Design, (2021), 426-433. https://doi.org/10.1109/DSD53832.2021.00071 |
| [12] | D. Xavier, S. Panichella, A. Gambi, Java unit testing tool competition: Eighth round, in Proceedings of the IEEE/ACM 42nd International Conference on Software Engineering Workshops, (2020), 545-548. https://doi.org/10.1145/3387940.3392265 |
| [13] | T. Mengqing, J. Yan, W. Xiang, P. Rushu, Black-box approach for software testing based on fat-property, in MATEC Web of Conferences, 309 (2020), 02008. https://doi.org/10.1051/matecconf/202030902008 |
| [14] | S. Bo, Y. Shao, C. Chen, Study on the automated unit testing solution on the linux platform, in 2019 IEEE 19th International Conference on Software Quality, Reliability and Security Companion, (2019), 358-361. https://doi.org/10.1109/QRS-C.2019.00073 |
| [15] |
M. Héctor D, J. Gunel, S. Federica, T. Paolo, C. David, Diversifying focused testing for unit testing, ACM Trans. Software Eng. Method., 30 (2021), 1-24. https://doi.org/10.1145/3447265 doi: 10.1145/3447265
|
| [16] | X. Wang, L. Wei, B. Tao, S. Ji, A study about unit testing for embedded software of control system in nuclear power plant, in International Symposium on Software Reliability, Industrial Safety, Cyber Security and Physical Protection for Nuclear Power Plant, (2020), 157-163. https://doi.org/10.1007/978-981-16-3456-7_17 |
| [17] |
F. Anfal A, R. G. Alsarraj, A. M. Altaie, Software cost estimation based on dolphin algorithm, IEEE Access, 8 (2020), 75279-75287. https://doi.org/10.1109/ACCESS.2020.2988867 doi: 10.1109/ACCESS.2020.2988867
|
| [18] |
C. Sonia, H. Singh, Optimizing design of fuzzy model for software cost estimation using particle swarm optimization algorithm, Int. J. Comput. Intell. Appl., 19 (2020), 2050005. https://doi.org/10.1142/S1469026820500054 doi: 10.1142/S1469026820500054
|
| [19] |
A. Farrukh, A review of machine learning models for software cost estimation, Rev. Comput. Eng. Res., 6 (2019), 64-75. https://doi.org/10.18488/journal.76.2019.62.64.75 doi: 10.18488/journal.76.2019.62.64.75
|
| [20] |
K. Ishleen, N. G. Singh, W. Ritika, J. Vishal, B. Anupam, Neuro fuzzy—COCOMO Ⅱ model for software cost estimation, Int. J. Inf. Technol., 10 (2018), 181-187. https://doi.org/10.1007/s41870-018-0083-6 doi: 10.1007/s41870-018-0083-6
|
| [21] |
J. Miller, S. Wienke, M. Schlottke-Lakemper, M. Meinke, M. S. Müller, Applicability of the software cost model COCOMO Ⅱ to HPC projects, Int. J. Comput. Sci. Eng., 17 (2018), 283-296. https://doi.org/10.1504/IJCSE.2018.095849 doi: 10.1504/IJCSE.2018.095849
|
| [22] | A. Asheeri, M. Mohd, M. Hammad, Machine learning models for software cost estimation, in 2019 International Conference on Innovation and Intelligence for Informatics, Computing, and Technologies, (2019), 1-6. https://doi.org/10.1109/3ICT.2019.8910327 |
| [23] | A. Shaina, N. Mishra, Software cost estimation using artificial neural network, in Soft Computing: Theories and Applications, Springer, (2018), 51-58. https://doi.org/10.1007/978-981-10-5699-4_6 |
| [24] |
S. S. Pratap, V. P. Singh, A. K. Mehta, Differential evolution using homeostasis adaption based mutation operator and its application for software cost estimation, J. King Saud Univ.-Comput. Inf. Sci., 33 (2021), 740-752. https://doi.org/10.1016/j.jksuci.2018.05.009 doi: 10.1016/j.jksuci.2018.05.009
|
| [25] |
S. W. Ahmad, G. R. Bamnote, Whale-crow optimization (WCO)-based optimal regression model for software cost estimation, Sādhanā, 44 (2019), 1-15. https://doi.org/10.1007/s12046-019-1085-1 doi: 10.1007/s12046-019-1085-1
|
| [26] |
J. A. Khan, S. U. R. Khan, J. Iqbal, I. U. Rehman, Empirical investigation about the factors affecting the cost estimation in global software development context, IEEE Access, 9 (2021), 22274-22294. https://doi.org/10.1109/ACCESS.2021.3055858 doi: 10.1109/ACCESS.2021.3055858
|
| [27] | V. S. Desai, R. Mohanty, ANN-Cuckoo optimization technique to predict software cost estimation, in 2018 Conference on Information and Communication Technology, (2018), 1-6. https://doi.org/10.1109/INFOCOMTECH.2018.8722380 |
| [28] | R. C. A. Alves, D. A. G. Oliveira, G. A. N. Segura, C. B. Margi, The cost of software-defining things: A scalability study of software-defined sensor networks, IEEE Access 7 (2019), 115093-115108. https://doi.org/10.1109/ACCESS.2019.2936127 |
| [29] | D. G. Lee, Y. S. Seo, Testing cost reduction using nested mutation testing, in Proceedings on 2021 International Conferences on Multimedia Information Technology and Applications, (2021), 462-464. |
| [30] |
N. Li, M. Shepperd, Y. Guo, A systematic review of unsupervised learning techniques for software defect prediction, Inf. Software Technol., 122 (2020), 106287. https://doi.org/10.1016/j.infsof.2020.106287 doi: 10.1016/j.infsof.2020.106287
|
| [31] | F. Keller, L. Grunske, S. Heiden, A. Filieri, A. Hoorn, D. Lo, A critical evaluation of spectrum-based fault localization techniques on a large-scale software system, in 2017 IEEE International Conference on Software Quality, Reliability and Security, (2017), 114-125. https://doi.org/10.1109/QRS.2017.22 |
| [32] | The cost of poor software quality in the US: A 2020 report, Report of Proc. Consortium Inf. Softw. QualityTM, 2021. Available from: https://www.disputesoft.com/wp-content/uploads/2021/01/CPSQ-2020-Software-Report.pdf. |
| [33] | 'Fully weaponized' software bug poses a threat to Minecraft gamers and apps worldwide including Google, Twitter, Netflix, Spotify, Apple iCloud, Uber and Amazon, 2021. Available from: https://www.dailymail.co.uk/news/article-10297693/Global-race-patch-critical-computer-bug.html. |
| [34] |
P. Vitharana, Defect propagation at the project-level: results and a post-hoc analysis on inspection efficiency, Empirical Software Eng., 22 (2017), 57-79. https://doi.org/10.1007/s10664-015-9415-3 doi: 10.1007/s10664-015-9415-3
|
| [35] | Z. Wei, T. Shen, X. Chen, Just-in-time defect prediction technology based on interpretability technology, in 2021 8th International Conference on Dependable Systems and Their Applications (DSA), (2021), 78-89. https://doi.org/10.1109/DSA52907.2021.00017 |
| [36] | L. Ma, F. Zhang, J. Sun, M. Xue, B. Li, F. J. Xu, et al., Deepmutation: Mutation testing of deep learning systems, in 2018 IEEE 29th International Symposium on Software Reliability Engineering (ISSRE), (2018), 100-111. https://doi.org/10.1109/ISSRE.2018.00021 |
| [37] | G. Petrovic, M. Ivankovic, B. Kurtz, P. Ammann, R. Just, An industrial application of mutation testing: Lessons, challenges, and research directions, in 2018 IEEE International Conference on Software Testing, Verification and Validation Workshops (ICSTW), (2018), 47-53. https://doi.org/10.1109/ICSTW.2018.00027 |
| [38] | Q. Hu, L. Ma, X. Xie, B. Yu, Y. Liu, J. Zhao, DeepMutation++: A mutation testing framework for deep learning systems, in 2019 34th IEEE/ACM International Conference on Automated Software Engineering (ASE), (2019), 1158-1611. https://doi.org/10.1109/ASE.2019.00126 |
| [39] |
P. Gómez-Abajo, E. Guerra, J. D. Lara, M. G. Merayo, Wodel-Test: a model-based framework for language-independent mutation testing, Software Syst. Model., 20 (2021), 767-793. https://doi.org/10.1007/s10270-020-00827-0 doi: 10.1007/s10270-020-00827-0
|
| [40] | L. Chen, L. Zhang, Speeding up mutation testing via regression test selection: An extensive study, in 2018 IEEE 11th International Conference on Software Testing, Verification and Validation (ICST), (2018), 58-69. https://doi.org/10.1109/ICST.2018.00016 |
| [41] | N. Humbatova, G. Jahangirova, P. Tonella, DeepCrime: mutation testing of deep learning systems based on real faults, in Proceedings of the 30th ACM SIGSOFT International, Symposium on Software Testing and Analysis, (2021), 67-78. https://doi.org/10.1145/3460319.3464825 |
| [42] | K. Moran, M. Tufano, C. Bernal-Cárdenas, M. Linares-Vásquez, G. Bavota, C. Vendome, et al., MDroid+: A mutation testing framework for android, in 2018 IEEE/ACM 40th International Conference on Software Engineering: Companion (ICSE-Companion), (2018), 33-36. https://doi.org/10.1145/3183440.3183492 |
| [43] | Z. Li, H. Wu, J. Xu, X. Wang, L. Zhang, Z. Chen, MuSC: A tool for mutation testing of ethereum smart contract, in 2019 34th IEEE/ACM International Conference on Automated Software Engineering (ASE), (2019), 1198-1201. https://doi.org/10.1109/ASE.2019.00136 |
| [44] | D. Mao, L. Chen, L. Zhang, An extensive study on cross-project predictive mutation testing, in 2019 12th IEEE Conference on Software Testing, Validation and Verification (ICST), (2019), 160-171. https://doi.org/10.1109/ICST.2019.00025 |
| [45] | D. Cheng, C. Cao, C. Xu, X. Ma, Manifesting bugs in machine learning code: An explorative study with mutation testing, in 2018 IEEE International Conference on Software Quality, Reliability and Security (QRS), (2018), 313-324. https://doi.org/10.1109/QRS.2018.00044 |
| [46] | S. Lee, D. Binkley, R. Feldt, N. Gold, S. Yoo, Causal program dependence analysis, preprint, arXiv: 2104.09107. https://doi.org/10.48550/arXiv.2104.09107 |
| [47] | S. Oh, S. Lee, S. Yoo, Effectively sampling higher order mutants using causal effect, in 2021 IEEE International Conference on Software Testing, Verification and Validation Workshops, (2021), 19-24. https://doi.org/10.1109/ICSTW52544.2021.00017 |
| [48] |
X. Cai, Y. Niu, S. Geng, J. Zhang, Z. Cui, J. Li, et al., An under-sampled software defect prediction method based on hybrid multi-objective cuckoo search, Concurrency Comput.: Pract. Exper., 32 (2020), e5478. https://doi.org/10.1002/cpe.5478 doi: 10.1002/cpe.5478
|
| [49] | A. Rahman, J. Stallings, L. Williams, Defect prediction metrics for infrastructure as code scripts in DevOps, in Proceedings of the 40th International Conference on Software Engineering: Companion Proceeedings, (2018), 414-415. https://doi.org/10.1145/3183440.3195034 |
| [50] | A. Amar, P. C. Rigby, Mining historical test logs to predict bugs and localize faults in the test logs, in 2019 IEEE/ACM 41st International Conference on Software Engineering. (2019), 140-151. https://doi.org/10.1109/ICSE.2019.00031 |
| [51] |
P. Sangameshwar, B. Ravindran, Predicting software defect type using concept-based classification, Empirical Software Eng., 25 (2020), 1341-1378. https://doi.org/10.1142/S1469026820500054 doi: 10.1142/S1469026820500054
|
| [52] |
S. Wang, T. Liu, J. Nam, L. Tan, Deep semantic feature learning for software defect prediction, IEEE Trans. Software Eng., 46 (2018), 1267-1293. https://doi.org/10.1109/TSE.2018.2877612 doi: 10.1109/TSE.2018.2877612
|
| [53] |
X. Yin, L. Liu, H. Liu, Q. Wu, Heterogeneous cross-project defect prediction with multiple source projects based on transfer learning, Math. Biosci. Eng., 17 (2020), 1020-1040. https://doi.org/10.3934/mbe.2020054 doi: 10.3934/mbe.2020054
|
| [54] |
L. Qiao, X. Li, Q. Umer, P. Guo, Deep learning based software defect prediction, Neurocomputing, 385 (2020), 100-110. https://doi.org/10.1016/j.neucom.2019.11.067 doi: 10.1016/j.neucom.2019.11.067
|
| [55] |
F. Wu, X. Y. Jing, Y. Sun, J. Sun, L. Huang, F. Cui, et al., Cross-project and within-project semisupervised software defect prediction: A unified approach, IEEE Trans. Reliab., 67 (2018), 581-597. https://doi.org/10.1109/TR.2018.2804922 doi: 10.1109/TR.2018.2804922
|
| [56] |
D. L. Miholca, G. Czibula, I. G. Czibula, A novel approach for software defect prediction through hybridizing gradual relational association rules with artificial neural networks, Inf. Sci., 441 (2018), 152-170. https://doi.org/10.1016/j.ins.2018.02.027 doi: 10.1016/j.ins.2018.02.027
|
| [57] |
A. Majd, M. Vahidi-Asl, A. Khalilian, P. Poorsarvi-Tehrani, H. Haghighi, SLDeep: Statement-level software defect prediction using deep-learning model on static code features, Expert Syst. Appl., 147 (2020), 113156. https://doi.org/10.1016/j.eswa.2019.113156 doi: 10.1016/j.eswa.2019.113156
|
| [58] | G. G. Cabral, L. L. Minku, E. Shihab, S. Mujahid, Class imbalance evolution and verification latency in just-in-time software defect prediction, in 2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE), (2019), 666-676. https://doi.org/10.1109/ICSE.2019.00076 |
| [59] | A. Perez, R. Abreu, A. Deursen, A test-suite diagnosability metric for spectrum-based fault localization approaches, in 2017 IEEE/ACM 39th International Conference on Software Engineering, (2017), 654-664. https://doi.org/10.1109/ICSE.2017.66 |
| [60] | X. Li, W. Li, Y. Zhang, L. Zhang, Deepfl: Integrating multiple fault diagnosis dimensions for deep fault localization, in Proceedings of the 28th ACM SIGSOFT International Symposium on Software Testing and Analysis, (2019), 169-180. https://doi.org/10.1145/3293882.3330574 |
| [61] |
A. Zakari, S. P. Lee, R. Abreu, B. H. Ahmed, R. A. Rasheed, Multiple fault localization of software programs: A systematic literature review, Inf. Software Technol., 124 (2020), 106312. https://doi.org/10.1016/j.infsof.2020.106312 doi: 10.1016/j.infsof.2020.106312
|
| [62] | Z. Li, Y. Wu, Y. Liu, An empirical study of bug isolation on the effectiveness of multiple fault localization, in 2019 IEEE 19th International Conference on Software Quality, Reliability and Security (QRS), (2019), 18-25. https://doi.org/10.1109/QRS.2019.00016 |
| [63] | H. L. Ribeiro, R. P. A. de Araujo, M. L. Chaim, H. A. de Souza, F. Kon, Jaguar: A spectrum-based fault localization tool for real-world software, in 2018 IEEE 11th International Conference on Software Testing, Verification and Validation (ICST), (2018), 404-409. https://doi.org/10.1109/ICST.2018.00048 |
| [64] | K. Liu, A. Koyuncu, T. F. Bissyandé, D. Kim, J. Klein, Y. Le Traon, You cannot fix what you cannot find! An investigation of fault localization bias in benchmarking automated program repair systems, in 2019 12th IEEE conference on software testing, validation and verification (ICST), (2019), 102-113. https://doi.org/10.1109/ICST.2019.00020 |
| [65] |
D. Zou, J. Liang, Y. Xiong, M. D. Ernst, L. Zhang, An empirical study of fault localization families and their combinations, IEEE Trans. Software Eng., 47 (2019), 332-347. https://doi.org/10.1109/TSE.2019.2892102 doi: 10.1109/TSE.2019.2892102
|
| [66] |
J. Kim, J. Kim, E. Lee, Variable-based fault localization, Inf. Software Technol., 107 (2019), 179-191. https://doi.org/10.1016/j.infsof.2018.11.009 doi: 10.1016/j.infsof.2018.11.009
|
| [67] |
Y. Kim, S. Mun, S. Yoo, M. Kim, Precise learn-to-rank fault localization using dynamic and static features of target programs, ACM Trans. Software Eng. Method. (TOSEM), 28 (2019), 1-34. https://doi.org/10.1145/3345628 doi: 10.1145/3345628
|
| [68] | Defects4J, 2022. available from: https://github.com/rjust/defects4j. |



Figures(4) / Tables(4)

Dong-Gun Lee, Yeong-Seok Seo. Identification of propagated defects to reduce software testing cost via mutation testing[J]. Mathematical Biosciences and Engineering, 2022, 19(6): 6124-6140. doi: 10.3934/mbe.2022286







 DownLoad:
DownLoad: