This manuscript proposes a fast and efficient multiplicity adjustment that strictly controls the type I error for a family of high-dimensional chi-square distributed endpoints. The method is flexible and may be efficiently applied to chi-square distributed endpoints with any positive definite correlation structure. Controlling the family-wise error rate ensures that the results have a high standard of credulity due to the strict limitation of type I errors. Numerical results confirm that this procedure is effective at controlling familywise error, is far more powerful than utilizing a Bonferroni adjustment, is more computationally feasible in high-dimensional settings than existing methods, and, except for highly correlated data, performs similarly to less accessible simulation-based methods. Additionally, since this method controls the family-wise error rate, it provides protection against reproducibility issues. An application illustrates the use of the proposed multiplicity adjustment to a large scale testing example.
Citation: Amy Wagler, Melinda McCann. An efficient and flexible multiplicity adjustment for chi-square endpoints[J]. Mathematical Biosciences and Engineering, 2021, 18(5): 4971-4986. doi: 10.3934/mbe.2021253
This manuscript proposes a fast and efficient multiplicity adjustment that strictly controls the type I error for a family of high-dimensional chi-square distributed endpoints. The method is flexible and may be efficiently applied to chi-square distributed endpoints with any positive definite correlation structure. Controlling the family-wise error rate ensures that the results have a high standard of credulity due to the strict limitation of type I errors. Numerical results confirm that this procedure is effective at controlling familywise error, is far more powerful than utilizing a Bonferroni adjustment, is more computationally feasible in high-dimensional settings than existing methods, and, except for highly correlated data, performs similarly to less accessible simulation-based methods. Additionally, since this method controls the family-wise error rate, it provides protection against reproducibility issues. An application illustrates the use of the proposed multiplicity adjustment to a large scale testing example.

| [1] | R Core Team, R: A language and environment for statistical computing, R Found Stat. Comput., Vienna, Austria, 2019. http://www.R-project.org/. |
| [2] | K. S. Pollard, S. Dudoit, M. J. {van der Laan}, Multiple testing procedures: R multtest package and applications to Genomics, Bioinformatics and Computational Biology Solutions Using R and Bioconductor, Springer, 2005. |
| [3] |
T. Hothorn, F. Bretz, P. Westfall, Simultaneous inference in general parametric models, Biomet. J., 50 (2008), 346-363. doi: 10.1002/bimj.200810425

|
| [4] | C. C. Bartenschlager, J. O. Brunner, A new user specific multiple testing method for business applications: The SiMaFlex procedure, J. Stat. Plan Infer., 2021, Online. |
| [5] | Y. Benjamini, Y. Hochberg, Controlling the false discovery rate: A practical and powerful approach to multiple testing, J. Royal Stat. Soc. B., 57 (1995), 289-300. |
| [6] | Y. Benjamini, D. Yekutieli, The control of the false discovery rate in multiple testing under dependency, Ann. Stat., 29 (2001), 1165-1188. |
| [7] |
D. Hunter, An upper bound for the probability of a union, J. Appl. Probab., 13 (1976), 597-603. doi: 10.2307/3212481
|
| [8] | M. McCann, D. Edwards, A path length inequality for the multivariate-t distribution, with applications to multiple comparisons, J. Am. Stat. Assoc., 91 (1996), 211-216. |
| [9] |
D. Q. Naiman, Simultaneous confidence bounds in multiple regression using predictor variable constraints, J. Am. Stat. Assoc., 82 (1987), 214-219. doi: 10.1080/01621459.1987.10478422
|
| [10] | J. Sun, C. R. Loader, Simultaneous confidence bands for linear regression and smoothing, Ann. Stat., (1994), 1328-1345. |
| [11] |
K. J. Worsley, An improved Bonferroni inequality and applications, Biometrika, 69 (1982), 297-302. doi: 10.1093/biomet/69.2.297
|
| [12] |
M. Heo, A. C. Leon, Comparison of statistical methods for analysis of clustered binary observations, Stat. Med., 24 (2005), 911-923. doi: 10.1002/sim.1958
|
| [13] |
R. B. Arani, J. J. Chen, A power study of a sequential method of p-value adjustment for correlated continuous endpoints, J. Biopharm. Stat., 8 (1998), 585-598. doi: 10.1080/10543409808835262
|
| [14] |
S. James, The approximate multinormal probabilities applied to correlated multiple endpoints in clinical trials, Stat. Med., 10 (1991), 1123-1135. doi: 10.1002/sim.4780100712
|
| [15] | S. J. Pocock, N. L. Geller, A. A. Tsiatis, The analysis of multiple endpoints in clinical trials, Biometrics, (1987), 487-498. |
| [16] | P. C. O'Brien, Procedures for comparing samples with multiple endpoints, Biometrics, (1984), 1079-1087. |
| [17] | R. E. Tarone, A modified Bonferroni method for discrete data, Biometrics, (1990), 515-522. |
| [18] | P. H. Westfall, R. D. Tobias, Multiple testing of general contrasts, J. Am. Stat. Assoc., 92 (2007), 299-306. |
| [19] |
P. H. Westfall, J. F. Troendle, Multiple testing with minimal assumptions, Biomet. J., 50 (2008), 745-755. doi: 10.1002/bimj.200710456
|
| [20] |
W. Pan, Asymptotic tests of association with multiple SNPs in linkage disequilibrium, Genet. Epidemiol., 33 (2009), 497-507. doi: 10.1002/gepi.20402
|
| [21] |
J. Stange, N. Loginova, T. Dickhaus, Computing and approximating multivariate chi-square probabilities, J. Stat. Comput. Sim., 86 (2016), 1233-1247. doi: 10.1080/00949655.2015.1058798
|
| [22] | S. Dudoit, M. J. van der Laan, Multiple tests of association with biological annotation metadata, in Multiple Testing Procedures with Applications to Genomics, Springer Series in Statistics, Springer, (2008), 413-476. |
| [23] |
K. Wright, W. J. Kennedy, Self-validated Computations for the Probabilities of the Central Bivariate Chi-square Distribution and a Bivariate F Distribution, J. Stat. Comput. Sim., 72 (2002), 63-75. doi: 10.1080/00949650211422
|
| [24] | P. R. Krishnaiah (Ed.), Handbook of statistics, Motilal Banarsidass Publisher, (1980). |
| [25] |
J. B. Kruskal, On the shortest spanning subtree of a graph and the traveling salesman problem, Proc. Am. Math. Soc., 7 (1956), 48-50. doi: 10.1090/S0002-9939-1956-0078686-7
|
| [26] |
A. K. Bera, Y. Bilias, Rao's score, Neyman's C() and Silvey's LM tests: An essay on historical developments and some new results, J. Stat. Plan Infer., 97 (2001), 9-44. doi: 10.1016/S0378-3758(00)00343-8
|
| [27] |
F. Guinot, M. Szafranski, C. Ambroise, F. Samson, Learning the optimal scale for GWAS through hierarchical SNP aggregation, BMC Bioinform., 19 (2018), 1-14. doi: 10.1186/s12859-017-2006-0
|
| [28] |
G. Lovison, On Rao score and Pearson $\chi^{2}$ statistics in generalized linear models, Stat. Papers, 46 (2005), 555-574. doi: 10.1007/BF02763005
|
| [29] | D. Pregibon, Score tests in GLIM with applications, In GLIM82: Proceedings of the International Conference on Generalized Linear Models, R Gilchrist (ed.), Lec. Notes Stat., 14, Springer, New York, (1982), 87-97. |
| [30] | G. K. Smyth, Pearson's goodness of fit statistic as a score test statistic, Science and Statistics: A Festschrift for Terry Speed, D. R. Goldstein (ed.), IMS Lec Notes., 40, Institute of Mathematical Statistics, Beachwood, Ohio, (2003), 115-126. http://www.statsci.org/smyth/pubs/goodness.pdf. |
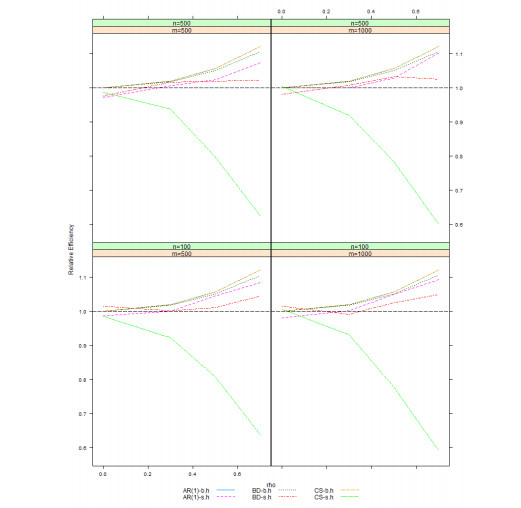
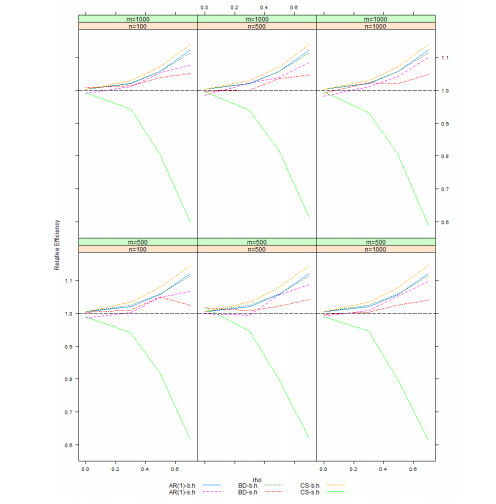
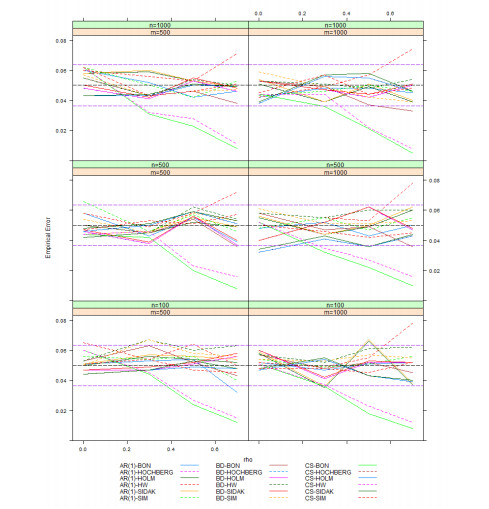
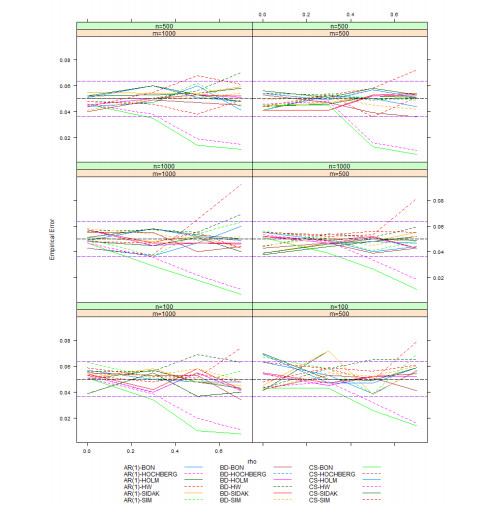
Figures(4) / Tables(1)

Amy Wagler, Melinda McCann. An efficient and flexible multiplicity adjustment for chi-square endpoints[J]. Mathematical Biosciences and Engineering, 2021, 18(5): 4971-4986. doi: 10.3934/mbe.2021253







 DownLoad:
DownLoad: