Citation: Tongqian Zhang, Ning Gao, Tengfei Wang, Hongxia Liu, Zhichao Jiang. Global dynamics of a model for treating microorganisms in sewage by periodically adding microbial flocculants[J]. Mathematical Biosciences and Engineering, 2020, 17(1): 179-201. doi: 10.3934/mbe.2020010

| [1] | Agricultural Statistics Annual, United States Department of Agriculture, 2017. Available from: https://www.nass.usda.gov/Publications/Ag_Statistics/2017/index.php. |
| [2] | Per Capita Consumption of Poultry and Livestock, 1960 to Forecast 2020, in Pounds, National Chicken Council, 2019. Available from: https://www.nationalchickencouncil.org/about-the-industry/statistics/per-capita-consumption-of-poultry-\and-livestock-1965-to-estimated-2012-in-pounds/. |
| [3] | T. Zheng, P. Li, X. Ma, et al., Pilot-scale multi-level biological contact oxidation system on the treatment of high concentration poultry manure wastewater, Process Saf. Environ., 120 (2018), 187-194. |
| [4] | K. Yetilmezsoy, F. Ilhan, Z. Sapci-Zengin, et al., Decolorization and COD reduction of UASB pretreated poultry manure wastewater by electrocoagulation process: A post-treatment study, J. Hazard. Mater., 162 (2009), 120-132. |
| [5] | R. Rajagopal and D. I. Massé, Start-up of dry anaerobic digestion system for processing solid poultry litter using adapted liquid inoculum, Process Saf. Environ., 102 (2016), 495-502. |
| [6] |
R. K. Upadhyay, K. Ranjit, J. Datta, et al., Emergence of spatial patterns in a damaged diffusive eco-epidemiological system, Internat. J. Bifur. Chaos., 28 (2018), 1830028. doi: 10.1142/S0218127418300288

|
| [7] | W. Zhang, Y. Wei and Y. Jin, Full-scale processing by anaerobic baffle reactor, sequencing batch reactor, and sand filter for treating high-salinity wastewater from offshore oil rigs, Processes, 6 (2018). |
| [8] | T. Zhang, Global analysis of continuous flow bioreactor and membrane reactor models with death and maintenance, J. Math. Chem., 50 (2012), 2239-2247. |
| [9] | T. Zhang, Z. Chen and M. Han, Dynamical analysis of a stochastic model for cascaded continuous flow bioreactors, J. Math. Chem., 52 (2014), 1441-1459. |
| [10] | Z. Jiang, X. Bi, T. Zhang, et al., Global Hopf bifurcation of a delayed phytoplankton-zooplankton system considering toxin producing effect and delay dependent coefficient, Math. Biosci. Eng., 16 (2019), 3807-3829. |
| [11] |
S. Biggs, M. Habgood, G. J. Jameson, et al., Aggregate structures formed via a bridging flocculation mechanism, Chem. Eng. J., 80 (2000), 13-22. doi: 10.1016/S1383-5866(00)00072-1
|
| [12] | M. Hjorth and B. U. Jørgensen, Polymer flocculation mechanism in animal slurry established by charge neutralization, Water Res., 46 (2012), 1045-1051. |
| [13] | P. Sun, C. Hui, N. Bai, et al., Revealing the characteristics of a novel bioflocculant and its flocculation performance in Microcystis aeruginosa removal, Sci Rep., 5 (2015), 17465. |
| [14] | T. Holst, N. O. G Jørgensen, C. Jørgensen, et al., Degradation of microcystin in sediments at oxic and anoxic, denitrifying conditions, Water Res., 37 (2003), 4748-4760. |
| [15] | C. Butterfield, Studies of sewage purification: ii. a zooglea-forming bacterium isolated from activated sludge, Public Health Rep., 50 (1935), 671-684. |
| [16] | J. Chattopadhyay, R. Sarkar and A. El Abdllaoui, Conditions for production of microbial cell flocculant by aspergillus sojae AJ7002, Agric. Biol. Chem., 40 (1976), 1341-1347. |
| [17] | H. Takagi and K. Kadowaki, Purification and chemical properties of a flocculant produced by paecilomyces, Agric. Biol. Chem., 49 (1985), 3159-3164. |
| [18] | R. Kurane, K. Toeda, K. Takeda, et al., Culture conditions for production of microbial flocculant by rhodococcus erythropolis, Agric. Biol. Chem., 50 (1986), 2309-2313. |
| [19] | H. Salehizadeh and S. Shojaosadati, Isolation and characterisation of a bioflocculant produced by Bacillus firmus, Biotechnol. Lett., 24 (2002), 35-40. |
| [20] | Z. Zhang, S. Xia, J. Zhao, et al., Characterization and flocculation mechanism of high efficiency microbial flocculant TJ-F1 from proteus mirabilis, Colloid. Surface B., 75 (2010), 247-251. |
| [21] | K. Song, W. Ma, S. Guo, et al., A class of dynamic models describing microbial flocculant with nutrient competition and metabolic products in wastewater treatment, Adv. Difference Equ., 2018 (2018), 33. |
| [22] | K. Song, W. Ma, S. Guo, et al., Global behavior of a dynamic model with biodegradation of microcystins, J. Appl. Anal. Comput., 9 (2019), 1261-1276. |
| [23] | K. Song, T. Zhang and W. Ma, Nontrivial periodic solution of a stochastic non-autonomous model with biodegradation of microcystins, Appl. Math. Lett., 94 (2019), 87-93. |
| [24] | S. Guo and W. Ma, Global dynamics of a microorganism flocculation model with time delay, Commun. Pure Appl. Anal., 16 (2017), 1883-1891. |
| [25] | S. Guo, W. Ma and X. Zhao, Global dynamics of a time-delayed microorganism flocculation model with saturated functional responses, J. Dynam. Differential Equations, 30 (2018), 1247-1271. |
| [26] | M. Galle and C. Jungen, Discontinuous sewage treatment process and small installation for carrying out this process, EP 2004. |
| [27] | J. Fleischer, K. Schlafmann, R. Otchwemah, et al., Elimination of enteroviruses, other enteric viruses, F-specific coliphages, somatic coliphages and E. coli in four sewage treatment plants of southern Germany, J. Water. Supply: Res. T., 49 (2000), 127-138. |
| [28] | T. Hsu, T. Meadows, L. Meadows, et al., Growth on Two Limiting Essential Resources in a Self-Cycling Fermentor, Math. Biosci. Eng., 16 (2018), 78-100. |
| [29] | M. Mohajerani, M. Mehrvar and F. Ein-Mozaffari, Recent Achievements in Combination of Ultrasonolysis and Other Advanced Oxidation Processes for Wastewater Treatment, Int. J. Chem. React. Eng., 8 (2010). |
| [30] | T. Zhang, T. Zhang and X. Meng, Stability analysis of a chemostat model with maintenance energy, Appl. Math. Lett., 68 (2017), 1-7. |
| [31] |
T. Zhang, X. Liu, X. Meng, et al., Spatio-temporal dynamics near the steady state of a planktonic system, Comput. Math. Appl., 75 (2018), 4490-4504. doi: 10.1016/j.camwa.2018.03.044
|
| [32] | T. Zhang, W. Ma, X. Meng, et al., Periodic solution of a prey-predator model with nonlinear state feedback control, Appl. Math. Comput., 266 (2015), 95-107. |
| [33] | H. Zhang, P. Georgescu and L. Zhang, Periodic patterns and Pareto efficiency of state dependent impulsive controls regulating interactions between wild and transgenic mosquito populations, Commun. Nonlinear Sci. Numer. Simul., 31 (2016), 83-107. |
| [34] | H. Qi, X. Meng and T. Feng, Dynamics analysis of a stochastic non-autonomous one-predatortwo-prey system with Beddington-DeAngelis functional response and impulsive perturbations, Adv. Difference Equ., 2019 (2019), 235. |
| [35] | Y. Li, H. Cheng, J. Wang, et al., Dynamic analysis of unilateral diffusion Gompertz model with impulsive control strategy, Adv. Difference Equ., 2018 (2018), 32. |
| [36] | T. Zhang, W. Ma and X. Meng, Global dynamics of a delayed chemostat model with harvest by impulsive flocculant input, Adv. Difference Equ., 2017 (2017), 115. |
| [37] | B. Liu, Y. Zhang and L. Chen, The dynamical behaviors of a Lotka-Volterra predator-prey model concerning integrated pest management, Nonlinear Anal. Real World Appl., 6 (2005), 227-243. |
| [38] | G. Liu, Z. Chang and X. Meng, Asymptotic analysis of impulsive dispersal predator-prey systems with Markov switching on finite-state space, J. Funct. Spaces, 2019 (2019), 8057153. |
| [39] | J. Jiao, S. Cai and L. Chen, Analysis of a stage-structured predator-prey system with birth pulse and impulsive harvesting at different moments, Nonlinear Anal. Real World Appl., 12 (2011), 2232-2244. |
| [40] | M. Chi and W. Zhao, Dynamical Analysis of Two-Microorganism and Single Nutrient Stochastic Chemostat Model with Monod-Haldane Response Function, Complexity, 2019 (2019), 8719067. |
| [41] | X. Zhuo, Global attractability and permanence for a new stage-structured delay impulsive ecosystem, J. Appl. Anal. Comput., 8 (2018), 457-470. |
| [42] | J. Wang, H. Cheng, Y. Li, et al., The geometrical analysis of a predator-prey model with multi-state dependent impulsive, J. Appl. Anal. Comput., 8 (2018), 427-442. |
| [43] | Z. Jiang, W. Zhang, J. Zhang, et al., Dynamical analysis of a phytoplankton-zooplankton system with harvesting term and holling Ⅲ functional response, Internat. J. Bifur. Chaos., 28 (2018), 1850162. |
| [44] | S. Yuan and T. Zhang, Dynamics of a plasmid chemostat model with periodic nutrient input and delayed nutrient recycling, Nonlinear Anal. Real World Appl., 13 (2012), 2104-2119. |
| [45] | X. Meng, L. Wang and T. Zhang, Global dynamics analysis of a nonlinear impulsive stochastic chemostat system in a polluted environment, J. Appl. Anal. Comput., 6 (2016), 865-875. |
| [46] | J. Gao, B. Shen, E. Feng, et al., Modelling and optimal control for an impulsive dynamical system in microbial fed-batch culture, J. Comput. Appl. Math., 32 (2013), 275-290. |
| [47] | S. Sun, Y. Sun, G. Zhang, et al., Dynamical behavior of a stochastic two-species Monod competition chemostat model, in Appl. Math. Comput., 298 (2017), 153-170. |
| [48] | S. Zhang, X. Meng, T. Feng, et al., Dynamics analysis and numerical simulations of a stochastic non-autonomous predator-prey system with impulsive effects, Nonlinear Anal. Hybrid Syst., 26 (2017), 19-37. |
| [49] | Z. Li, L. Chen and Z. Liu, Periodic solution of a chemostat model with variable yield and impulsive state feedback control, in Appl. Math. Model., 36 (2012), 1255-1266. |
| [50] | M. Chi and W. Zhao, Dynamical analysis of multi-nutrient and single microorganism chemostat model in a polluted environment, Adv. Difference Equ., 2018 (2018), 120. |
| [51] | K. Sun, Y. Tian, L. Chen, et al., Nonlinear modelling of a synchronized chemostat with impulsive state feedback control, Math. Comput. Model., 52 (2010), 227-240. |
| [52] | H. Guo and L. Chen, Periodic solution of a chemostat model with Monod growth rate and impulsive state feedback control, J. Theoret. Biol., 260 (2009), 502-509. |
| [53] | K. Liu, T. Zhang and L. Chen, State-dependent pulse vaccination and therapeutic strategy in an SI epidemic model with nonlinear incidence rate, Comput. Math. Methods Med., 2019 (2019), Article ID 3859815, 10 pages. |
| [54] | T. Zhang, X. Meng, Y. Song, et al., A stage-structured predator-prey SI model with disease in the prey and impulsive effects, Math. Model. Anal., 18 (2013), 505-528. |
| [55] | S. Gao, L. Luo, S. Yan, et al., Dynamical behavior of a novel impulsive switching model for HLB with seasonal fluctuations, Complexity, 2018 (2018), 11 pages. |
| [56] | Y. Song, A. Miao, T. Zhang, et al., Extinction and persistence of a stochastic SIRS epidemic model with saturated incidence rate and transfer from infectious to susceptible, Adv. Difference Equ., 2018 (2018), 293. |
| [57] | X. Fan, Y. Song and W. Zhao, Modeling cell-to-cell spread of HIV-1 with nonlocal infections, Complexity, 2018 (2018), 2139290. |
| [58] | N. Gao, Y. Song, X. Wang, et al., Dynamics of a stochastic SIS epidemic model with nonlinear incidence rates, Adv. Difference Equ., 2019 (2019), 41. |
| [59] | Z. Bai, X. Dong and C. Yin, Existence results for impulsive nonlinear fractional differential equation with mixed boundary conditions, Bound. Value Probl., 2016 (2016), 63. |
| [60] | G. Li, W. Ling and C. Ding, A new comparison principle for impulsive functional differential equations, Discrete Dyn. Nat. Soc., (2015), 139828. |
| [61] | Z. Lü, Y. Zheng and L. Zhang, Razumikhin type boundedness theorems in terms of two measures for impulsive integro-differential systems, Acta. Math. Appl. Sin-E, 30 (2014), 1007-1016. |
| [62] | D. Bainov and P. Simeonov, Systems with Impulse Effect: Stability, Theory, and Applications, Ellis Horwood, Chichester, 1989. |
| [63] | V. Lakshmikantham, D. Bainov and P. Simeonov, Theory of Impulsive Differential Equations, Vol. 6, World Scientific, Singapore, 1989. |
| [64] | V. Nemytskii and V. Stepanov, Qualitative Theory of Differential Equations, Vol. 22, Courier Dover Publications, New York, 1989. |
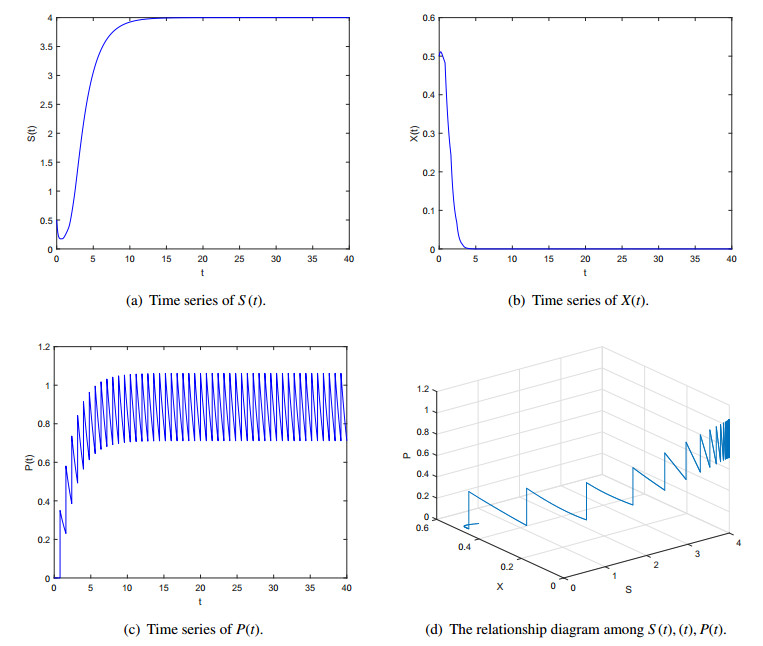
Figures(5) / Tables(1)

Tongqian Zhang, Ning Gao, Tengfei Wang, Hongxia Liu, Zhichao Jiang. Global dynamics of a model for treating microorganisms in sewage by periodically adding microbial flocculants[J]. Mathematical Biosciences and Engineering, 2020, 17(1): 179-201. doi: 10.3934/mbe.2020010







 DownLoad:
DownLoad: