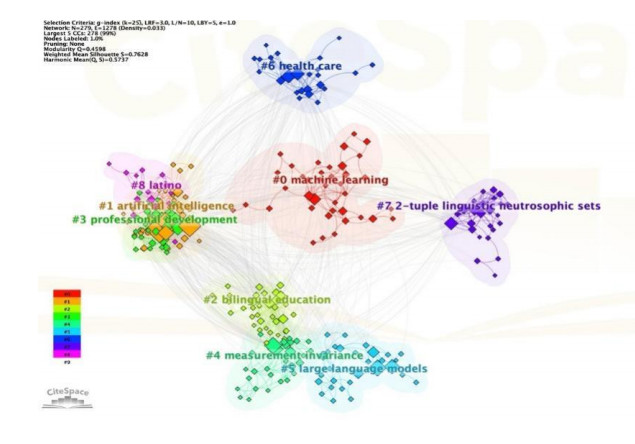
The study of Large Language Models (LLMs), as an interdisciplinary discipline involving multiple fields such as computer science, artificial intelligence, and linguistics, has diverse collaborations within its field. In this study, papers related to LLMs in the SSCI and SCI sub-collections of the Web of Science core database from January 2020 to April 2024 are selected, and a mixed linear regression model is used to assess the impact of scientific collaborations on the application of LLMs. On this basis, the paper further considers factors such as financial support and dominant countries to deeply explore the heterogeneous impact of scientific collaborations on the application of LLMs. The findings show that (1) excessive involvement of academic institutions limits the research and application of LLMs, and the number of authors does not have a significant effect on the application of LLMs; (2) with or without financial support, the role played by scientific collaborations in the application of LLMs does not significantly change; and (3) differences in the dominant countries of scientific collaborations have a slightly heterogeneous effect on the role of LLMs applications, which are mainly reflected in the number of collaborators.
Citation: Suyan Tan, Yilin Guo. A study of the impact of scientific collaboration on the application of Large Language Model[J]. AIMS Mathematics, 2024, 9(7): 19737-19755. doi: 10.3934/math.2024963
The study of Large Language Models (LLMs), as an interdisciplinary discipline involving multiple fields such as computer science, artificial intelligence, and linguistics, has diverse collaborations within its field. In this study, papers related to LLMs in the SSCI and SCI sub-collections of the Web of Science core database from January 2020 to April 2024 are selected, and a mixed linear regression model is used to assess the impact of scientific collaborations on the application of LLMs. On this basis, the paper further considers factors such as financial support and dominant countries to deeply explore the heterogeneous impact of scientific collaborations on the application of LLMs. The findings show that (1) excessive involvement of academic institutions limits the research and application of LLMs, and the number of authors does not have a significant effect on the application of LLMs; (2) with or without financial support, the role played by scientific collaborations in the application of LLMs does not significantly change; and (3) differences in the dominant countries of scientific collaborations have a slightly heterogeneous effect on the role of LLMs applications, which are mainly reflected in the number of collaborators.

| [1] | J. Liu, D. Shen, Y. Zhang, W. B. Dolan, L. Carin, W. Chen, What makes good in-context examples for GPT-3? Proceedings of Deep Learning Inside Out (DeeLIO 2022): The 3rd Workshop on Knowledge Extraction and Integration for Deep Learning Architectures, 3 (2022), 100–114. https://doi.org/10.18653/v1/2022.deelio-1.10 |
| [2] |
S. Karan, S. Azizi, T. Tu, S. S. Mahdavi, J. Wei, H. W. Chung, et al., Large Language Model encode clinical knowledge, Nature, 620 (2023), 172–180. https://doi.org/10.1038/s41586-023-06291-2 doi: 10.1038/s41586-023-06291-2

|
| [3] |
A. Laios, G. Theophilou, J. D. De, E. Kalampokis, The future of AI in ovarian cancer research: the Large Language Model perspective, Cancer Control, 30 (2023), 10732748231197915. https://doi.org/10.1177/10732748231197915 doi: 10.1177/10732748231197915
|
| [4] |
S. Ali, P. Chourasia, M. Patterson, When protein structure embedding meets Large Language Model, Genes, 15 (2024), 25. https://doi.org/10.3390/genes15010025 doi: 10.3390/genes15010025
|
| [5] |
E. Dotan, G. Jaschek, T. Pupko, Y. Belinkov, Effect of tokenization on transformers for biological sequences, Bioinformatics, 40 (2024), 196. https://doi.org/10.1093/bioinformatics/btae196 doi: 10.1093/bioinformatics/btae196
|
| [6] |
G. Leng, Challenge, integration, and change: ChatGPT and future anatomical education, Med. Educ. Online, 1 (2024), 2304973. https://doi.org/10.1080/10872981.2024.2304973 doi: 10.1080/10872981.2024.2304973
|
| [7] |
M. L. Tsai, C. W. Ong, C. L. Chen, Exploring the use of Large Language Model (LLMs) in chemical engineering education: building core course problem models with Chat-GPT, Educ. Chem. Eng., 3 (2023), 71–95. https://doi.org/10.1016/j.ece.2023.05.001 doi: 10.1016/j.ece.2023.05.001
|
| [8] |
S. Griewing, N. Gremke, U. Wagner, M. Lingenfelder, S. Kuhn, J. Boekhoff, Challenging ChatGPT3.5 in senology–An assessment of concordance with breast cancer tumor board decision making, J. Pers. Med., 10 (2023), 1502. https://doi.org/10.3390/jpm13101502 doi: 10.3390/jpm13101502
|
| [9] |
D. Schillinger, R. Balyan, S. A. Crossley, D. S. McNamara, J. Y. Liu, A. J. Karter, Employing computational linguistics techniques to identify limited patient health literacy: findings from the ECLIPPSE study, Health Serv. Res., 1 (2020), 132–144. https://doi.org/10.1111/1475-6773.13560 doi: 10.1111/1475-6773.13560
|
| [10] |
I. R. Indran, P. Paramanathan, N. Gupta, N. Mustafa, Twelve tips to leverage AI for efficient and effective medical question generation: a guide for educators using Chat GPT, Med. Teach., 2023 (2023), 2294703. https://doi.org/10.1080/0142159X.2023.2294703 doi: 10.1080/0142159X.2023.2294703
|
| [11] |
C. B. Divito, B. M. Katchikian, J. E. Gruenwald, J. M. Burgoon, The tools of the future are the challenges of today: the use of ChatGPT in problem-based learning medical education, Med. Teach., 3 (2024), 320–322. https://doi.org/10.1080/0142159X.2023.2290997 doi: 10.1080/0142159X.2023.2290997
|
| [12] |
Y. Wang, K. Yan, Machine learning-based quantitative trading strategies across different time intervals in the American market, Quant. Financ. Econ., 4 (2023), 569–594. https://doi.org/10.3934/QFE.2023028 doi: 10.3934/QFE.2023028
|
| [13] |
K. Amin, P. Khosla, R. Doshi, S. Chheang, H. P. Forman, Artificial intelligence to improve patient understanding of radiology reports, Yale J. Biol. Med., 3 (2023), 407–414. https://doi.org/10.59249/NKOY5498 doi: 10.59249/NKOY5498
|
| [14] |
S. Luo, W. Lei, P. Hou, Impact of artificial intelligence technology innovation on total factor productivity: an empirical study based on provincial panel data in China, Natl. Account. Rev., 2 (2024), 172–194. https://doi.org/10.3934/NAR.2024008 doi: 10.3934/NAR.2024008
|
| [15] |
A. Guleria, K. Krishan, V. Sharma, T. Kanchan, ChatGPT: ethical concerns and challenges in academics and research, J. Infect. Dev. Ctries, 9 (2023), 1292–1299. https://doi.org/10.3855/jidc.18738 doi: 10.3855/jidc.18738
|
| [16] |
S. Mestiri, Credit scoring using machine learning and deep learning-based models, Data Sci. Financ. Econ., 2 (2024), 236–248. https://doi.org/10.3934/DSFE.2024009 doi: 10.3934/DSFE.2024009
|
| [17] |
P. Maddigan, T. Susnjak, Chat2VIS: generating data visualizations via natural language using ChatGPT, Codex and GPT-3 Large Language Model, IEEE Access, 11 (2023), 45181–45193. https://doi.org/10.1109/ACCESS.2023.3274199 doi: 10.1109/ACCESS.2023.3274199
|
| [18] |
S. Milano, J. A. McGrane, S. Leonelli, Large Language Model challenge the future of higher education, Nat. Mach. Intell., 4 (2023), 333–334. https://doi.org/10.1038/s42256-023-00644-2 doi: 10.1038/s42256-023-00644-2
|
| [19] |
P. Theodorou, P. Theodorou, Valuation of big data analytics quality and competitive advantage with strategic alignment model: from Greek philosophy to contemporary conceptualization, Data Sci. Financ. Econ., 1 (2024), 53–64. https://doi.org/10.3934/DSFE.2024002 doi: 10.3934/DSFE.2024002
|
| [20] |
C. Kauf, A. A. Ivanova, G. Rambelli, E. Chersoni, J. S. She, Z. Chowdhury, et al., Event knowledge in Large Language Model: the gap between the impossible and the unlikely, Cognit. Sci., 47 (2023), e13386. https://doi.org/10.1111/cogs.13386 doi: 10.1111/cogs.13386
|
| [21] |
S. S. Mannam, R. Subtirelu, D. Chauhan, H. S. Ahmad, I. M. Matache, K. Bryan, et al., Large Language Model- based neurosurgical evaluation matrix: a novel scoring criteria to assess the efficacy of ChatGPT as an educational tool for neurosurgery board preparation, World Neurosurg., 180 (2023), E765–E773. https://doi.org/10.1016/j.wneu.2023.10.043 doi: 10.1016/j.wneu.2023.10.043
|
| [22] |
T. C. Wang, Deep learning-based prediction and revenue optimization for online platform user journeys, Quant. Financ. Econ., 1 (2024), 1–28. https://doi.org/10.3934/QFE.2024001 doi: 10.3934/QFE.2024001
|
| [23] |
S. A. Gyamerah, C. Asare, A critical review of the impact of uncertainties on green bonds, Green Financ., 1 (2024), 78–91. https://doi.org/10.3934/GF.2024004 doi: 10.3934/GF.2024004
|
| [24] |
H. Shin, K. Kim, D. F. Kogler, Scientific collaboration, research funding, and novelty in scientific knowledge, Plos One, 17 (2022), e0271678. https://doi.org/10.1371/journal.pone.0271678 doi: 10.1371/journal.pone.0271678
|
| [25] |
O. N. E. Kjell, K. Kjell, H. A. Schwartz, Beyond rating scales: with targeted evaluation, Large Language Model are poised for psychological assessment, Psychiatry Res., 333 (2024), 115667. https://doi.org/10.1016/j.psychres.2023.115667 doi: 10.1016/j.psychres.2023.115667
|
| [26] |
Z. Williams, H. Apollonio, The causation dilemma in ESG research, Green Financ., 2 (2024), 265–286. https://doi.org/10.3934/GF.2024011 doi: 10.3934/GF.2024011
|
| [27] |
Y. Wen, Y. Xu, Statistical monitoring of economic growth momentum transformation: empirical study of Chinese provinces, AIMS Math., 10 (2023), 24825–224847. https://doi.org/10.3934/math.20231266 doi: 10.3934/math.20231266
|
| [28] |
Z. Li, Q. Lai, J. He, Does digital technology enhance the global value chain position? Borsa Istanb. Rev., 2024. https://doi.org/10.1016/j.bir.2024.04.016 doi: 10.1016/j.bir.2024.04.016
|
| [29] |
Y. Gao, H. Yang, The measurement of financial support for real estate and house price bubbles and their dynamic relationship: an empirical study based on 31 major cities in China, Natl. Account. Rev., 2 (2024), 195–219. https://doi.org/10.3934/NAR.2024009 doi: 10.3934/NAR.2024009
|
| [30] |
Z. Li, B. Chen, S. Lu, G. Liao, The impact of financial institutions' cross-shareholdings on risk-taking, Int. Rev. Econ. Financ., 92 (2024), 1526–1544. https://doi.org/10.1016/j.iref.2024.02.080 doi: 10.1016/j.iref.2024.02.080
|
| [31] |
Z. Kohus, M. Demeter, G. P. Szigeti, L. Kun, E. Lukács, K. Czakó, The influence of international collaboration on the scientific impact in V4 countries, Publications, 10 (2022), 35. https://doi.org/10.3390/publications10040035 doi: 10.3390/publications10040035
|
| [32] |
R. Cai, W. Tian, R. Luo, Z. Hu, The generation mechanism of research leadership in international collaboration based on GERGM: a case from the field of artificial intelligence, Scientometrics, 2024. https://doi.org/10.1007/s11192-024-04974-9 doi: 10.1007/s11192-024-04974-9
|
| [33] |
M. M. Danquah, O. B. Onyancha, B. K. Avuglah, Patterns and trends of university-industry research collaboration in Ghana between 2011 and 2020, Inf. Discov. Deliv., 2024. https://doi.org/10.1108/IDD-11-2022-0122 doi: 10.1108/IDD-11-2022-0122
|
| [34] |
B. B. Xu, S. Y. Liu, J. F. Guo, Graph-based algorithm for exploring collaboration mechanisms and hidden patterns among top scholars, Expert Syst. Appl., 249 (2024), 123810. https://doi.org/10.1016/j.eswa.2024.123810 doi: 10.1016/j.eswa.2024.123810
|

Figures(2) / Tables(6)

Suyan Tan, Yilin Guo. A study of the impact of scientific collaboration on the application of Large Language Model[J]. AIMS Mathematics, 2024, 9(7): 19737-19755. doi: 10.3934/math.2024963







 DownLoad:
DownLoad: