Citation: Junsheng Zhang, Lihua Hao, Tengyun Jiao, Lusong Que, Mingquan Wang. Mathematical morphology approach to internal defect analysis of A356 aluminum alloy wheel hubs[J]. AIMS Mathematics, 2020, 5(4): 3256-3273. doi: 10.3934/math.2020209

| [1] |
P. Li, D. M. Maijer, T. C. Lindley, et al. Simulating the Residual Stress in an A356 Automotive Wheel and Its Impact on Fatigue Life, Metall. Mater. Trans. B, 38 (2007), 505-515. doi: 10.1007/s11663-007-9050-5

|
| [2] |
S. Wang, N. Zhou, W. Qi, et al. Microstructure and mechanical properties of A356 aluminum alloy wheels prepared by thixo-forging combined with a low superheat casting process, T. Nonferr. Metal. Soc., 24 (2014), 2214-2219. doi: 10.1016/S1003-6326(14)63335-5
|
| [3] |
N. K. Kund, P. Dutta, Numerical study of influence of oblique plate length and cooling rate on solidification and macrosegregation of A356 aluminum alloy melt with experimental comparison, J. Alloy. Compod., 678 (2016), 343-354. doi: 10.1016/j.jallcom.2016.02.152
|
| [4] |
L. Ming, Y. Li, G. Bi, et al. Effects of melt treatment temperature and isothermal holding parameter on water-quenched microstructures of A356 aluminum alloy semisolid slurry, T. Nonferr. Metal. Soc., 28 (2018), 393-403. doi: 10.1016/S1003-6326(18)64673-4
|
| [5] | P. Fan, S. Cockcroft, D. Maijer, et al. Examination and Simulation of Silicon Macrosegregation in A356 Wheel Casting, Metals, 8 (2018), 503. |
| [6] |
B. Zhang, S. L. Cockcroft, D. M. Maijer, et al. Casting defects in low-pressure die-cast aluminum alloy wheels, JOM, 57 (2005), 36-43. doi: 10.1007/s11837-005-0025-1
|
| [7] | H. Boerner, H. Strecher, Automated X-Ray Inspection of Aluminum Castings. IEEE T. Pattern Anal., 10 (1988), 79-91. |
| [8] | D. Mery, T. Jaeger, D. Filbert, A review of methods for automated recognition of casting defects, Insight, 44 (2002), 428-436. |
| [9] |
X. Li, S. K. Tso, X. Guan, et al. Improving Automatic Detection of Defects in Castings by Applying Wavelet Technique, IEEE T. Ind. Electron., 53 (2006), 1927-1934. doi: 10.1109/TIE.2006.885448
|
| [10] |
T. Saravanan, S. Bagavathiappan, J. Philip, et al. Segmentation of defects from radiography images by the histogram concavity threshold method, Insight, 49 (2007), 578-584. doi: 10.1784/insi.2007.49.10.578
|
| [11] |
Y. Wang, Y. Sun, P. Lv, et al. Detection of line weld defects based on multiple thresholds and support vector machine, NDT E Int., 41 (2008), 517-524. doi: 10.1016/j.ndteint.2008.05.004
|
| [12] |
Y. Tang, X. Zhang, X. Li, et al. Application of a new image segmentation method to detection of defects in castings, Int. J. Adv. Manuf. Technol., 43 (2009), 431-439. doi: 10.1007/s00170-008-1720-1
|
| [13] |
X. Yuan, L. Wu, Q. Peng, An improved Otsu method using the weighted object variance for defect detection, Appl. Surf. Sci., 349 (2015), 472-484. doi: 10.1016/j.apsusc.2015.05.033
|
| [14] |
M. Malarvel, G. Sethumadhavan, P. C. R. Bhagi, et al. An improved version of Otsu's method for segmentation of weld defects on X-radiography images, Optik, 142 (2017), 109-118. doi: 10.1016/j.ijleo.2017.05.066
|
| [15] | J. Zhang, Z. Guo, T. Jiao, et al. Defect Detection of Aluminum Alloy Wheels in Radiography Images Using Adaptive Threshold and Morphological Reconstruction, Appl. Sci., 8 (2018), 2365. |
| [16] |
D. Mery, D. Filbert, Automated flaw detection in aluminum castings based on the tracking of potential defects in a radioscopic image sequence, IEEE Trans. Robot. Autom., 18 (2002), 890-901. doi: 10.1109/TRA.2002.805646
|
| [17] |
M. Carrasco, D. Mery, Automatic multiple view inspection using geometrical tracking and feature analysis in aluminum wheels, Mach. Vis. Appl., 22 (2011), 157-170. doi: 10.1007/s00138-010-0255-2
|
| [18] |
A. Osman, V. Kaftandjian, U. Hassler, Improvement of x-ray castings inspection reliability by using Dempster-Shafer data fusion theory, Pattern Recogn. Lett., 32 (2011), 168-180. doi: 10.1016/j.patrec.2010.10.004
|
| [19] |
X. Zhao, Z. He, S. Zhang, Defect detection of castings in radiography images using a robust statistical feature, J. Opt. Soc. Am. A, 31 (2014), 196-205. doi: 10.1364/JOSAA.31.000196
|
| [20] |
X. Zhao, Z. He, S. Zhang, et al. A sparse-representation-based robust inspection system for hidden defects classification in casting components, Neurocomputing, 153 (2015), 1-10. doi: 10.1016/j.neucom.2014.11.057
|
| [21] | D. Mery, C. Arteta, Automatic Defect Recognition in X-ray Testing using Computer Vision. In: Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, March 2017, 24-31. |
| [22] |
J. Lin, Y. Yao, L. Ma, et al. Detection of a casting defect tracked by deep convolution neural network, Int. J. Adv. Manuf. Technol., 97 (2018), 573-581, doi: 10.1007/s00170-018-1894-0
|
| [23] |
R. Alaknanda, S. Anand, P. Kumar, Flaw detection in radio-graphic weld images using morphological approach, NDT E Int., 39 (2006), 29-33. doi: 10.1016/j.ndteint.2005.05.005
|
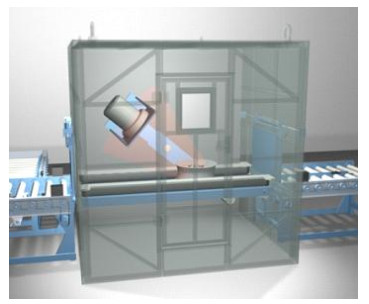


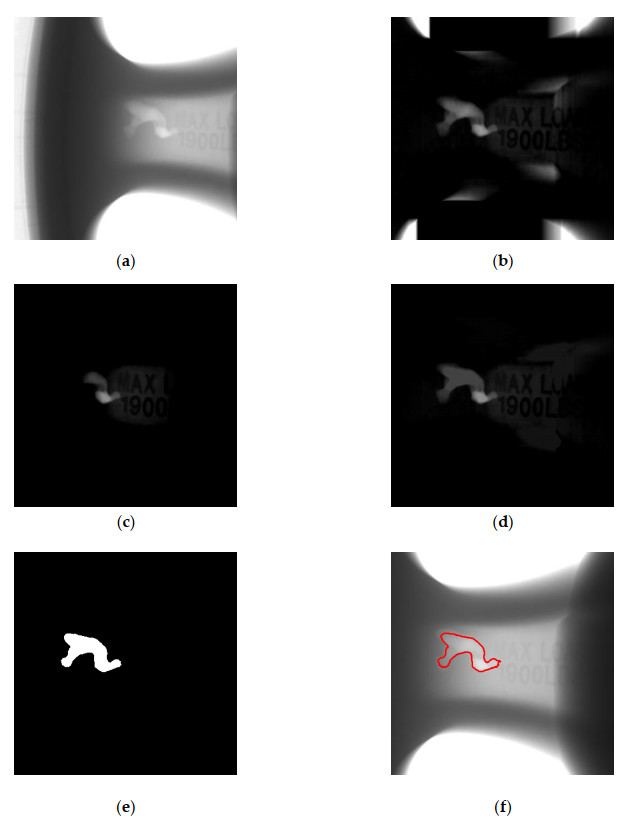


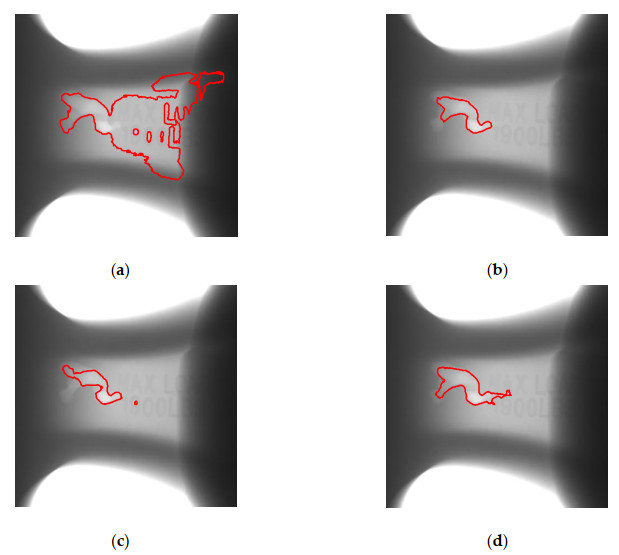
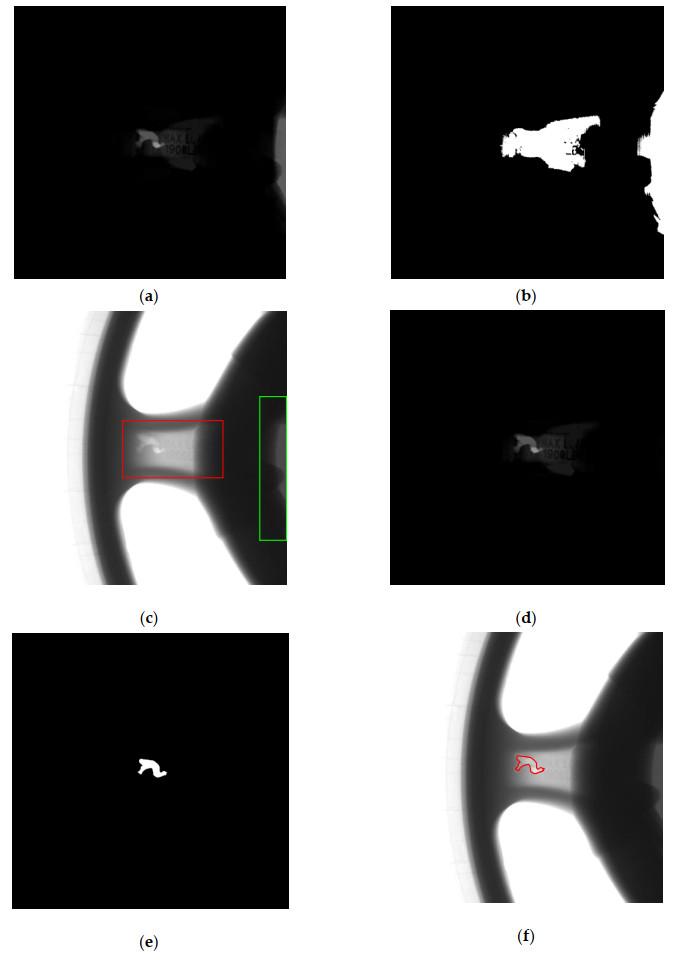
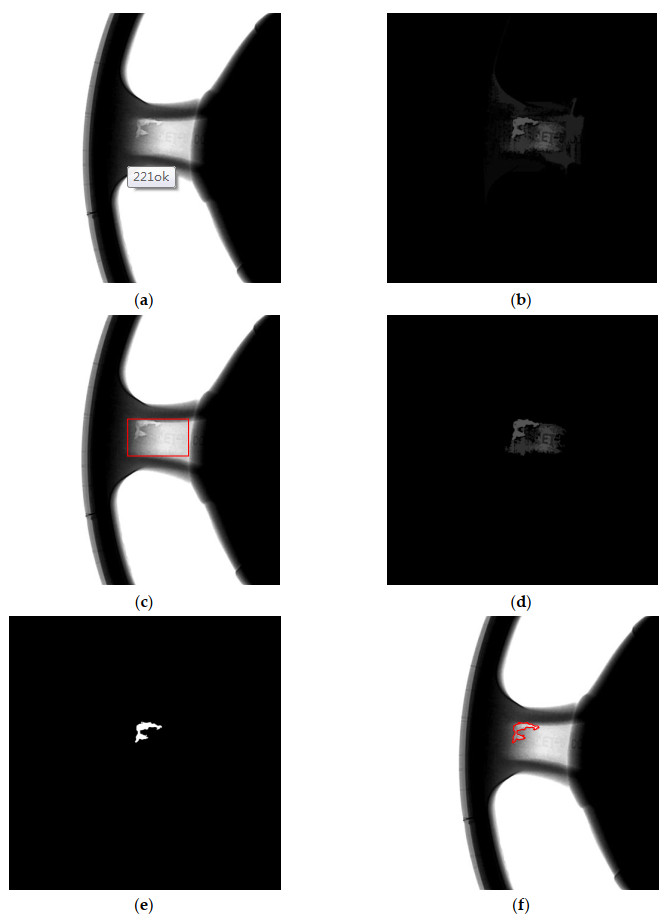
Figures(9)

Junsheng Zhang, Lihua Hao, Tengyun Jiao, Lusong Que, Mingquan Wang. Mathematical morphology approach to internal defect analysis of A356 aluminum alloy wheel hubs[J]. AIMS Mathematics, 2020, 5(4): 3256-3273. doi: 10.3934/math.2020209







 DownLoad:
DownLoad: