Citation: Pakhshan M. Hasan, Nejmaddin A. Sulaiman, Fazlollah Soleymani, Ali Akgül. The existence and uniqueness of solution for linear system of mixed Volterra-Fredholm integral equations in Banach space[J]. AIMS Mathematics, 2020, 5(1): 226-235. doi: 10.3934/math.2020014

| [1] | A. M. Wazwaz, A reliable treatment for mix Volterra-Fredholm integral equations, Appl. Math. Comput., 127 (2002), 405-414. |
| [2] | F. Mirzaee, S. F. Hoseini, Application of Fibonacci collocation method for solving Volterra-Fredholm integral equations, Appl. Math. Comput., 273 (2016), 637-644. |
| [3] | F. Mirzaee, E. Hadadiyan, Numerical solution of Volterra-Fredholm integral equations via modification of hat functions, Appl. Math. Comput., 280 (2016), 110-123. |
| [4] | P. M. A. Hasan, N. A. Sulaiman, Existence and Uniqueness of Solution for Linear Mixed Volterra-Fredholm Integral Equations in Banach Space, Am. J. Comput. Appl. Math., 9 (2019), 1-5. |
| [5] |
L. Mei, Y. Lin, Simplified reproducing kernel method and convergence order for linear Volterra integral equations with variable coefficients, J. Comput. Appl. Math., 346 (2019), 390-398. doi: 10.1016/j.cam.2018.07.027

|
| [6] | S. Micula, On some iterative numerical methods for mixed Volterra-Fredholm integral equations, Symmetry, 11 (2019), 1200. |
| [7] |
S. Deniz S, N. Bildik, Optimal perturbation iteration method for Bratu-type problems, Journal of King Saud University - Science, 30 (2018), 91-99. doi: 10.1016/j.jksus.2016.09.001
|
| [8] |
K. Berrah, A. Aliouche, T. Oussaeif, Applications and theorem on common fixed point in complex valued b-metric space, AIMS Mathematics, 4 (2019), 1019-1033. doi: 10.3934/math.2019.3.1019
|
| [9] |
N. Bildik, S. Deniz, Solving the burgers' and regularized long wave equations using the new perturbation iteration technique, Numer. Meth. Part. D. E., 34 (2018), 1489-1501. doi: 10.1002/num.22214
|
| [10] | J. Chen, M. He, Y. Huang, A fast multiscale Galerkin method for solving second order linear Fredholm integro-differential equation with Dirichlet boundary conditions, J. Comput. Appl. Math., 364 (2020), 112352. |
| [11] |
R. Rabbani, R. Jamali, Solving nonlinear system of mixed Volterra- Fredholm integral equations by using variational iteration method, J. Math. Comput. Sci., 5 (2012), 280-287. doi: 10.22436/jmcs.05.04.05
|
| [12] |
M. Ghasemi, M. Fardi, R. K. Ghaziani, Solution of system of the mixed Volterra - Fredholm integral equations by an analytical method, Math. Comput. Model., 58 (2013), 1522-1530. doi: 10.1016/j.mcm.2013.06.006
|
| [13] | A. Wazwaz, A First course in Integral Equations. Second Edition, Saint Xavier University, USA: World Scientific Publishing, 2015. |
| [14] | T. Abdeljawad, R. P. Agarwal, E. Karapınar, et al. Solutions of the nonlinear integral equation and fractional differential equation using the technique of a fixed point with a numerical experiment in extended b-metric space, Symmetry, 11 (2019), 686. |
| [15] |
E. Hesameddini and M. Shahbazi, Solving system of Volterra-Fredholm integral equations with Bernstein polynomials and hybrid Bernstain Block pulse functions, J. Comput. Appl. Math., 315 (2017), 182-194. doi: 10.1016/j.cam.2016.11.004
|
| [16] | A. Borhanifar, K. Sadri, Shifted Jacobi collocation method based on operational matrix for solving the systems of Fredholm and Volterra integral equations, Math. Comput. Appl., 20 (2015), 76-93. |
| [17] | R. V. Kakde, S. S. Biradar, S. S. Hiremath, Solution of Differential and Integral Equations Using Fixed Point Theory, International Journal of Advanced Research in Computer Engineering & Technology (IJARCET), 3 (2014), 1656-1659. |
| [18] |
K. Maleknejad, P. Torabi, R. Mollapourasl, Fixed point method for solving nonlinear quadratic Volterra integral equations, Comput. Math. Appl., 62 (2011), 2555-2566. doi: 10.1016/j.camwa.2011.07.055
|
| [19] | K. Maleknejad, P. Torabi, Application of fixed point method for solving nonlinear Volterra-Hammerstein integral, U. P. B. Sci. Bull., Series A: App. Math. Phy., 74 (2012), 45-56. |
| [20] | A. J. Jerri, Introduction to Integral Equation with Application. Marcel Dekker, New York and Basel, 1985. |
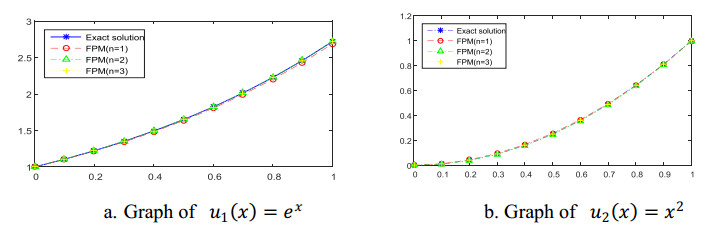
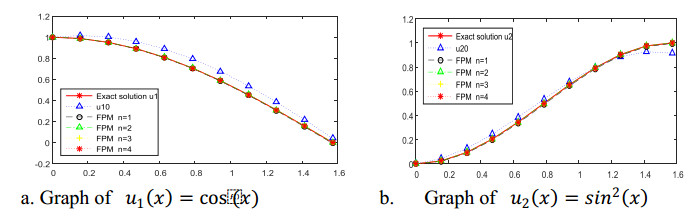
Figures(2) / Tables(5)

Pakhshan M. Hasan, Nejmaddin A. Sulaiman, Fazlollah Soleymani, Ali Akgül. The existence and uniqueness of solution for linear system of mixed Volterra-Fredholm integral equations in Banach space[J]. AIMS Mathematics, 2020, 5(1): 226-235. doi: 10.3934/math.2020014







 DownLoad:
DownLoad: