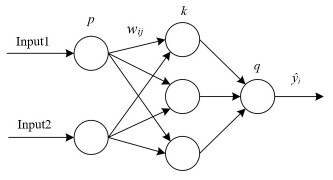
Load forecasting is an important part of microgrid control and operation. To improve the accuracy and reliability of load forecasting in microgrid, a load forecasting method based on an adaptive cuckoo search optimization improved neural network (ICS-BP) was proposed. First, a load forecasting model in microgrid based on a neural network was designed. Then, a novel adaptive step adjustment strategy was proposed for cuckoo search optimization, and an adaptive position update law based on loss fluctuation was designed. Finally, the weights and biases of the forecasting model were optimized by the improved cuckoo search algorithm. The results showed that the BP network optimized by the improved cuckoo search optimization enhanced the global search ability, avoided the local optima, quickened the convergence speed, and presented excellent performance in load forecasting. The mean absolute percentage error (MAPE) of the ICS-BP forecasting model was 1.13%, which was very close to an ideal prediction model, and was 52.3, 32.8, and 42.3% lower than that of conventional BP, cuckoo search improved BP, and particle swarm optimization improved BP, respectively, and the root mean square error (RMSE), mean absolute error (MAE), and mean square error (MSE) of ICS-BP were reduced by 75.6, 70.6, and 94.0%, respectively, compared to conventional BP. The proposed load forecasting method significantly improved the forecasting accuracy and reliability, and can effectively realize the load forecasting of microgrid.
Citation: Liping Fan, Pengju Yang. Load forecasting of microgrid based on an adaptive cuckoo search optimization improved neural network[J]. Electronic Research Archive, 2024, 32(11): 6364-6378. doi: 10.3934/era.2024296
Load forecasting is an important part of microgrid control and operation. To improve the accuracy and reliability of load forecasting in microgrid, a load forecasting method based on an adaptive cuckoo search optimization improved neural network (ICS-BP) was proposed. First, a load forecasting model in microgrid based on a neural network was designed. Then, a novel adaptive step adjustment strategy was proposed for cuckoo search optimization, and an adaptive position update law based on loss fluctuation was designed. Finally, the weights and biases of the forecasting model were optimized by the improved cuckoo search algorithm. The results showed that the BP network optimized by the improved cuckoo search optimization enhanced the global search ability, avoided the local optima, quickened the convergence speed, and presented excellent performance in load forecasting. The mean absolute percentage error (MAPE) of the ICS-BP forecasting model was 1.13%, which was very close to an ideal prediction model, and was 52.3, 32.8, and 42.3% lower than that of conventional BP, cuckoo search improved BP, and particle swarm optimization improved BP, respectively, and the root mean square error (RMSE), mean absolute error (MAE), and mean square error (MSE) of ICS-BP were reduced by 75.6, 70.6, and 94.0%, respectively, compared to conventional BP. The proposed load forecasting method significantly improved the forecasting accuracy and reliability, and can effectively realize the load forecasting of microgrid.

| [1] |
S. Goswami, S. Malakar, B. Ganguli, A. Chakrabarti, A novel transfer learning-based short-term solar forecasting approach for India, Neural Comput. Applic., 34 (2022), 16829–16843. https://doi.org/10.1007/s00521-022-07328-9 doi: 10.1007/s00521-022-07328-9

|
| [2] |
B. Deepanraj, N. Senthilkumar, T. Jarin, A. E. Gurel, L. Sundar, A. Anand, Intelligent wild geese algorithm with deep learning driven short term load forecasting for sustainable energy managementin microgrids, Sustainable Comput.: Inf. Syst., 36 (2022), 100813. https://doi.org/10.1016/j.suscom.2022.100813 doi: 10.1016/j.suscom.2022.100813
|
| [3] |
A. Rafati, M. Joorabian, E. Mashhour, H. R. Shaker, Machine learning-based very short-term load forecasting inmicrogrid environment: evaluating the impact of high penetration of PV systems, Electr. Eng., 104 (2022), 2667–2677. https://doi.org/10.1007/s00202-022-01509-4 doi: 10.1007/s00202-022-01509-4
|
| [4] |
S. Wang, F. Wu, P. Takyi-Aninakwa, C. Fernandez, D. Stroe, Q. Huang, Improved singular filtering-Gaussian process regression-long short-term memory model for whole-life-cycle remaining capacity estimation of lithium-ion batteries adaptive to fast aging and multi-current variations, Energy, 284 (2023), 128677. https://doi.org/10.1016/j.energy.2023.128677 doi: 10.1016/j.energy.2023.128677
|
| [5] |
S. Wang, Y. Fan, S. Jin, P. Takyi-Aninakwa. C. Fernandez, Improved anti-noise adaptive long short-term memory neural network modeling for the robust remaining useful life prediction of lithium-ion batteries, Reliab. Eng. Syst. Safe, 230 (2023), 108920. https://doi.org/10.1016/j.ress.2022.108920 doi: 10.1016/j.ress.2022.108920
|
| [6] |
A. Jahani, K. Zare, L. M. Khanli, Short-term load forecasting for microgrid energy management system using hybrid SPM-LSTM, Sustainable Cities Soc., 98 (2023), 104775. https://doi.org/10.1016/j.scs.2023.104775 doi: 10.1016/j.scs.2023.104775
|
| [7] |
A. A. Muzumdar, C. N. Modi, G. M. Madhu, C. Vyjayanthi, Designing a robust and accurate model for consumer-centric short-term load forecasting in microgrid environment, IEEE Syst. J. , 16 (2022), 2448–2459.https://doi.org/10.1109/JSYST.2021.3073493 doi: 10.1109/JSYST.2021.3073493
|
| [8] |
F. Mohammad, C. Kimy, Energy load forecasting model based on deep neural networks for smart grids, Int. J. Syst. Assur. Eng., 11 (2020), 824–834. https://doi.org/10.1007/s13198-019-00884-9 doi: 10.1007/s13198-019-00884-9
|
| [9] |
R. Wazirali, E. Yaghoubi, M. S. Abujazar, R. Ahmad, H. A. Vakili, State-of-the-art review on energy and load forecasting in microgrids using artificial neural networks, machine learning, and deep learning techniques, Electr. Pow. Syst. Res., 225 (2023), 109792. https://doi.org/10.1016/j.epsr. 2023.109792 doi: 10.1016/j.epsr.2023.109792
|
| [10] |
H. Xu, Y. Chang, Y. Zhao, F. Wu, A novel hybrid wind speed interval prediction model based on mode decomposition and gated recursive neural network, Environ. Sci. Pollut. R., 29 (2022), 1–17. https://doi.org/10.1007/s11356-022-21904-5 doi: 10.1007/s11356-022-21904-5
|
| [11] |
B. B. Yong, H. Liang, F. C. Li, J. Shen, X. Wang, Q. G. Zhou, A research of Monte Carlo optimized neural network for electricity load forecast, J. Supercomput., 76 (2020), 6330–6343. https://doi.org/10.1007/s11227-019-02828-3 doi: 10.1007/s11227-019-02828-3
|
| [12] |
L. Nguyen-Ngoc, Q. Nguyen-Huu, G. D. Roeck, T. Bui-Tien, M, Abdel-Wahab, Deep neural network and evolved optimization algorithm for damage assessment in a truss bridge, Mathematics, 12 (2024), 2300. https://doi.org/10.3390/math12152300 doi: 10.3390/math12152300
|
| [13] |
Y. F. Li, H. L. Minh, M. S. Cao, X. D. Qian, M. A. Wahab, An integrated surrogate model-driven and improved termite life cycle optimizer for damage identification in dams, Mech. Syst. Signal Pr., 208 (2024), 110986. https://doi.org/10.1016/j.ymssp.2023.110986 doi: 10.1016/j.ymssp.2023.110986
|
| [14] |
V. T. Tran, T. K. Nguyen, H. Nguyen-Xuan, M. A. Wahab, Vibration and buckling optimization of functionally graded porous microplates using BCMO-ANN algorithm, Thin Wall Struct., 182 (2023), 110267. https://doi.org/10.1016/j.tws.2022.110267 doi: 10.1016/j.tws.2022.110267
|
| [15] |
B. L. Dang, H. Nguyen-Xuan, M. A. Wahab, An effective approach for VARANS-VOF modelling interactions of wave and perforated breakwater using gradient boosting decision tree algorithm, Ocean Eng., 268 (2023), 113398. https://doi.org/10.1016/j.oceaneng.2022.113398 doi: 10.1016/j.oceaneng.2022.113398
|
| [16] |
T. Li, Y. Li, L. S. Ren, A method of using back propagation neural network to estimate orbital life time of LEO satellites, Adv. Space Res., 72 (2023), 1961–1969. https://doi.org/10.1016/j.asr.2023.05.026 doi: 10.1016/j.asr.2023.05.026
|
| [17] |
Y. M. Xie, W. Li, C. Liu, M. Du, K. Feng, Optimization of stamping process parameters based on improved GA-BP neural network model, Int. J. Precis. Eng. Man., 24 (2023), 1129–1145. https://doi.org/10.1007/s12541-023-00811-w doi: 10.1007/s12541-023-00811-w
|
| [18] |
A. J. Thomas, S. J. Walters, S. M. Gheytassi, R. E. Morgan, M. Petridis, On the optimal node ratio between hidden layers: a probabilistic study, Int. J. Mach. Learn. Comput., 6 (2016), 241–247. https://doi.org/10.18178/IJMLC.2016.6.5.605 doi: 10.18178/IJMLC.2016.6.5.605
|
| [19] |
M. Braik, A. Sheta, H. Al-Hiary, S. Aljahdali, Enhanced cuckoo search algorithm for industrial winding process modeling, J. Intell. Manuf., 34 (2023), 1911–1940. https://doi.org/10.1007/s10845-021-01900-1 doi: 10.1007/s10845-021-01900-1
|
| [20] |
Z. P. Hou, M. Zhou, C. Roberts, H. Dong, Cuckoo search approach for automatic train regulation under capacity limitation, Sci. China Inf. Sci., 66 (2023), 149204. https://doi.org/10.1007/s11432-020-3254-0 doi: 10.1007/s11432-020-3254-0
|
| [21] |
H. J. Zheng, Y. Peng, J. Guo, Y. Chen, Course scheduling algorithm based on improved binary cuckoo search, J. Supercomput., 78 (2022), 11895–11920. https://doi.org/10.1007/s11227-022-04341-6 doi: 10.1007/s11227-022-04341-6
|
| [22] |
L. Z. Duan, S. Q. Yang, D. B. Zhang, Multilevel thresholding using an improved cuckoo search algorithm for image segmentation, J. Supercomput., 77 (2021), 6734–6753. https://doi.org/10.1007/s11227-020-03566-7 doi: 10.1007/s11227-020-03566-7
|
| [23] |
M. G. Mortazavi, M. H. Shirvani, A. Dana, M. Fathy, Sleep-wakeup scheduling algorithm for lifespan maximization of directional sensor networks: a discrete cuckoo search optimization algorithm, Complex Intell. Syst., 9 (2023), 6459–6491. https://doi.org/10.1007/s40747-023-01078-4 doi: 10.1007/s40747-023-01078-4
|
| [24] |
J. T. Cheng, Y. Xiong, Parameter control based Cuckoo Search Algorithm for numerical optimization, Neural Process. Lett., 54 (2022), 3173–3200. https://doi.org/10.1007/s11063-022-10758-0 doi: 10.1007/s11063-022-10758-0
|
| [25] |
H. Khan, S. Jamal, M. Hazzazi, M. Khan, I. Hussain, New image encryption scheme based on Arnold map and cuckoo search optimization algorithm, Multimed. Tools Appl., 82 (2023), 7419–7441. https://doi.org/10.1007/s11042-022-13600-w doi: 10.1007/s11042-022-13600-w
|
| [26] |
R. Cristin, B. Kumar, C. Priya, K. Karthick, Deep neural network based Rider-cuckoo search algorithm for plant disease detection, Artif. Intell. Rev., 53 (2020), 4993–5018. https://doi.org/10.1007/s10462-020-09813-w doi: 10.1007/s10462-020-09813-w
|
| [27] | M. Gupta, M. Abouhawwash, S. Mahajan, A. K. Pandit, Cuckoo search algorithm, its variants and applications: A review, in AIP Conference Proceeding, 2495 (2023), 020072. https://doi.org/10.1063/5.0122753 |
| [28] |
X. Qin, B. Xia, T. Ding, L. Zhao, An improved cuckoo search localization algorithm for UWB sensor networks, Wireless Networks, 27 (2020), 527–535. https://doi.org/10.1007/s11276-020-02465-2 doi: 10.1007/s11276-020-02465-2
|
| [29] |
J. Wei, H. Y. Niu, A ranking-based adaptive cuckoo search algorithm for unconstrained optimization, Expert Syst. Appl., 204 (2022), 117428. https://doi.org/10.1016/j.eswa.2022.117428 doi: 10.1016/j.eswa.2022.117428
|
| [30] |
B. She, A. Fournier, M. Yao, Y. Wang, G. Hu, A self-adaptive and gradient-based cuckoo search algorithm for global optimization, Appl. Soft Comput., 122 (2022), 108774. https://doi.org/10.1016/j.asoc.2022.108774 doi: 10.1016/j.asoc.2022.108774
|
| [31] | S. Sadik, M. Et-tolba, B. Nsiri, A modified adaptive sparse-group LASSO regularization for optimal portfolio selection, IEEE Access, 12 (2024), 107337–107352. https://doi.org/10.1109/ACCESS.2024.3438125 |
| [32] |
M. Uddin, H. Moa, D. Dong, S. Elsawah, J. Zhu, M. Guerrero, Microgrids: A review, outstanding issues and future trends, Energy Strateg. Rev., 49 (2023), 101127. https://doi.org/10.1016/j.esr.2023.101127 doi: 10.1016/j.esr.2023.101127
|
| [33] |
A. Solat, G. B. Gharehpetian, M. S. Naderi, A. Anvari-Moghaddam, On the control of microgrids against cyber-attacks: A review of methods and applications, Appl. Energy, 353 (2024), 122037. https://doi.org/10. 1016/j.apenergy.2023.122037 doi: 10.1016/j.apenergy.2023.122037
|




Figures(5) / Tables(2)
Liping Fan, Pengju Yang. Load forecasting of microgrid based on an adaptive cuckoo search optimization improved neural network[J]. Electronic Research Archive, 2024, 32(11): 6364-6378. doi: 10.3934/era.2024296







 DownLoad:
DownLoad: