In today's competitive and volatile market, demand prediction for seasonal items is a challenging task. The variation in demand is so quick that the retailer cannot face the risk of understocking or overstocking. Unsold items need to discarded, which has environmental implications. It is often difficult to calculate the effects of lost sales on a firm's monetary values, and environmental impact is not a concern to most businesses. These issues concerned with the environmental impact and the shortages are considered in this paper. A single-period inventory mathematical model is formulated to maximize expected profit in a stochastic scenario while calculating the optimal price and order quantity. The demand considered in this model is price-dependent, with several emergency backordering options to overcome the shortages. The demand probability distribution is unknown to the newsvendor problem. The only available demand data are the mean and standard deviation. In this model, the distribution-free method is applied. A numerical example is provided to demonstrate the model's applicability. To prove that this model is robust, sensitivity analysis is performed.
Citation: Irfanullah Khan, Asif Iqbal Malik, Biswajit Sarkar. A distribution-free newsvendor model considering environmental impact and shortages with price-dependent stochastic demand[J]. Mathematical Biosciences and Engineering, 2023, 20(2): 2459-2481. doi: 10.3934/mbe.2023115
In today's competitive and volatile market, demand prediction for seasonal items is a challenging task. The variation in demand is so quick that the retailer cannot face the risk of understocking or overstocking. Unsold items need to discarded, which has environmental implications. It is often difficult to calculate the effects of lost sales on a firm's monetary values, and environmental impact is not a concern to most businesses. These issues concerned with the environmental impact and the shortages are considered in this paper. A single-period inventory mathematical model is formulated to maximize expected profit in a stochastic scenario while calculating the optimal price and order quantity. The demand considered in this model is price-dependent, with several emergency backordering options to overcome the shortages. The demand probability distribution is unknown to the newsvendor problem. The only available demand data are the mean and standard deviation. In this model, the distribution-free method is applied. A numerical example is provided to demonstrate the model's applicability. To prove that this model is robust, sensitivity analysis is performed.

| [1] |
D. B. Rosenfield, Optimal management of tax-sheltered employee reimbursement programs, Interfaces, 16 (1986), 68–72. https://doi.org/10.1287/inte.16.3.68 doi: 10.1287/inte.16.3.68

|
| [2] |
L. Eeckhoudt, C. Gollier, H. Schlesinger, The risk-averse (and prudent) newsboy, Manage. Sci., 41 (1995), 786–794. https://doi.org/10.1287/mnsc.41.5.786 doi: 10.1287/mnsc.41.5.786
|
| [3] |
K. Chen, T. Xiao, Ordering policy and coordination of a supply chain with two-period demand uncertainty, Eur. J. Oper. Res., 215 (2011), 347–357. https://doi.org/10.1016/j.ejor.2011.06.015 doi: 10.1016/j.ejor.2011.06.015
|
| [4] |
O. Jadidi, M. Y. Jaber, S. Zolfaghri, R. Pinto, F. Firouzi, Dynamic pricing and lot sizing for a newsvendor problem with supplier selection, quantity discounts, and limited supply capacity, Comput. Ind. Eng., 154 (2021), 107113. https://doi.org/10.1016/j.cie.2021.107113 doi: 10.1016/j.cie.2021.107113
|
| [5] |
N. C. Petruzzi, M. Dada, Pricing and the newsvendor problem: A review with extensions, Oper. Res., 47 (1999), 183–194. https://doi.org/10.1287/opre.47.2.183 doi: 10.1287/opre.47.2.183
|
| [6] |
M. Khouja, The single-period (news-vendor) problem: literature review and suggestions for future research, Omega, 27 (1999), 537–553. https://doi.org/10.1016/S0305-0483(99)00017-1 doi: 10.1016/S0305-0483(99)00017-1
|
| [7] |
Y. Qin, R. Wang, A. J. Vakharia, Y. Chen, M. M. Seref, The newsvendor problem: Review and directions for future research, Eur. J. Oper. Res., 213 (2011), 361–374. https://doi.org/10.1016/j.ejor.2010.11.024 doi: 10.1016/j.ejor.2010.11.024
|
| [8] |
J. Heydari, B. Momeni, Retailers' coalition and quantity discounts under demand uncertainty, J. Retailing Consum. Serv., 61 (2021), 102557. https://doi.org/10.1016/j.jretconser.2021.102557 doi: 10.1016/j.jretconser.2021.102557
|
| [9] |
T. M. Whitin, Inventory control and price theory, Manage. Sci., 2 (1955), 61–68. https://doi.org/10.1287/mnsc.2.1.61 doi: 10.1287/mnsc.2.1.61
|
| [10] |
E. S. Mills, Uncertainty and price theory, Q. J. Econ., 73 (1959), 116–130. https://doi.org/10.2307/1883828 doi: 10.2307/1883828
|
| [11] | S. Karlin, C. R. Carr, Prices and optimal inventory policy, in Studies in Applied Probability and Management Science, 4 (1962), 159–172. |
| [12] |
F. Y. Chen, H. Yan, L. Yao, A newsvendor pricing game, IEEE Trans. Syst. Man Cybern. Part A Syst. Humans, 34 (2004), 450–456. https://doi.org/10.1109/TSMCA.2004.826290 doi: 10.1109/TSMCA.2004.826290
|
| [13] |
B. Afshar-Nadjafi, The influence of sale announcement on the optimal policy of an inventory system with perishable items, J. Retailing Consum. Serv., 31 (2016), 239–245. https://doi.org/10.1016/j.jretconser.2016.04.010 doi: 10.1016/j.jretconser.2016.04.010
|
| [14] | S. Kumar, M. Sigroha, K. Kumar, B. Sarkar, Manufacturing/remanufacturing based supply chain management under advertisements and carbon emission process, RAIRO Oper. Res., 56 (2022). https://doi.org/10.1051/ro/2021189 |
| [15] | B. Sarkar, J. Joo, Y. Kim, H. Park, M. Sarkar, Controlling defective items in a complex multi-phase manufacturing system, RAIRO Oper. Res., 56(2) (2022), 871–889. https://doi.org/10.1051/ro/2022019 |
| [16] | S.B. Choi, B.K. Dey, S.J. Kim, B Sarkar, Intelligent servicing strategy for an online-to-offline (O2O) supply chain under demand variability and controllable lead time, RAIRO Oper. Res., 56(3) (2022), 1623-1653. https://doi.org/10.1051/ro/20220263 |
| [17] |
D. C. Montgomery, M. Bazaraa, A. K. Keswani, Inventory models with a mixture of backorders and lost sales, Nav. Res. Logist. Q., 20 (1973), 255–263. https://doi.org/10.1002/nav.3800200205 doi: 10.1002/nav.3800200205
|
| [18] |
H. M. Wee, Deteriorating inventory model with quantity discount, pricing and partial backordering, Int. J. Prod. Econ., 59 (1999), 511–518. https://doi.org/10.1016/S0925-5273(98)00113-3 doi: 10.1016/S0925-5273(98)00113-3
|
| [19] |
E. J. L. Jr, Advanced supply chain planning with mixtures of backorders, lost sales, and lost contract, Eur. J. Oper. Res., 181 (2007), 168–183. https://doi.org/10.1016/j.ejor.2006.06.002 doi: 10.1016/j.ejor.2006.06.002
|
| [20] |
C. T. Chang, T. Y. Lo, On the inventory model with continuous and discrete lead time, backorders and lost sales, Appl. Math. Modell., 33 (2009), 2196–2206. https://doi.org/10.1016/j.apm.2008.05.028 doi: 10.1016/j.apm.2008.05.028
|
| [21] |
A. J. Brito, A. T. de Almeida, Modeling a multi-attribute utility newsvendor with partial backlogging, Eur. J. Oper. Res., 220 (2012), 820–830. https://doi.org/10.1016/j.ejor.2012.02.027 doi: 10.1016/j.ejor.2012.02.027
|
| [22] |
X. Xu, H. Wang, C. Dang, P. Ji, The loss-averse newsvendor model with backordering, Int. J. Prod. Econ., 188 (2017), 1–10. https://doi.org/10.1080/17510694.2017.1318486 doi: 10.1080/17510694.2017.1318486
|
| [23] |
Y. Li, J. Ou, Optimal ordering policy for complementary components with partial backordering and emergency replenishment under spectral risk measure, Eur. J. Oper. Res., 284 (2020), 538–549. https://doi.org/10.1016/j.ejor.2020.01.006 doi: 10.1016/j.ejor.2020.01.006
|
| [24] |
A. A. Taleizadeh, K. Tafakkori, P. Thaichon, Resilience toward supply disruptions: A stochastic inventory control model with partial backordering under the base stock policy, J. Retailing Consum. Serv., 58 (2021), 102291. https://doi.org/10.1016/j.jretconser.2020.102291 doi: 10.1016/j.jretconser.2020.102291
|
| [25] |
R. Maihami, I. Ghalehkhondabi, E. Ahmadi, Pricing and inventory planning for non-instantaneous deteriorating products with greening investment: A case study in beef industry, J. Clean. Prod., 295 (2021), 126368. https://doi.org/10.1016/j.jclepro.2021.126368 doi: 10.1016/j.jclepro.2021.126368
|
| [26] |
A. S. Mahapatra, M. S. Mahapatra, B. Sarkar, S. K. Majumder, Benefit of preservation technology with promotion and time-dependent deterioration under fuzzy learning, Exp. Syst. Appl., 201 (2022), 117169. https://doi.org/10.1016/j.eswa.2022.117169 doi: 10.1016/j.eswa.2022.117169
|
| [27] |
M. Tayyab, M.S. Habib, M.S.S. Jajja, B. Sarkar, Economic assessment of a serial production system with random imperfection and shortages: A step towards sustainability, Comput. Ind. Eng., 171 (2022), 108398. https://doi.org/10.1016/j.cie.2022.108398 doi: 10.1016/j.cie.2022.108398
|
| [28] |
A. Sarkar, R. Guchhait, B. Sarkar, Application of the artificial neural network with multithreading within an inventory model under uncertainty and inflation, Int. J. Fuzzy Syst., 24 (2022), 2318-–2332. https://doi.org/10.1007/s40815-022-01276-1 doi: 10.1007/s40815-022-01276-1
|
| [29] | H. Scarf, A min-max solution of an inventory problem, Studies Math. Theory Inventory Prod., 1958. |
| [30] |
G. Gallego, I. Moon, The distribution free newsboy problem: review and extensions, J. Oper. Res. Soc., 44 (1993), 825–834. https://doi.org/10.1057/jors.1993.141 doi: 10.1057/jors.1993.141
|
| [31] |
P. L. Abad, Optimal price and order size for a reseller under partial backordering, Comput. Oper. Res., 28 (2001), 53–65. https://doi.org/10.1016/S0305-0548(99)00086-6 doi: 10.1016/S0305-0548(99)00086-6
|
| [32] |
H. He, S. Wang, Cost-benefit associations in consumer inventory problem with uncertain benefit, J. Retailing Consum. Serv., 51 (2019), 271–284. https://doi.org/10.1016/j.jretconser.2019.06.013 doi: 10.1016/j.jretconser.2019.06.013
|
| [33] |
Z. Hong, X. Guo, Green product supply chain contracts considering environmental responsibilities, Omega, 83 (2019), 155–166. https://doi.org/10.1016/j.omega.2018.02.010 doi: 10.1016/j.omega.2018.02.010
|
| [34] |
C. C. Hsu, K. C. Tan, S. H. M. Zailani, V. Jayaraman, Supply chain drivers that foster the development of green initiatives in an emerging economy, Int. J. Oper. Prod. Manage., 33 (2013), 656-688. https://doi.org/10.1108/IJOPM-10-2011-0401 doi: 10.1108/IJOPM-10-2011-0401
|
| [35] |
K. Govindan, M. Shaw, A. Majumdar, Social sustainability tensions in multi-tier supply chain: A systematic literature review towards conceptual framework development, J. Clean. Prod., 279 (2020), 123075. https://doi.org/10.1016/j.jclepro.2020.123075 doi: 10.1016/j.jclepro.2020.123075
|
| [36] |
H. L. Chan, T. Choi, Y. J. Cai, B. Shen, Environmental taxes in newsvendor supply chains: A mean-downside-risk analysis, IEEE Trans. Syst. Man Cybern. Syst., 50 (2018), 4856–4869. https://doi.org/10.1109/TSMC.2018.2870881 doi: 10.1109/TSMC.2018.2870881
|
| [37] |
X. Shi, H. L. Chan, C. Dong, Value of bargaining contract in a supply chain system with sustainability investment: An incentive analysis, IEEE Trans. Syst. Man. Cybern. Syst., 50 (2018), 1622–1634. https://doi.org/10.1109/TSMC.2018.2880795 doi: 10.1109/TSMC.2018.2880795
|
| [38] |
M. S. Habib, M. Omair, M. B. Ramzan, T. N. Chaudhary, M. Farooq, B. Sarkar, A robust possibilistic flexible programming approach toward a resilient and cost-efficient biodiesel supply chain network, J. Clean. Prod., 366 (2022), 132752. https://doi.org/10.1016/j.jclepro.2022.132752 doi: 10.1016/j.jclepro.2022.132752
|
| [39] |
B. Shen, T. M. Choi, H. L. Chan, Selling green first or not? a bayesian analysis with service levels and environmental impact considerations in the big data era, Technol. Forecast. Soc. Change, 144 (2019), 412–420. https://doi.org/10.1016/j.techfore.2017.09.003 doi: 10.1016/j.techfore.2017.09.003
|
| [40] | D. Yadav, R. Singh, A. Kumar, B. Sarkar, Reduction of pollution through sustainable and flexible production by controlling by-products, J. Environ. Inf., 40 (2022), 106–124. |
| [41] |
B. Q. Tan, F. Wang, J. Liu, K. Kang, F. Costa, A blockchain-based framework for green logistics in supply chains, Sustainability, 12 (2020), 4656. https://doi.org/10.3390/su12114656 doi: 10.3390/su12114656
|
| [42] |
A. Kumar, R. Liu, Z. Shan, Is blockchain a silver bullet for supply chain management? technical challenges and research opportunities, Decis. Sci., 51 (2020), 8–37. https://doi.org/10.1111/deci.12396 doi: 10.1111/deci.12396
|
| [43] |
P. Liu, Y. Long, H. C. Song, Y. D. He, Investment decision and coordination of green agri-food supply chain considering information service based on blockchain and big data, J. Clean. Prod., 277 (2020), 123646. https://doi.org/10.1016/j.jclepro.2020.123646 doi: 10.1016/j.jclepro.2020.123646
|
| [44] |
B. Sarkar, B. Ganguly, S. Pareek, L.E. Cárdenas-Barrón, A three-echelon green supply chain management for biodegradable products with three transportation modes, Comput. Ind. Eng., 174 (2022), 108727. https://doi.org/10.1016/j.cie.2022.108727 doi: 10.1016/j.cie.2022.108727
|
| [45] |
S. S. Sana, Price competition between green and non green products under corporate social responsible firm, J. Retailing Consum. Serv., 55 (2020), 102118. https://doi.org/10.1016/j.jretconser.2020.102118 doi: 10.1016/j.jretconser.2020.102118
|
| [46] |
A. S. H. Kugele, W. Ahmed, B. Sarkar, Geometric programming solution of second degree difficulty for carbon ejection controlled reliable smart production system, RAIRO Oper. Res., 56 (2022), 1013–1029. https://doi.org/10.1051/ro/2022028 doi: 10.1051/ro/2022028
|
| [47] | B. Sarkar, S. Kar, K Basu, R. Guchhait, A sustainable managerial decision-making problem for a substitutable product in a dual-channel under carbon tax policy, Comput. Ind. Eng., 172(B) (2022), 108635. https://doi.org/10.1016/j.cie.2022.108635 |
| [48] | I. Moon, W.Y. Yun, B. Sarkar, Effects of variable setup cost, reliability, and production costs under controlled carbon emissions in a reliable production system, Euro. J. Indust. Eng., 16(4) (2022), 371–397. https://doi.org/10.1504/EJIE.2022.123748 |
| [49] |
P. Abad, Determining optimal price and order size for a price setting newsvendor under cycle service level, Int. J. Prod. Econ., 158 (2014), 106–113. https://doi.org/10.1016/j.ijpe.2014.07.008 doi: 10.1016/j.ijpe.2014.07.008
|
| [50] |
S. Alaei, M. Setak, Multi objective coordination of a supply chain with routing and service level consideration, Int. J. Prod. Econ., 167 (2015), 271–281. https://doi.org/10.1016/j.ijpe.2015.06.002 doi: 10.1016/j.ijpe.2015.06.002
|
| [51] |
B. Pal, S. S. Sana, K. Chaudhuri, A distribution-free newsvendor problem with nonlinear holding cost, Int. J. Syst. Sci., 46 (2015), 1269–1277. https://doi.org/10.1080/00207721.2013.815828 doi: 10.1080/00207721.2013.815828
|
| [52] |
M. A. Abdel-Aal, M. N. Syed, S. Z. Selim, Multi-product selective newsvendor problem with service level constraints and market selection flexibility, Int. J. Prod. Econ., 55 (2017), 96–117. https://doi.org/10.1080/00207543.2016.1195932 doi: 10.1080/00207543.2016.1195932
|
| [53] |
X. A. Chen, Z. Wang, H. Yuan, Optimal pricing for selling to a static multi-period newsvendor, Oper. Res. Lett., 45 (2017), 415–420. https://doi.org/10.1016/j.orl.2017.05.006 doi: 10.1016/j.orl.2017.05.006
|
| [54] |
X. Hu, P. Su, The newsvendor's joint procurement and pricing problem under price-sensitive stochastic demand and purchase price uncertainty, Omega, 79 (2018), 81–90. https://doi.org/10.1016/j.omega.2017.08.002 doi: 10.1016/j.omega.2017.08.002
|
| [55] |
S. V. S. Padiyar, V. Vandana, N. Bhagat, S. R. Singh, B. Sarkar, Joint replenishment strategy for deteriorating multi-item through multi-echelon supply chain model with imperfect production under imprecise and inflationary environment, RAIRO Oper. Res., 56 (2022), 3071–3096. https://doi.org/10.1051/ro/2022071 doi: 10.1051/ro/2022071
|
| [56] |
B. Sarkar, D. Takeyeva, R. Guchhait, M. Sarkar, Optimized radio-frequency identification system for different warehouse shapes, Know. Based Syst., 258 (2022), 109811. https://doi.org/10.1016/j.knosys.2022.109811 doi: 10.1016/j.knosys.2022.109811
|
| [57] |
J. Shi, Q. Du, F. Lin, Y. Li, L. Bai, R. Y. Fung, et al., Coordinating the supply chain finance system with buyback contract: A capital-constrained newsvendor problem, Comput. Ind. Eng., 146 (2020), 106587. https://doi.org/10.1016/j.cie.2020.106587 doi: 10.1016/j.cie.2020.106587
|
| [58] |
A. Govindarajan, A. Sinha, J. Uichanco, Distribution-free inventory risk pooling in a multilocation newsvendor, Manage. Sci., 67 (2020), 2272-2291. https://doi.org/10.1287/mnsc.2020.3719 doi: 10.1287/mnsc.2020.3719
|
| [59] |
Y. Fan, Y. Feng, Y. Shou, A risk-averse and buyer-led supply chain under option contract: Cvar minimization and channel coordination, Int. J. Prod. Econ., 219 (2020), 66–81. https://doi.org/10.1016/j.ijpe.2019.05.021 doi: 10.1016/j.ijpe.2019.05.021
|
| [60] | M. Sarkar, B. Sarkar, A. Dolgui, An automated smart production with system reliability under a leader-follower strategy of supply chain management, In: Kim, D.Y., von Cieminski, G., Romero, D. (eds) Advances in Production Management Systems. Smart Manufacturing and Logistics Systems: Turning Ideas into Action. APMS 2022. IFIP International Conference on Advances in Production Management Systems, 663 (2022), 459–467, Springer, Cham. https://doi.org/10.1007/978-3-031-16407-1_54 |
| [61] |
C. Bi, B. Zhang, F. Yang, Y. Wang, G. Bi, Selling to the newsvendor through debt-shared bank financing, Eur. J. Oper. Res., 296 (2021), 116-130. https://doi.org/10.1016/j.ejor.2021.02.025 doi: 10.1016/j.ejor.2021.02.025
|
| [62] |
V. Hovelaque, J. L. Viviani, M. A. Mansour, Trade and bank credit in a non-cooperative chain with a price-sensitive demand, Int. J. Prod. Res., 60 (2021), 1553-1568. https://doi.org/10.1080/00207543.2020.1866222 doi: 10.1080/00207543.2020.1866222
|
| [63] |
M. Ullah, I. Khan, B. Sarkar, Dynamic pricing in a multi-period newsvendor under stochastic price-dependent demand, Mathematics, 7 (2019), 520. https://doi.org/10.3390/math7060520 doi: 10.3390/math7060520
|
| [64] |
H. Lee, E. J. L. Jr, Modeling customer impatience in a newsboy problem with time-sensitive shortages, Eur. J. Oper. Res., 205 (2010), 595–603. https://doi.org/10.1016/j.ejor.2010.01.028 doi: 10.1016/j.ejor.2010.01.028
|
| [65] |
P. Centobelli, R. Cerchione, E. Esposito, E. Oropallo, Surfing blockchain wave, or drowning? shaping the future of distributed ledgers and decentralized technologies, Technol. Forecast. Soc. Change, 165 (2021), 120463. https://doi.org/10.1016/j.techfore.2020.120463 doi: 10.1016/j.techfore.2020.120463
|
| [66] |
P. Centobelli, R. Cerchione, E. Oropallo, W. H. El-Garaihy, T. Farag, K. H. A. Shehri, Towards a sustainable development assessment framework to bridge supply chain practices and technologies, Sustainable Dev., 30 (2020), 647–663. https://doi.org/10.1002/sd.2262 doi: 10.1002/sd.2262
|
| [67] |
M. K. Lim, Y. Li, C. Wang, M. L. Tseng, A literature review of blockchain technology applications in supply chains: A comprehensive analysis of themes, methodologies and industries, Comput. Ind. Eng., 154 (2021), 107133. https://doi.org/10.1016/j.cie.2021.107133 doi: 10.1016/j.cie.2021.107133
|
| [68] |
X. Liu, A. V. Barenji, Z. Li, B. Montreuil, G. Q. Huang, Blockchain-based smart tracking and tracing platform for drug supply chain, Comput. Ind. Eng., 161 (2021), 107669. https://doi.org/10.1016/j.cie.2021.107669 doi: 10.1016/j.cie.2021.107669
|
| [69] |
Z. Liu, Z. Li, A blockchain-based framework of cross-border e-commerce supply chain, Int. J. Inf. Manage., 52 (2020), 102059. https://doi.org/10.1016/j.ijinfomgt.2019.102059 doi: 10.1016/j.ijinfomgt.2019.102059
|
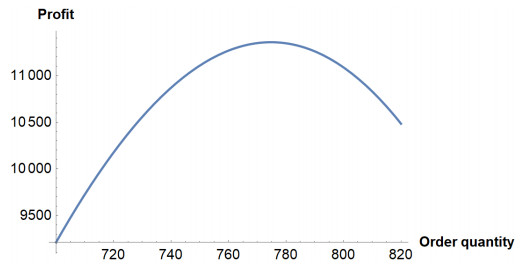
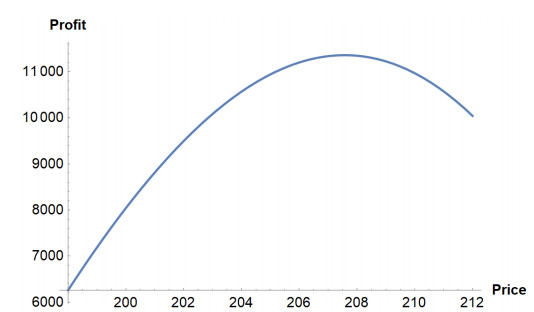
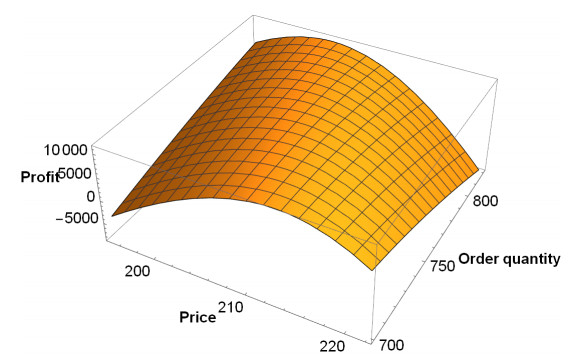
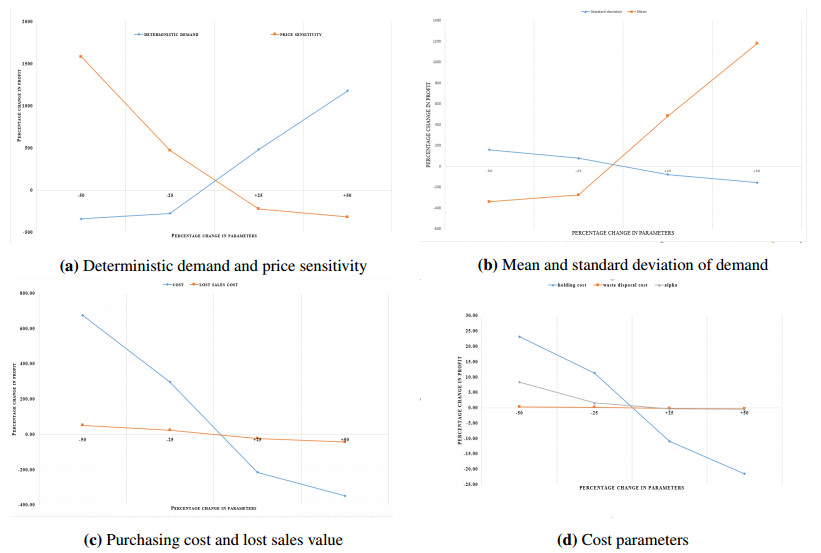
Figures(4) / Tables(5)

Irfanullah Khan, Asif Iqbal Malik, Biswajit Sarkar. A distribution-free newsvendor model considering environmental impact and shortages with price-dependent stochastic demand[J]. Mathematical Biosciences and Engineering, 2023, 20(2): 2459-2481. doi: 10.3934/mbe.2023115







 DownLoad:
DownLoad: