Citation: Swatantra R. Kethireddy, Grace A. Adegoye, Paul B. Tchounwou, Francis Tuluri, H. Anwar Ahmad, John H. Young, Lei Zhang. The status of geo-environmental health in Mississippi: Application of spatiotemporal statistics to improve health and air quality[J]. AIMS Environmental Science, 2018, 5(4): 273-293. doi: 10.3934/environsci.2018.4.273

| [1] | World Health Organization. WHO Air quality guidelines for particulate matter, ozone, nitrogen dioxide and sulfur dioxide: global update 2005: summary of risk assessment. Geneva: World Health Organization, 2006. Available from: http://whqlibdoc.who.int/hq/2006/WHO%7B_%7DSDE%7B_%7DPHE%7B_%7DOEH%7B_%7D06.02%7B_%7Deng.pdf?ua=1 |
| [2] | Health Effects Institute. STATE OF GLOBAL AIR/2017, 2017. Available from: https://www.stateofglobalair.org/sites/default/files/SOGA2017_report.pdf |
| [3] |
Chan TC, Chen ML, Lin IF, et al. (2009) Spatiotemporal analysis of air pollution and asthma patient visits in Taipei, Taiwan. Int J Health Geogr 8: 26. doi: 10.1186/1476-072X-8-26

|
| [4] | Jerrett M, Burnett RT, Ma R, et al. (2005) Spatial analysis of air pollution and mortality in Los Angeles. Epidemiology 16: 727–736. |
| [5] |
Lemke LD, Lamerato LE, Xu X, et al. (2014) Geospatial relationships of air pollution and acute asthma events across the Detroit–Windsor international border: Study design and preliminary results. J Expo Sci Environ Epidemiol 24: 346–357. doi: 10.1038/jes.2013.78
|
| [6] |
Koenig JQ (1999) Air pollution and asthma. J Allergy Clin Immunol 104: 717–722. doi: 10.1016/S0091-6749(99)70280-0
|
| [7] |
D'Amato G (2002) Environmental urban factors (air pollution and allergens) and the rising trends in allergic respiratory diseases. Allergy 57: 30–33. doi: 10.1034/j.1398-9995.57.s72.5.x
|
| [8] |
Khatri SB, Holguin FC, Ryan PB, et al. (2009) Association of ambient ozone exposure with airway inflammation and allergy in adults with asthma. J Asthma 46: 777–785. doi: 10.1080/02770900902779284
|
| [9] |
Lin S, Liu X, Le LH, et al. (2008) Chronic exposure to ambient ozone and asthma hospital admissions among children. Environ Health Perspect 116: 1725–1730. doi: 10.1289/ehp.11184
|
| [10] | Lu H, Qiu F, Cheng Y (2003) Temporal and Spatial Relationship of Ozone and Asthma. In: Esri International User Conference. p. 14. Available from: http://proceedings.esri.com/library/userconf/proc03/p0911.pdf |
| [11] | Kumar N, Liang D, Comellas A, et al. (2013) Satellite-based PM concentrations and their application to COPD in Cleveland, OH. J Expo Sci Environ Epidemiol 23: 637–646. |
| [12] | Schwartz J (2004) Air pollution and children's health. Pediatrics 113: 1037–1043. |
| [13] |
D'Amato G, Liccardi G, D'Amato M, et al. (2005) Environmental risk factors and allergic bronchial asthma. Clin Exp Allergy 35: 1113–1124. doi: 10.1111/j.1365-2222.2005.02328.x
|
| [14] | D'Amato G, Cecchi L, D'Amato M, et al. (2010) Urban air pollution and climate change as environmental risk factors of respiratory allergy: an update. J Investig Allergol Clin Immunol 20: 95–102. |
| [15] | World Health Organization, Health is the key in motivating to solve environmental problems. World Health Organization, 2014. |
| [16] | Davenhall B (2013) Geomedicine. Redlands, CA: Environmental Systems Research Institute, 32. Available from: http://www.esri.com/library/ebooks/geomedicine.pdf |
| [17] | Davenhall B (2010) The Missing Component. ArcUser, 10–11. Available from: http://www.esri.com/news/arcuser/0110/files/geomedicine.pdf |
| [18] | CDC (2010) Asthma's Impact on the Nation, Data from the CDC National Asthma Control Program, 1–4. |
| [19] |
McLafferty S (2003) GIS and health care. Annu Rev Public Health 24: 25–42. doi: 10.1146/annurev.publhealth.24.012902.141012
|
| [20] | MSDH (2011) 2011–2015 Mississippi State Asthma Plan. |
| [21] | Roy SR, McGinty EE, Hayes SC, et al. (2010) Regional and racial disparities in asthma hospitalizations in Mississippi. J Allergy Clin Immunol 125: 636–642. |
| [22] | Carter LM, Jones JW, Berry L, et al. (2014) Climate Change Impacts in the United States: The Third National Climate Assessment. |
| [23] | Portier CJ, Thigpen TK, Carter SR, et al. (2010) A Human Health Perspective on Climate Change: A Report Outlining the Research Needs on the Human Health Effects of Climate Change. Research Triangle Park, NC: Environmental Health Perspectives and the National Institute of Environmental Health Sciences. |
| [24] | NRDC (2012) Toxic Power: How Power Plants Contaminate Our Air and States. Natural Resources Defense Council Environmental News. |
| [25] | McMillin N, Listen to the lungs-The Daily Mississippian. The Daily Mississippian. |
| [26] | Geography UCB, Guide to State and Local Geography-Mississippi, 2014. Available from: https://www.census.gov/geo/reference/guidestloc/st28_ms.html |
| [27] | The National Science and Technology Council, Air Quality Observation Systems in the United States, 2013. Available from: https://obamawhitehouse.archives.gov/sites/default/files/.../air_quality_obs_2013.pdf |
| [28] | U.S. Census Bureau (2008) A Compass for Understanding and Using american Community Survey Data: What General Data Users Need to Know. Washington DC: U.S. Government Printing Office. |
| [29] | U.S. Census Bureau (2008) How Poverty is Calculated in the ACS. |
| [30] | Kurland KS, Gorr WL (2012) GIS Tutorial for Health. Fourth edi. Redlands: Esri Press. |
| [31] | MDEQ, Monitoring Network Plan-2014, 13. |
| [32] | ESRI (2003) The principles of geostatistical analysis. In: ArcGIS 9 Using ArcGIS Geostatistical Analyst. Redlands, CA: Esri Press, 49–78. |
| [33] | Environmental Systems Research Institute I. How Kriging works-Help | ArcGIS for Desktop, 2016. Available from: http://desktop.arcgis.com/en/arcmap/10.3/tools/3d-analyst-toolbox/how-kriging-works.htm# |
| [34] | Susanto F, de Souza P, He J (2016) Spatiotemporal Interpolation for Environmental Modelling. Sensors (Basel) 16. Available from: http://www.ncbi.nlm.nih.gov/pubmed/27509497 |
| [35] | Mukaka MM (2012) Statistics corner: A guide to appropriate use of correlation coefficient in medical research. Malawi Med J 24: 69–71. |
| [36] | The Economist explains, Why are so many people leaving the Mississippi Delta? 2013. Available from: https://www.economist.com/blogs/economist-explains/2013/10/economist-explains-12 |
| [37] | Malik HU, Kumar K, Frieri M (2012) Minimal difference in the prevalence of asthma in the urban and rural environment. Clin Med Insights Pediatr 6: 33–39. |
| [38] | USA Today. Miss. coast shows modest population gains post-Katrina, 2011. Available from: http://usatoday30.usatoday.com/news/nation/census/2011-02-03-census-mississippi%7B_%7DN.htm |
| [39] | CDC(2013) Introduction to Hotspot Analysis. |
| [40] |
Valet RS, Perry TT, Hartert TV (2009) Rural health disparities in asthma care and outcomes. J Allergy Clin Immunol 123: 1220–1225. doi: 10.1016/j.jaci.2008.12.1131
|
| [41] | Luvall J, Quattrochi D, Rickman D (2015) Boundary Layer (Atmospheric) and Air Pollution. In: North GR, Pyle J, Zhang F, editors. Encyclopedia of Atmospheric Sciences. 2nd edition. Elsevier Ltd, 310–318. |
| [42] |
Sears MR (2008) Epidemiology of asthma exacerbations. J Allergy Clin Immunol 122: 662–668. doi: 10.1016/j.jaci.2008.08.003
|
| [43] |
Sears MR, Johnston NW (2007) Understanding the September asthma epidemic. J Allergy Clin Immunol 120: 526–529. doi: 10.1016/j.jaci.2007.05.047
|
| [44] | Minnesota Department of Health, Asthma Hospitalizations Peak in September, 2008. Available from: http://www.health.state.mn.us/asthma/documents/08asthmahosppeaksept.pdf |
| [45] | Federal Register (2013) National Ambient Air Quality Standards for Particulate Matter. 40 CFR Parts 50, 51, 52, 53 and 58 United States of America, 3086–3287. |
| [46] |
Rona RJ (2000) Asthma and poverty. Thorax 55: 239–244. doi: 10.1136/thorax.55.3.239
|
| [47] | Zheng J (2011) Shacks in the Mississippi Delta. Arkansas Rev AJ Delta Stud 42: 30–33. |
| [48] |
Eudy RL (2009) Infant Mortality in the Lower Mississippi Delta: Geography, Poverty and Race. Matern Child Health J 13: 806–813. doi: 10.1007/s10995-008-0311-y
|
| [49] | Abrokwa A, Chan A, Ha M (2010) Coverage Is Not Enough: Health Care Reform through the Lens of the Mississippi Delta. Kennedy Sch Rev. Available from: https://www.highbeam.com/doc/1G1-247740034.html |
| [50] | Seltenrich N (2014) Remote-Sensing Applications for Environmental Health Research. Environ Health Perspect 122: 268–275. |
| [51] |
Gotway CA, Young LJ (2002) Combining incompatible spatial data. J Am Stat Assoc 97: 632–648. doi: 10.1198/016214502760047140
|
| [52] | Pratt M, Moore H, Craig T (2014) Solving a Public Health Problem Using Location-Allocation. ArcUser, 56–59. Available from: http://www.esri.com/~/media/Files/Pdfs/news/arcuser/0614/solving-a-public-health-problem.pdf%5Cnhttp://www.esri.com/~/media/Files/Pdfs/news/arcuser/0614/summer-2014.pdf |
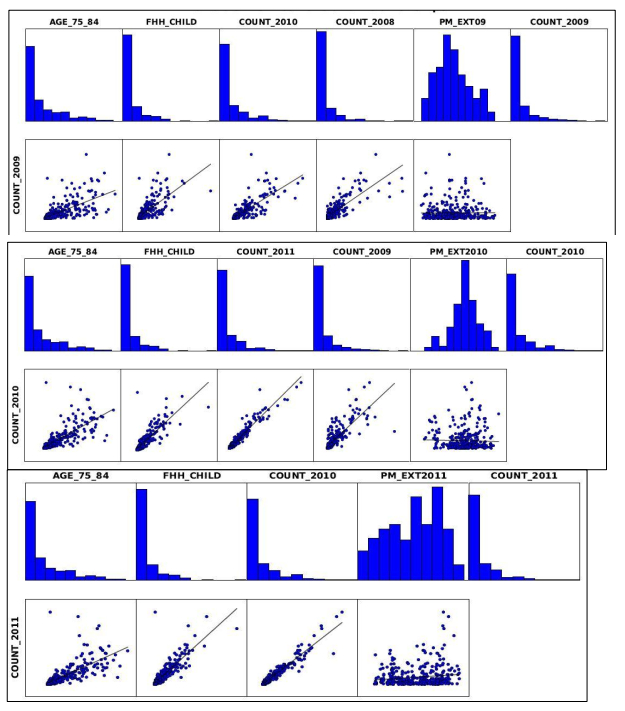
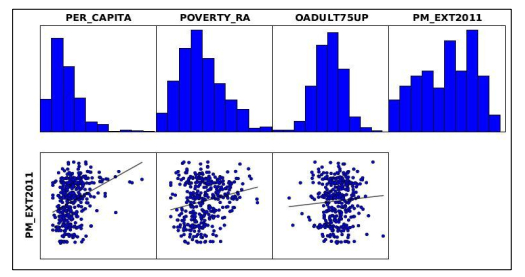
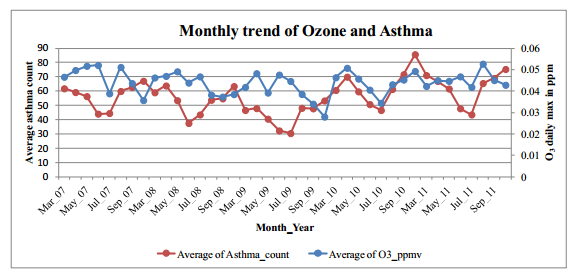
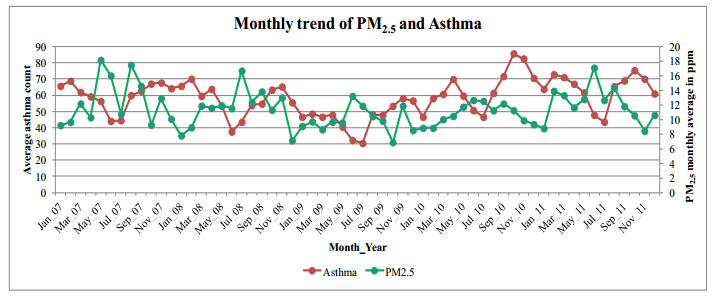
Figures(12) / Tables(2)

Swatantra R. Kethireddy, Grace A. Adegoye, Paul B. Tchounwou, Francis Tuluri, H. Anwar Ahmad, John H. Young, Lei Zhang. The status of geo-environmental health in Mississippi: Application of spatiotemporal statistics to improve health and air quality[J]. AIMS Environmental Science, 2018, 5(4): 273-293. doi: 10.3934/environsci.2018.4.273







 DownLoad:
DownLoad: