The rapid urban development in San Juan, Puerto Rico, initiated by Operation Bootstrap in the late 1940s, has profoundly impacted the historical memory and identity of its inhabitants. This study examines the socioeconomic and cultural effects of transforming the El Fanguito and Tokio slums into the financial hub of Hato Rey. Through a combination of existing interviews and new testimonies, the research explores how the displacement of long-standing communities disrupted residents' sense of belonging and continuity. The findings reveal patterns of exploitation, cultural imperialism, and persistent neglect by the authorities. Despite the challenges, the current residents of Caño Martín Peña have maintained resilience and a collective identity, advocating for their rights and working towards a better future. This study underscores the need for urban planning that balances economic growth with heritage preservation, ensuring that development policies do not erase the cultural and social fabric of the communities.
Citation: Maria Helena Luengo-Duque. Erasing roots: The impact of urban development on historical memory and identity in San Juan[J]. Urban Resilience and Sustainability, 2025, 3(1): 26-56. doi: 10.3934/urs.2025002
The rapid urban development in San Juan, Puerto Rico, initiated by Operation Bootstrap in the late 1940s, has profoundly impacted the historical memory and identity of its inhabitants. This study examines the socioeconomic and cultural effects of transforming the El Fanguito and Tokio slums into the financial hub of Hato Rey. Through a combination of existing interviews and new testimonies, the research explores how the displacement of long-standing communities disrupted residents' sense of belonging and continuity. The findings reveal patterns of exploitation, cultural imperialism, and persistent neglect by the authorities. Despite the challenges, the current residents of Caño Martín Peña have maintained resilience and a collective identity, advocating for their rights and working towards a better future. This study underscores the need for urban planning that balances economic growth with heritage preservation, ensuring that development policies do not erase the cultural and social fabric of the communities.

| [1] |
Caban PA (1989) Industrial transformation and labour relations in Puerto Rico: From 'Operation Bootstrap' to the 1970s. J Lat Am Stud 21: 559–591. https://doi.org/10.1017/S0022216X0001854X doi: 10.1017/S0022216X0001854X

|
| [2] | Torres EV (2023) Obligados a olvidar: Settlement and Displacement in 20th Century San Juan, Puerto Rico. Centro J 35: 7. |
| [3] | Foster WZ (1948) The Crime of El Fanguito, New York: New Century Publishers. Available from: https://www.redstarpublishers.org. |
| [4] |
Molano Camargo F (2016) El derecho a la ciudad: de Henri Lefebvre a los análisis sobre la ciudad capitalista contemporánea. Folios 1: 3–19. http://dx.doi.org/10.17227/01234870.44folios3.19 doi: 10.17227/01234870.44folios3.19
|
| [5] | Lefebvre H (1984) The Production of Space, Cambridge: Library of Congress. |
| [6] |
Miller LL (2005) Root shock: How tearing up city neighborhoods hurts America and what we can do about it. J Health Polit Policy Law 30: 985–990. https://doi.org/10.1215/03616878-30-5-985 doi: 10.1215/03616878-30-5-985
|
| [7] | Francis D (2022) Diébédo Francis Kéré: How first Black winner of architecture's top prize is committed to building 'peaceful cities'. Available from: https://theconversation.com/diebedo-francis-kere-how-first-black-winner-of-architectures-top-prize-is-committed-to-building-peaceful-cities-179483. |
| [8] | Escobar A (2011) Encountering development: The making and unmaking of the Third World, Princeton: Princeton University Press. |
| [9] | Lees L, Slater T, Wyly E (2008) Gentrification, New York: Routledge. https://doi.org/10.4324/9780203940877 |
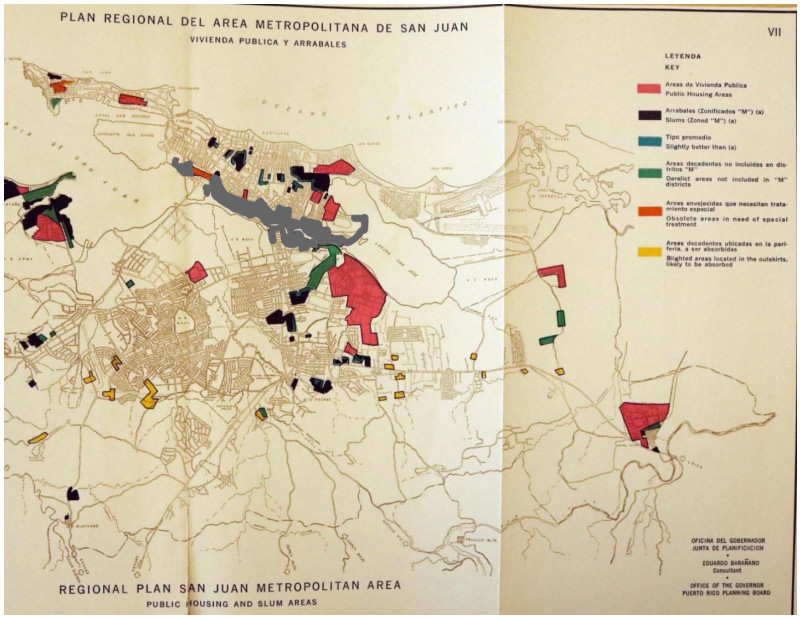
| [10] | Barañano E, Board PRP (1956) Plan regional del area metropolitana de San Juan. Available from: https://issuu.com/coleccionpuertorriquena/docs/plan_regional_san_juan_-_bara_ano_1956. |
| [11] | Google Earth. Available from: https://earth.google.com/web/@18.44669323,-66.04436965,11.84919169a,0d,60y,13.03335891h,94.52861367t,0r/data=CgRCAggBOgMKATBKDQj___________8BEAA. |
| [12] | Archivo Virtual del Instituto de Cultura Puertorriqueña. Available from: https://www.archivoicp.com/cronicas-agpr-final. |
| [13] | Cotto L (1990) La ocupación de tierras como lucha social: Los rescates de terreno en Puerto Rico: 1968–1976. Revista de Ciencias Sociales 408–428. https://api.semanticscholar.org/CorpusID:185039175 |
| [14] | Scarano FA (2010) Spanish Hispaniola and Puerto Rico, In: The Oxford Handbook of Slavery in the Americas, Oxford University Press, 22–45. https://doi.org/10.1093/oxfordhb/9780199227990.013.0002 |
| [15] | Sepúlveda-Rivera A, Carbonell J (1988) Cangrejos-Santurce: Historia Ilustrada de Su Desarrollo Urbano (1519–1950), Viejo San Juan P.R.: Centro de Investigaciones CARIMAR Oficina Estatal de Preservación Histórica. Available from: http://www.worldcat.org/title/cangrejos-santurce-historia-ilustrada-de-su-desarrollo-urbano-1519-1950/oclc/26398917#.W0kXfKpqg5g.mendeley. |
| [16] | Acosta I (2013) Abolition of Slavery (1873), Choice Reviews Online. |
| [17] |
Taylor KY (2018) How real estate segregated America. Dissent 65: 23–32. https://doi.org/10.1353/dss.2018.0071 doi: 10.1353/dss.2018.0071
|
| [18] | Puerto Rico Ilustrado—Digital library of the Caribbean (1936). Available from: https://dloc.com/es/AA00098206/01212/images/22. |
| [19] | El Mundo 1945.02.04—El Mundo Digital Archive. Available from: https://gpa.eastview.com/crl/elmundo/?a=d&d=mndo19451103-01.1.21&e=------194-en-25--1--img-txIN-enver+azizi----1945---es--. |
| [20] | El Mundo 1969.06.06—El Mundo Digital Archive. Available from: https://gpa.eastview.com/crl/elmundo/?a=d&d=mndo19690606-01.1.7&srpos=1&e=-------en-25--1--img-txIN-puerto+rico+siempre+ha+tenido+y+tiene+ahora+una+sutil+estructura+racial----1969---es--. |
| [21] | El Mundo 1971.06.11—El Mundo Digital Archive. Available from: https://gpa.eastview.com/crl/elmundo/?a=d&d=mndo19710611-01.1.41&srpos=1&e=-------en-25--1--img-txIN-adem%c3%a1s+de+algunas+instituciones+religiosas+hay+otras+escuelas+privadas+que+incurren+en+el+racismo-------es--. |
| [22] | 80grados+ (2020) Bomba, prohibiciones y discurso racial en los albores del siglo XX. Available from: https://www.80grados.net/bomba-prohibiciones-y-discurso-racial-en-los-albores-del-siglo-xx/. |
| [23] | Brahms DP (2024) The New Old Deal: Colonial Social Welfare and Puerto Rican Poverty During the Great Depression, 1928–1941. Master's thesis, University of Maryland, College Park, 2024. |
| [24] |
Duany J (2010) Anthropology in a postcolonial colony: Helen I. Safa's contribution to Puerto Rican ethnography. Caribbean Stud 38: 33–57. https://doi.org/10.1353/crb.2010.0054 doi: 10.1353/crb.2010.0054
|
| [25] | Jopling CF (1988) Puerto Rican Houses in Sociohistorical Perspective, Knoxville: University of Tennessee Press. |
| [26] | YouTube Historia Oral del Caño Martín Peña. Available from: https://www.youtube.com/playlist?list=PLMJGEVe252Ekrwl_XJi756WoKgGyplPWF. |
| [27] | Puerto Rico Historic Building Drawings Society (2024). Available from: https://www.facebook.com/PRHBDS. |
| [28] | data.pr.gov, 2018. Available from: https://data.pr.gov/en/Transportaci-n/Annual-Average-Daily-Traffic-AADT-Transito-Promedi/7kaq-zyym. |
| [29] | El Mundo 1949.05.07—El Mundo Digital Archive. Available from: https://gpa.eastview.com/crl/elmundo/?a=d&d=mndo19490507-01.1.1&srpos=1&e=-------en-25--1--img-txIN-%22alcaldesa+rinc%c3%b3n+tuvo+%22---------. |
| [30] | Raíces del Caño (2012) En Peligro la Salud de la Gente del Caño. Available from: https://g8pr.org/wp-content/uploads/2017/05/raices-web-vol-1.pdf. |
| [31] | UWM Libraries Digital Collections (1940) Puerto Rico aerial survey/Army Map Servic. Available from: https://collections.lib.uwm.edu/digital/collection/agdm/id/12469. |
| [32] | EarthExplorer. Available from: https://earthexplorer.usgs.gov/. |
| [33] | Wikipedia, la enciclopedia libre, Centro ceremonial indígena de Tibes. Available from: https://es.wikipedia.org/wiki/Centro_ceremonial_ind%C3%ADgena_de_Tibes. |
| [34] | 80grados+ (2019) Casas jíbaras: Anotaciones sobre arquitectura y tradición. Available from: https://www.80grados.net/casas-jibaras-anotaciones-sobre-arquitectura-y-tradicion-en-puerto-rico/. |
| [35] | San Juan, Puerto Rico. In the huge slum area known as "El Fangitto". Available from: https://www.loc.gov/item/2017798491/. |
| [36] | Moscioni A (2005) El Fanguito, Santurce. Available from: https://upr.contentdm.oclc.org/digital/collection/Moscioni/id/1234/rec/1. |
| [37] | Davis D (2016) The production of space and violence in cities of the global south: Evidence from Latin America. Nóesis: Revista de Ciencias Sociales y Humanidades 25: 1–15. |
| [38] | Currie LJ (1951) Housing, Puerto Rico. Available from: https://jstor.org/stable/community.16799280. |
| [39] | Dinzey-Flores ZZ (2013) Locked in, Locked out: Gated Communities in a Puerto Rican City, University of Pennsylvania Press. |
| [40] | Agencia EFE (2023) La gentrificación avanza a toda velocidad en Puerto Rico. Available from: https://www.primerahora.com/noticias/gobierno-politica/notas/la-gentrificacion-avanza-a-toda-velocidad-en-puerto-rico/. |
| [41] | E-Data—Departamento de Educación de PR. Available from: https://de.pr.gov/academico/secretaria-auxiliar-de-planificacion-y-rendimiento/edata/. |
| [42] |
Dinzey-Flores ZZ (2011) Criminalizing communities of poor, dark women in the Caribbean: The fight against crime through Puerto Rico's public housing. Crime Prev Community Saf 13: 53–73. https://doi.org/10.1057/cpcs.2010.18 doi: 10.1057/cpcs.2010.18
|
| [43] |
Davis DE (2018) The routinization of violence in Latin America: Ethnographic revelations. Latin Am Res Rev 53: 211–216. https://doi.org/10.25222/larr.425 doi: 10.25222/larr.425
|
| [44] | Instituto de Estadísticas de PR (2024) Violent deaths reporting system Puerto Rico. Available from: https://estadisticas.pr/files/Publicaciones/Informe%20PRVDRS%202021%20English%20version.pdf. |
| [45] | Data USA (2019) Puerto Rico. Available from: https://datausa.io/profile/geo/puerto-rico/. |
| [46] | U.S. Department of Commerce (2018) U.S. Census Bureau QuickFacts: Puerto Rico, 2018. Available from: www.census.gov/quickfacts/PR. |
| [47] |
Mattei J, Tamez M, Ríos-Bedoya CF, et al. (2018) Health conditions and lifestyle risk factors of adults living in Puerto Rico: A cross-sectional study. BMC Public Health 18: 1–12. https://doi.org/10.1186/s12889-018-5359-z doi: 10.1186/s12889-018-5359-z
|
| [48] | Coleman D (2008) The persistence of the past in the Albaicín: Granada's New Mosque and the question of historical relevance, In: In the Light of Medieval Spain: Islam, the West, and the Relevance of the Past, New York: Palgrave Macmillan, 157–188. https://doi.org/10.1057/9780230614086_8 |
| [49] | Algoed L, Torrales MEH (2019) The land is ours. Vulnerabilization and resistance in informal settlements in Puerto Rico: Lessons from the Cano Martin Pena community land trust. Radical Hous J 1: 29–47. |
| [50] |
Urban F (2015) La Perla—100 years of informal architecture in San Juan, Puerto Rico. Plan Perspect 30: 495–536. https://doi.org/10.1080/02665433.2014.1003247 doi: 10.1080/02665433.2014.1003247
|
| [51] | Cerreta M, La Rocca L (2021) Urban regeneration processes and social impact: A literature review to explore the role of evaluation, in Computational Science and Its Applications—ICCSA 2021, Cham: Springer, 167–182.https://doi.org/10.1007/978-3-030-86979-3_13 |
| [52] |
Duany J (2000) Nation on the move: The construction of cultural identities in Puerto Rico and the diaspora. Am Ethnol 27: 5–30. https://doi.org/10.1525/ae.2000.27.1.5 doi: 10.1525/ae.2000.27.1.5
|
| [53] | Dovey K, van Oostrum M, Shafique T, et al. (2023) Atlas of Informal Settlement: Understanding Self-organized Urban Design, Bloomsbury Publishing. |
| [54] |
Pojani D (2019) The self-built city: Theorizing urban design of informal settlements. Archnet-IJAR 13: 294–313. https://doi.org/10.1108/ARCH-11-2018-0004 doi: 10.1108/ARCH-11-2018-0004
|



















Figures(20)
Maria Helena Luengo-Duque. Erasing roots: The impact of urban development on historical memory and identity in San Juan[J]. Urban Resilience and Sustainability, 2025, 3(1): 26-56. doi: 10.3934/urs.2025002







 DownLoad:
DownLoad: