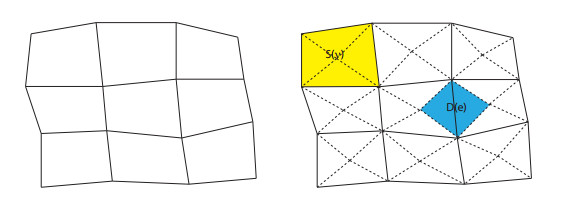
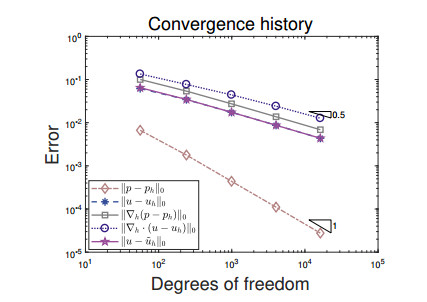
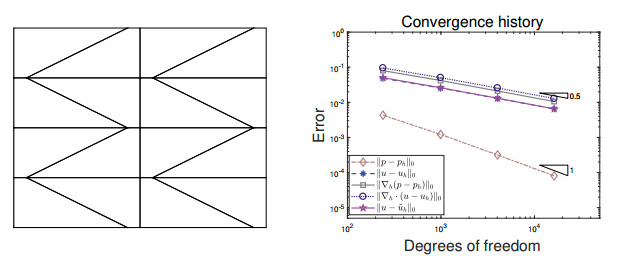
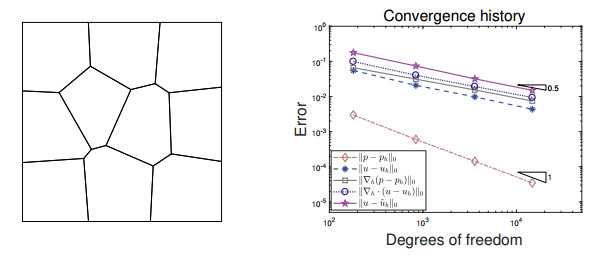
In this paper, we propose a novel staggered least squares method for elliptic equations on polygonal meshes. Our new method can be flexibly applied to rough grids and allows hanging nodes, which is of particular interest in practical applications. Moreover, it offers the advantage of not having to deal with inf-sup conditions and yielding positive definite discrete problems. Optimal a priori error estimates in energy norm are derived. In addition, a superconvergent estimates in energy norm are also developed by employing variational error expansion. The main difficulty involved here is to show the $ L^2 $ norm error estimates for the potential variable, where duality argument and the superconvergent estimates are the key ingredients. The single valued flux over the outer boundary of the dual partition enables us to construct a locally conservative flux. Numerical experiments confirm the theoretical findings and the performance of the adaptive mesh refinement guided by the least squares functional estimator are also displayed.
Citation: Lina Zhao, Eun-Jae Park. A locally conservative staggered least squares method on polygonal meshes[J]. Mathematics in Engineering, 2024, 6(2): 339-362. doi: 10.3934/mine.2024014
In this paper, we propose a novel staggered least squares method for elliptic equations on polygonal meshes. Our new method can be flexibly applied to rough grids and allows hanging nodes, which is of particular interest in practical applications. Moreover, it offers the advantage of not having to deal with inf-sup conditions and yielding positive definite discrete problems. Optimal a priori error estimates in energy norm are derived. In addition, a superconvergent estimates in energy norm are also developed by employing variational error expansion. The main difficulty involved here is to show the $ L^2 $ norm error estimates for the potential variable, where duality argument and the superconvergent estimates are the key ingredients. The single valued flux over the outer boundary of the dual partition enables us to construct a locally conservative flux. Numerical experiments confirm the theoretical findings and the performance of the adaptive mesh refinement guided by the least squares functional estimator are also displayed.

| [1] | P. F. Antonietti, S. Giani, P. Houston, $hp$-version composite discontinuous Galerkin methods for elliptic problems on complicated domains, SIAM J. Sci. Comput., 35 (2013), A1417–A1439. https://doi.org/10.1137/120877246 |
| [2] | D. N. Arnold, D. Boffi, R. S. Falk, Quadrilateral $H$(div) finite elements, SIAM J. Numer. Anal., 42 (2005), 2429–2451. https://doi.org/10.1137/S0036142903431924 |
| [3] | R. E. Bank, J. Xu, Asymptotically exact a posteriori error estimators, Part I: Grids with superconvergence, SIAM J. Numer. Anal., 41 (2003), 2294–2312. https://doi.org/10.1137/S003614290139874X |
| [4] | F. Bassi, L. Botti, A. Colombo, D. Di Pietro, P. Tesini, On the flexibility of agglomeration based physical space discontinuous Galerkin discretizations, J. Comput. Phys., 231 (2012), 45–65. https://doi.org/10.1016/j.jcp.2011.08.018 |
| [5] | L. Beirão da Veiga, F. Brezzi, A. Cangiani, G. Manzini, L. D. Marini, A. Russo, Basic principles of virtual element method, Math. Mod. Meth. Appl. Sci., 23 (2013), 199–214. https://doi.org/10.1142/S0218202512500492 |
| [6] | P. B. Bochev, M. D. Gunzburger, Accuracy of least-squares methods for the Navier-Stokes equations, Comput. Fluids, 22 (1993), 549–563. https://doi.org/10.1016/0045-7930(93)90025-5 |
| [7] | P. B. Bochev, M. D. Gunzburger, Analysis of least-squares finite element methods for the Stokes equations, Math. Comp., 63 (1994), 479–506. |
| [8] | P. B. Bochev, M. D. Gunzburger, A locally conservative least-squares method for Darcy flows, Commum. Numer. Meth. Eng., 24 (2008), 97–110. https://doi.org/10.1002/cnm.957 |
| [9] | J. H. Brandts, Superconvergence and a posteriori error estimation for triangular mixed finite elements, Numer. Math., 68 (1994), 311–324. https://doi.org/10.1007/s002110050064 |
| [10] |
S. C. Brenner, Poincaré-Friedrichs inequalities for piecewise $H^1$ functions, SIAM J. Numer. Anal., 41 (2003), 306–324. https://doi.org/10.1137/S0036142902401311 doi: 10.1137/S0036142902401311

|
| [11] | Z. Cai, V. Carey, J. Ku, E. J. Park, Asymptotically exact a posteriori error estimators for first-order div least-squares methods in local and global $L_2$ norm, Comput. Math. Appl., 70 (2015), 648–659. https://doi.org/10.1016/j.camwa.2015.05.010 |
| [12] |
Z. Cai, J. Ku, The $L^2$ norm error estimates for the div least-squares method, SIAM J. Numer. Anal., 44 (2006), 1721–1734. https://doi.org/10.1137/050636504 doi: 10.1137/050636504
|
| [13] |
Z. Cai, R. Lazarov, T. Manteuffel, S. McCormick, First order system least-squares for second-order partial differential equations: Part I, SIAM J. Numer. Anal., 31 (1994), 1785–1799. https://doi.org/10.1137/0731091 doi: 10.1137/0731091
|
| [14] |
Z. Cai, G. Starke, Least-squares methods for linear elasticity, SIAM J. Numer. Anal., 42 (2004), 826–842. https://doi.org/10.1137/S0036142902418357 doi: 10.1137/S0036142902418357
|
| [15] |
A. Cangiani, E. H. Georgoulis, T. Pryer, O. J. Sutton, A posteriori error estimates for the virtual element method, Numer. Math., 137 (2017), 857–893. https://doi.org/10.1007/s00211-017-0891-9 doi: 10.1007/s00211-017-0891-9
|
| [16] | A. Cangiani, Z. Dong, E. H. Georgoulis, P. Houston, hp-version discontinuous Galerkin methods on polytopic meshes, Springer, 2017. https://doi.org/10.1007/978-3-319-67673-9 |
| [17] |
C. Carstensen, E. J. Park, Convergence and optimality of adaptive least squares finite element methods, SIAM. J. Numer. Anal., 53 (2015), 43–62. https://doi.org/10.1137/130949634 doi: 10.1137/130949634
|
| [18] |
C. Carstensen, E. J. Park, P. Bringmann, Convergence of natural adaptive least squares finite element methods, Numer. Math., 136 (2017), 1097–1115. https://doi.org/10.1007/s00211-017-0866-x doi: 10.1007/s00211-017-0866-x
|
| [19] |
C. L. Chang, A least-squares finite element method for the Helmholtz equation, Comput. Meth. Appl. Mech. Eng., 83 (1990), 1–7. https://doi.org/10.1016/0045-7825(90)90121-2 doi: 10.1016/0045-7825(90)90121-2
|
| [20] |
E. T. Chung, B. Engquist, Optimal discontinuous Galerkin methods for wave propagation, SIAM J. Numer. Anal., 44 (2006), 2131–2158. https://doi.org/10.1137/050641193 doi: 10.1137/050641193
|
| [21] |
E. T. Chung, B. Engquist, Optimal discontinuous Galerkin methods for the acoustic wave equation in higher dimensions, SIAM J. Numer. Anal., 47 (2009), 3820–3848. https://doi.org/10.1137/080729062 doi: 10.1137/080729062
|
| [22] |
E. T. Chung, E. J. Park, L. Zhao, Guaranteed a posteriori error estimates for a staggered discontinuous Galerkin method, J. Sci. Comput., 75 (2018), 1079–1101. https://doi.org/10.1007/s10915-017-0575-8 doi: 10.1007/s10915-017-0575-8
|
| [23] | P. G. Ciarlet, The finite element method for elliptic problems, North-Holland Publishing Company, 1978. |
| [24] | B. Cockburn, J. Gopalakrishnan, R. Lazarov, Unified hybridization of discontinuous Galerkin, mixed, and continuous Galerkin methods for second order elliptic problems, SIAM J. Numer. Anal., 47 (2009), 1319–1365. https://doi.org/10.1137/070706616 |
| [25] | D. A. Di Pietro, A. Ern, S. Lemaire, An arbitrary-order and compact-stencil discretization of diffusion on general meshes based on local reconstruction operators, Comput. Meth. Appl. Math., 14 (2014), 461–472. https://doi.org/10.1515/cmam-2014-0018 |
| [26] |
R. E. Ewing, R. D. Lazarov, J. Wang, Superconvergence of the velocity along the Gauss lines in mixed finite element methods, SIAM J. Numer. Anal., 28 (1991), 1015–1029. https://doi.org/10.1137/0728054 doi: 10.1137/0728054
|
| [27] |
R. E. Ewing, M. M. Liu, J. Wang, Superconvergence of mixed finite element approximations over quadrilaterals, SIAM J. Numer. Anal., 36 (1999), 772–787. https://doi.org/10.1137/S0036142997322801 doi: 10.1137/S0036142997322801
|
| [28] |
Y. Huang, J. Xu, Superconvergence of quadratic finite elements on mildly structured grids, Math. Comp., 77 (2008), 1253–1268. https://doi.org/10.1090/S0025-5718-08-02051-6 doi: 10.1090/S0025-5718-08-02051-6
|
| [29] |
J. Jou, J. L. Liu, A posteriori least-squares finite element error analysis for the Navier-Stokes equations, Numer. Funct. Anal. Optim., 24 (2003), 67–74. https://doi.org/10.1081/NFA-120020245 doi: 10.1081/NFA-120020245
|
| [30] |
D. Kim, L. Zhao, E. J. Park, Staggered DG methods for the pseudostress-velocity formulation of the Stokes equations on general meshes, SIAM J. Sci. Comput., 42 (2020), A2537–A2560. https://doi.org/10.1137/20M1322170 doi: 10.1137/20M1322170
|
| [31] | D. Kim, L. Zhao, E. J. Park, Review and implementation of staggered DG methods on polygonal meshes, J. Korean Soc. Ind. Appl. Math., 25 (2021), 66–81. |
| [32] |
J. Ku, E. J. Park, A posteriori error estimators for the first-order least-squares finite element method, J. Comput. Appl. Math., 235 (2010), 293–300. https://doi.org/10.1016/j.cam.2010.06.004 doi: 10.1016/j.cam.2010.06.004
|
| [33] |
Y. W. Li, Global superconvergence of the lowest-order mixed finite element on mildly structured meshes, SIAM J. Numer. Anal., 56 (2018), 792–815. https://doi.org/10.1137/17M112587X doi: 10.1137/17M112587X
|
| [34] |
R. Rannacher, A posteriori error estimation in least-squares stabilized finite element schemes, Comput. Meth. Appl. Mech. Eng., 166 (1998), 99–114. https://doi.org/10.1016/S0045-7825(98)00085-1 doi: 10.1016/S0045-7825(98)00085-1
|
| [35] |
J. Wang, Superconvergence and extrapolation for mixed finite element methods on rectangular domains, Math. Comp., 56 (1991), 477–503. https://doi.org/10.1090/S0025-5718-1991-1068807-0 doi: 10.1090/S0025-5718-1991-1068807-0
|
| [36] | J. Wang, X. Ye, A weak Galerkin mixed finite element method for second order elliptic problems, Math. Comp., 83 (2014), 2101–2126. |
| [37] |
J. Xu, Z. Zhang, Analysis of recovery type a posteriori error estimators for mildly structured grids, Math. Comp., 73 (2003), 1139–1152. https://doi.org/10.1090/S0025-5718-03-01600-4 doi: 10.1090/S0025-5718-03-01600-4
|
| [38] |
L. Zhao, E. J. Park, Fully computable bounds for a staggered discontinuous Galerkin method for the Stokes equations, Comput. Math. Appl., 75 (2018), 4115–4134. https://doi.org/10.1016/j.camwa.2018.03.018 doi: 10.1016/j.camwa.2018.03.018
|
| [39] |
L. Zhao, E. J. Park, A staggered discontinuous Galerkin method of minimal dimension on quadrilateral and polygonal meshes, SIAM J. Sci. Comput., 40 (2018), 2543–2567. https://doi.org/10.1137/17M1159385 doi: 10.1137/17M1159385
|
| [40] | L. Zhao, E. J. Park, D. W. Shin, A staggered discontinuous Galerkin method for the Stokes equations on general meshes, Comput. Meth. Appl. Mech. Eng., 345 (2019), 854–875. |
| [41] |
L. Zhao, E. T. Chung, E. J. Park, G. Zhou, Staggered DG method for coupling of the Stokes and Darcy-Forchheimer problems, SIAM J. Numer. Anal., 59 (2021), 1–31. https://doi.org/10.1137/19M1268525 doi: 10.1137/19M1268525
|
| [42] |
L. Zhao, E. J. Park, A new hybrid staggered discontinuous Galerkin method on general meshes, J. Sci. Comput., 82 (2020), 12. https://doi.org/10.1007/s10915-019-01119-6 doi: 10.1007/s10915-019-01119-6
|
| [43] |
L. Zhao, E. J. Park, A staggered cell-centered DG method for linear elasticity on polygonal meshes, SIAM J. Sci. Comput., 42 (2020), A2158–A2181. https://doi.org/10.1137/19M1278016 doi: 10.1137/19M1278016
|
| [44] |
L. Zhao, E. J. Park, A staggered discontinuous Galerkin method for quasi-linear second order elliptic problems of nonmonotone type, Comput. Meth. Appl. Math., 22 (2022), 729–750. https://doi.org/10.1515/cmam-2022-0081 doi: 10.1515/cmam-2022-0081
|
Figures(8) / Tables(2)

Lina Zhao, Eun-Jae Park. A locally conservative staggered least squares method on polygonal meshes[J]. Mathematics in Engineering, 2024, 6(2): 339-362. doi: 10.3934/mine.2024014







 DownLoad:
DownLoad: