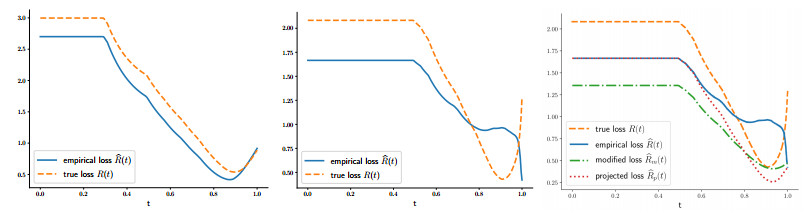
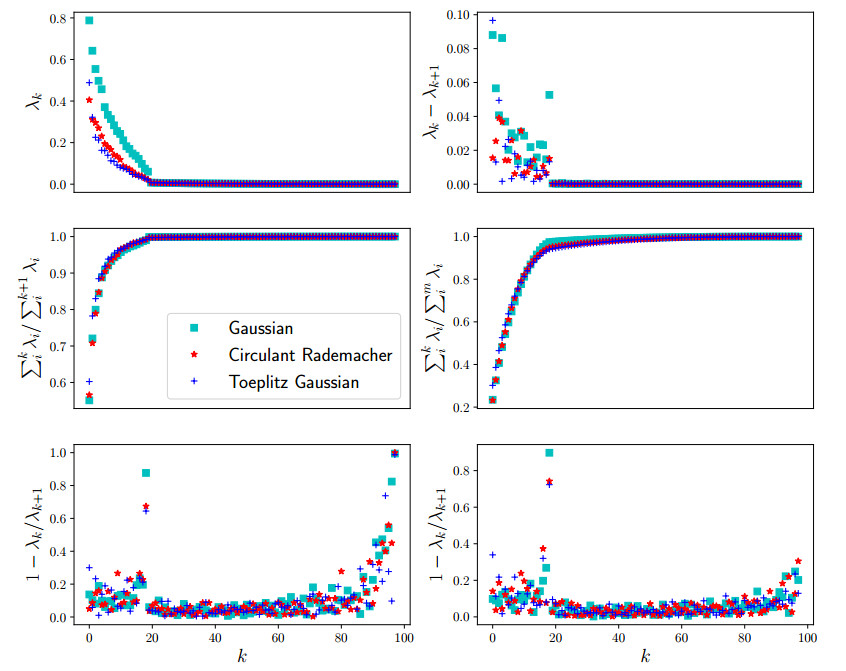
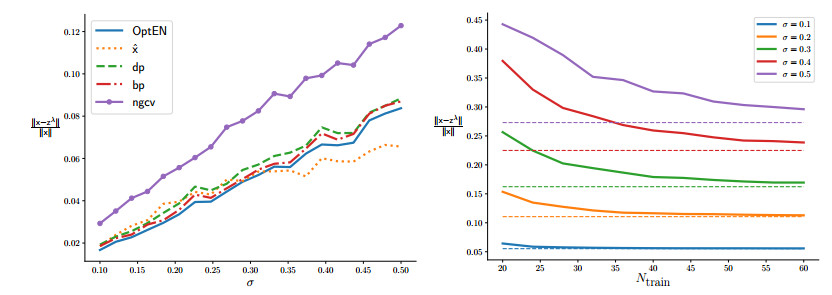
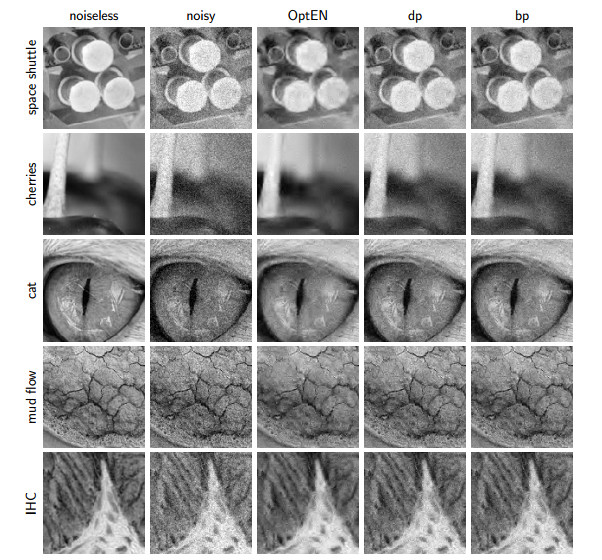
Despite recent advances in regularization theory, the issue of parameter selection still remains a challenge for most applications. In a recent work the framework of statistical learning was used to approximate the optimal Tikhonov regularization parameter from noisy data. In this work, we improve their results and extend the analysis to the elastic net regularization. Furthermore, we design a data-driven, automated algorithm for the computation of an approximate regularization parameter. Our analysis combines statistical learning theory with insights from regularization theory. We compare our approach with state-of-the-art parameter selection criteria and show that it has superior accuracy.
Citation: Zeljko Kereta, Valeriya Naumova. On an unsupervised method for parameter selection for the elastic net[J]. Mathematics in Engineering, 2022, 4(6): 1-36. doi: 10.3934/mine.2022053
Despite recent advances in regularization theory, the issue of parameter selection still remains a challenge for most applications. In a recent work the framework of statistical learning was used to approximate the optimal Tikhonov regularization parameter from noisy data. In this work, we improve their results and extend the analysis to the elastic net regularization. Furthermore, we design a data-driven, automated algorithm for the computation of an approximate regularization parameter. Our analysis combines statistical learning theory with insights from regularization theory. We compare our approach with state-of-the-art parameter selection criteria and show that it has superior accuracy.

| [1] |
S. W. Anzengruber, R. Ramlau, Morozov's discrepancy principle for Tikhonov-type functionals with nonlinear operators, Inverse Probl., 26 (2010), 025001. doi: 10.1088/0266-5611/26/2/025001

|
| [2] | A. Astolfi, Optimization: An introduction, 2006. |
| [3] |
F. Bauer, M. A. Lukas, Comparing parameter choice methods for regularization of ill-posed problems, Math. Comput. Simulat., 81 (2011), 1795–1841. doi: 10.1016/j.matcom.2011.01.016
|
| [4] | M. Belkin, P. Niyogi, V. Sindhwani, Manifold regularization: A geometric framework for learning from labeled and unlabeled examples, J. Mach. Learn. Res., 7 (2006), 2399–2434. |
| [5] | R. Bhatia, Matrix analysis, New York: Springer-Verlag, 1997. |
| [6] |
T. Bonesky, Morozov's discrepancy principle and Tikhonov-type functionals, Inverse Probl., 25 (2009), 015015. doi: 10.1088/0266-5611/25/1/015015
|
| [7] |
A. Chambolle, R. DeVore, N. Lee, B. Lucier, Nonlinear wavelet image processing: variational problems, compression, and noise removal through wavelet shrinkage, IEEE Trans. Image Process., 7 (1998), 319–335. doi: 10.1109/83.661182
|
| [8] |
A. Chambolle, P. L. Lions, Image recovery via total variation minimization and related problems, Numer. Math., 76 (1997), 167–188. doi: 10.1007/s002110050258
|
| [9] |
C. De Mol, E. De Vito, L. Rosasco, Elastic-net regularisation in learning theory, J. Complexity, 25 (2009), 201–230. doi: 10.1016/j.jco.2009.01.002
|
| [10] | E. De Vito, M. Fornasier, V. Naumova, A machine learning approach to optimal Tikhonov regularization I: affine manifolds, Anal. Appl., 2021, in press. |
| [11] |
C.-A. Deledalle, S. Vaiter, J. Fadili, G. Peyré, Stein Unbiased GrAdient estimator of the Risk (SUGAR) for multiple parameter selection, SIAM J. Imaging Sci., 7 (2014), 2448–2487. doi: 10.1137/140968045
|
| [12] |
D. L. Donoho, De-noising by soft-thresholding, IEEE Trans. Inform. Theory, 41 (1995), 613–627. doi: 10.1109/18.382009
|
| [13] |
D. L. Donoho, I. Johnstone, Ideal spatial adaptation via wavelet shrinkage, Biometrika, 81 (1994), 425–455. doi: 10.1093/biomet/81.3.425
|
| [14] | B. Efron, T. Hastie, I. Johnstone, R. Tibshirani, Least angle regression, The Annals of Statistics, 32 (2004), 407–499. |
| [15] |
Y. C. Eldar, Generalized SURE for exponential families: applications to regularization, IEEE Trans. Signal Process., 57 (2009), 471–481. doi: 10.1109/TSP.2008.2008212
|
| [16] | H. W. Engl, M. Hanke, A. Neubauer, Regularization of inverse problems, Dordrecht: Kluwer Academic Publishers, 1996. |
| [17] |
W. J. Fu, Nonlinear GCV and quasi-GCV for shrinkage models, J. Stat. Plan. Infer., 131 (2005), 333–347. doi: 10.1016/j.jspi.2004.03.001
|
| [18] |
R. Giryes, M. Elad, Y. C. Eldar, The projected GSURE for automatic parameter tuning in iterative shrinkage methods, Appl. Comput. Harmonic Anal., 30 (2011), 407–422. doi: 10.1016/j.acha.2010.11.005
|
| [19] |
G. H. Golub, M. Heath, G. Wahba, Generalized cross-validation as a method for choosing a good ridge parameter, Technometrics, 21 (1979), 215–223. doi: 10.1080/00401706.1979.10489751
|
| [20] |
P. C. Hansen, Analysis of discrete ill-posed problems by means of the L-curve, SIAM Rev., 34 (1992), 561–580. doi: 10.1137/1034115
|
| [21] | B. Hofmann, Regularization for applied inverse and ill-posed problems: a numerical approach, Springer-Verlag, 2013. |
| [22] |
B. Jin, D. Lorenz, S. Schiffler, Elastic-net regularisation: error estimates and active set methods, Inverse Probl., 25 (2009), 115022. doi: 10.1088/0266-5611/25/11/115022
|
| [23] |
O. Lepskii, On a problem of adaptive estimation in Gaussian white noise, Theory Probab. Appl., 35 (1991), 454–466. doi: 10.1137/1135065
|
| [24] | A. Lorbert, P. Ramadge, Descent methods for tuning parameter refinement, In: Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, 2010,469–476. |
| [25] | V. A. Morozov, Methods for solving incorrectly posed problems, Springer Science & Business Media, 2012. |
| [26] |
E. Novak, H. Woźniakowski, Optimal order of convergence and (in)tractability of multivariate approximation of smooth functions, Constr. Approx., 30 (2009), 457–473. doi: 10.1007/s00365-009-9069-8
|
| [27] | C. M. Stein, Estimation of the mean of a multivariate normal distribution, Ann. Statist., 9 (1981), 1135–1151. |
| [28] | W. Su, M. Bogdan, E. Candés, False discoveries occur early on the Lasso path, Ann. Statist., 45 (2017), 2133–2150. |
| [29] |
U. Tautenhahn, U. Hämarik, The use of monotonicity for choosing the regularization parameter in ill-posed problems, Inverse Probl., 15 (1999), 1487–1505. doi: 10.1088/0266-5611/15/6/307
|
| [30] |
A. Tikhonov, V. Glasko, Use of the best rate of adaptive estimation in some inverse problems, USSR Computational Mathematics and Mathematical Physics, 5 (1965), 93–107. doi: 10.1016/0041-5553(65)90150-3
|
| [31] | A. N. Tikhonov, V. Y. Arsenin, Solutions of ill-posed problems, Washington, D. C.: V. H. Winston & Sons, New York: John Wiley & Sons, 1977. |
| [32] | J. A. Tropp, An introduction to matrix concentration inequalities, Now Foundations and Trends, 2015. |
| [33] | R. Vershynin, High-dimensional probability: An introduction with applications in data science, Cambridge University Press, 2018. |
| [34] |
E. De Vito, S. Pereverzyev, L. Rosasco, Adaptive kernel methods using the balancing principle, Found. Comput. Math., 10 (2010), 455–479. doi: 10.1007/s10208-010-9064-2
|
| [35] |
Z. Wang, A. C. Bovik, H. R. Sheikh, E. P. Simoncelli, Image quality assessment: from error visibility to structural similarity, IEEE Trans. Image Process., 13 (2004), 600–612. doi: 10.1109/TIP.2003.819861
|
| [36] |
S. N. Wood, Modelling and smoothing parameter estimation with multiple quadratic penalties, J. Roy. Stat. Soc. B, 62 (2000), 413–428. doi: 10.1111/1467-9868.00240
|
| [37] |
H. Zou, T. Hastie, Regularisation and variable selection via the elastic net, J. Roy. Stat. Soc. B, 67 (2005), 301–320. doi: 10.1111/j.1467-9868.2005.00503.x
|
Figures(6) / Tables(4)

Zeljko Kereta, Valeriya Naumova. On an unsupervised method for parameter selection for the elastic net[J]. Mathematics in Engineering, 2022, 4(6): 1-36. doi: 10.3934/mine.2022053







 DownLoad:
DownLoad: