The prediction of bovine infectious diseases is a constant challenge as generally, only laboratory data is available not allowing the study of their relationship with each disease's risk factors. The diseases neosporosis and bovine viral diarrhea, which are present in Colombia, the United States, Mexico, Brazil, and Argentina, cause reproductive problems in cattle and generate economic losses for ranchers. Although there are mathematical models that can evaluate which cattle are susceptible to these diseases, these provide limited information, maintaining the need for a model that provides information on both transmission and mechanisms for controlling the disease. In this article, a machine learning model is presented that combines laboratory data with risk factors in a neural network to predict the presence of bovine neosporosis. The proposed model was implemented with data from previous studies conducted in the municipality of Sotaquirá, Boyacá, Colombia, and obtained an accuracy of 94% in predicting the presence of the disease. It can be concluded that incorporating laboratory data into machine learning algorithms improves the prediction of the presence of these diseases. Furthermore, the proposed system not only predicts but also provides useful information for clinical decision-making, making it a valuable tool in the veterinary field.
Citation: Javier Antonio Ballesteros-Ricaurte, Ramon Fabregat, Angela Carrillo-Ramos, Carlos Parra, Andrés Moreno. Artificial neural networks to predict the presence of Neosporosis in cattle[J]. Mathematical Biosciences and Engineering, 2025, 22(5): 1140-1158. doi: 10.3934/mbe.2025041
The prediction of bovine infectious diseases is a constant challenge as generally, only laboratory data is available not allowing the study of their relationship with each disease's risk factors. The diseases neosporosis and bovine viral diarrhea, which are present in Colombia, the United States, Mexico, Brazil, and Argentina, cause reproductive problems in cattle and generate economic losses for ranchers. Although there are mathematical models that can evaluate which cattle are susceptible to these diseases, these provide limited information, maintaining the need for a model that provides information on both transmission and mechanisms for controlling the disease. In this article, a machine learning model is presented that combines laboratory data with risk factors in a neural network to predict the presence of bovine neosporosis. The proposed model was implemented with data from previous studies conducted in the municipality of Sotaquirá, Boyacá, Colombia, and obtained an accuracy of 94% in predicting the presence of the disease. It can be concluded that incorporating laboratory data into machine learning algorithms improves the prediction of the presence of these diseases. Furthermore, the proposed system not only predicts but also provides useful information for clinical decision-making, making it a valuable tool in the veterinary field.

| [1] |
J. A. Ballesteros-Ricaurte, R. Fabregat, A. Carrillo-Ramos, C. Parra, M. O. Pulido-Medellín, Systematic literature review of models used in the epidemiological analysis of bovine infectious diseases, Electronics, 11 (2022), 2463. https://doi.org/10.3390/electronics11152463 doi: 10.3390/electronics11152463

|
| [2] | G. M. Figueredo, Serological Survey of Bovine Infectious Causes of Reproductive Disordes in Colombia, Ph.D thesis, University of Parma, 2011. |
| [3] | M. O. Pulido-Medellín, D. García-Corredor, R. Andrade-Becerra, Seroprevalencia de Sarcocystis spp. en un hato lechero del municipio de Toca, Colombia, Rev. Salud Anim., 35 (2013), 159–163. |
| [4] |
B. P. Nguyen, H. N. Pham, H. Tran, N. Nghiem, Q. H. Nguyen, T. Do, et al., Predicting the onset of type 2 diabetes using wide and deep learning with electronic health records, Comput. Methods Programs Biomed., 182 (2019), 105055. https://doi.org/10.1016/j.cmpb.2019.105055 doi: 10.1016/j.cmpb.2019.105055
|
| [5] |
J. A. Cruz, D. S. Wishart, Applications of machine learning in cancer prediction and prognosis, Cancer Inform., 2 (2006), 59–78. https://doi.org/10.1177/117693510600200030 doi: 10.1177/117693510600200030
|
| [6] |
R. Miotto, L. Li, B. A. Kidd, J. T. Dudley, Deep patient: An unsupervised representation to predict the future of patients from the electronic health records, Sci. Rep., 6 (2016), 26094. https://doi.org/10.1038/srep26094 doi: 10.1038/srep26094
|
| [7] |
T. Bhardwaj, P. Somvanshi, Machine learning toward infectious disease treatment, Adv. Intell. Syst. Comput., 748 (2019), 683–693. https://doi.org/10.1007/978-981-13-0923-6_58 doi: 10.1007/978-981-13-0923-6_58
|
| [8] |
P. Sajda, Machine learning for detection and diagnosis of disease, Annu. Rev. Biomed. Eng., 8 (2006), 537–565. https://doi.org/10.1146/annurev.bioeng.8.061505.095802 doi: 10.1146/annurev.bioeng.8.061505.095802
|
| [9] |
S. Oh, J. Cha, M. Ji, H. Kang, S. Kim, E. Heo, et al., Architecture design of healthcare software-as-a-service platform for cloud-based clinical decision support service, Healthcare Inf. Res., 21 (2015), 102–110. https://doi.org/10.4258/hir.2015.21.2.102 doi: 10.4258/hir.2015.21.2.102
|
| [10] | N. Ujjwal, A. Singh, A. K. Jain, R. G. Tiwari, Exploiting machine learning for lumpy skin disease occurrence detection, in 10th International Conference on Reliability, Infocom Technologies and Optimization (Trends and Future Directions), (2022), 1–6. https://doi.org/10.1109/ICRITO56286.2022.9964656 |
| [11] | N. K. Krishna, R. M. Benjamin, N. Tejaswi, Machine learning diagnosis of lumpy skin disease in cattle herds, in Proceedings of the 3rd International Conference on Applied Artificial Intelligence and Computing, (2024), 426–431. https://doi.org/10.1109/ICAAIC60222.2024.10575895 |
| [12] |
G. Villa-Cox, H. van Loo, S. Speelman, S. Ribbens, J. Hooyberghs, B. Pardon, et al., Machine learning modeling to predict causes of infectious abortions and perinatal mortalities in cattle, Theriogenology, 226 (2024), 20–28. https://doi.org/10.1016/j.theriogenology.2024.05.041 doi: 10.1016/j.theriogenology.2024.05.041
|
| [13] |
A. A. Megahed, R. Bommineni, M. Short, K. N. Galvão, J. H. J. Bittar, Using supervised machine learning algorithms to predict bovine leukemia virus seropositivity in dairy cattle in Florida: A 10-year retrospective study, Preventative Vet. Med., 235 (2025), 106387. https://doi.org/10.1016/j.prevetmed.2024.106387 doi: 10.1016/j.prevetmed.2024.106387
|
| [14] |
S. Chae, S. Kwon, D. Lee, Predicting infectious disease using deep learning and big data, Int. J. Environ. Res. Public Health, 15 (2018), 1–19. https://doi.org/10.3390/ijerph15081596 doi: 10.3390/ijerph15081596
|
| [15] | S. Raschka, V. Mirjalili, Python Machine Learning, Second Edition, Packt Publishing Ltd, 2017. |
| [16] | M. O. Pulido-Medellín, D. J. García-Corredor, J. C. Vargas-Abella, Seroprevalencia de Neospora caninum en un Hato Lechero de Boyacá, Colombia, Rev. Inv. Vet. Perú, 27 (2016), 355–362. https://doi.org/10.15381/rivep.v27i2.11658 |
| [17] |
M. O. P. Medellín, A. D. Anaya, R. A. Becerra, Asociación entre variables reproductivas y anticuerpos anti Neospora caninum en bovinos lecheros de un municipio de Colombia, Rev Mex. Cienc. Pecu., 8 (2017), 167–174. https://doi.org/10.22319/rmcp.v8i2.4439 doi: 10.22319/rmcp.v8i2.4439
|
| [18] | S. M. Lundberg, S. I. Lee, A unified approach to interpreting model predictions, in Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS'17), (2017), 4768–4777. |
| [19] |
S. Ahmed, M. S. Kaiser, M. S. Hossain, K. Andersson, A comparative analysis of LIME and SHAP interpreters with explainable ML-based diabetes predictions, IEEE Access, 13 (2024), 37370–37388. https://doi.org/10.1109/ACCESS.2024.3422319 doi: 10.1109/ACCESS.2024.3422319
|
| [20] |
P. Yu, R. Gao, D. Zhang, Z. P. Liu, Predicting coastal algal blooms with environmental factors by machine learning methods, Ecol. Indic., 123 (2021), 107334. https://doi.org/10.1016/j.ecolind.2020.107334 doi: 10.1016/j.ecolind.2020.107334
|
| [21] | W. Zhang, T. Du, J. Wang, Deep learning over multi-field categorical data, in Advances in Information Retrieval (ECIR), (2016), 45–57. https://doi.org/10.1007/978-3-319-30671-1_4 |
| [22] |
B. Ivorra, D. Ngom, Á. M. Ramos, Be-CoDiS: A mathematical model to predict the risk of human diseases spread between countries—validation and application to the 2014–2015 Ebola virus disease epidemic, Bull. Math. Biol., 77 (2015), 1668–1704. https://doi.org/10.1007/s11538-015-0100-x doi: 10.1007/s11538-015-0100-x
|
| [23] | P. Nickerson, P. Tighe, B. Shickel, P. Rashidi, Deep neural network architectures for forecasting analgesic response, in Proceedings of the Annual International Conference of the IEEE Engineering in Medicine and Biology Society, EMBS, (2016), 2966–2969. https://doi.org/10.1109/EMBC.2016.7591352 |
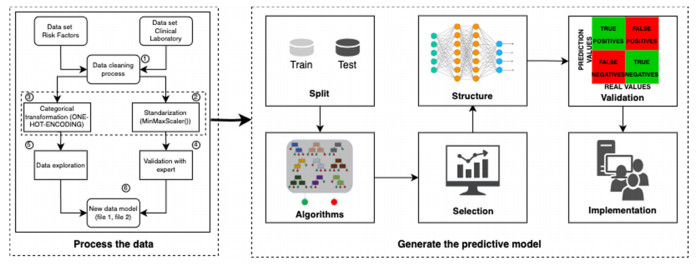
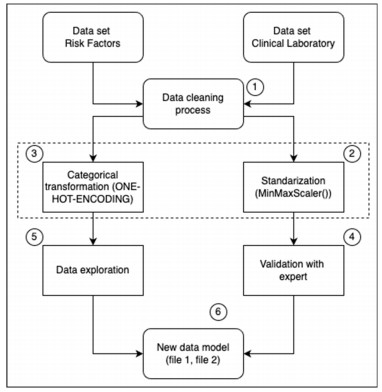
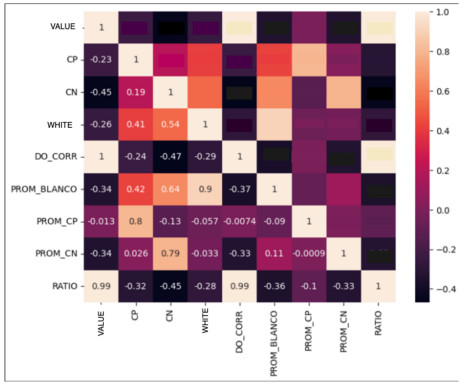
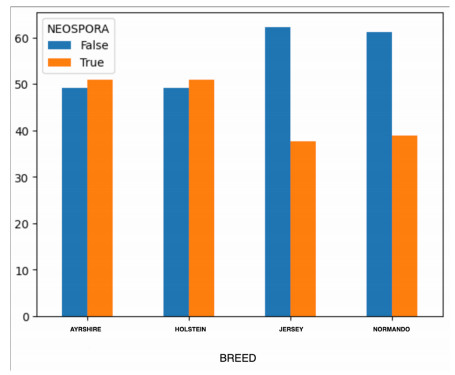
Figures(10) / Tables(7)

Javier Antonio Ballesteros-Ricaurte, Ramon Fabregat, Angela Carrillo-Ramos, Carlos Parra, Andrés Moreno. Artificial neural networks to predict the presence of Neosporosis in cattle[J]. Mathematical Biosciences and Engineering, 2025, 22(5): 1140-1158. doi: 10.3934/mbe.2025041







 DownLoad:
DownLoad: