In this paper, in order to realize the predefined-time control of $ n $-dimensional chaotic systems with disturbance and uncertainty, a disturbance observer and sliding mode control method were presented. A sliding manifold was designed for ensuring that when the error system runs on it, the tracking error was stable within a predefined time. A sliding mode controller was developed which enabled the dynamical system to reach the sliding surface within a predefined time. The total expected convergence time can be acquired through presetting two predefined-time parameters. The results demonstrated the feasibility of the proposed control method.
Citation: Yun Liu, Yuhong Huo. Predefined-time sliding mode control of chaotic systems based on disturbance observer[J]. Mathematical Biosciences and Engineering, 2024, 21(4): 5032-5046. doi: 10.3934/mbe.2024222
In this paper, in order to realize the predefined-time control of $ n $-dimensional chaotic systems with disturbance and uncertainty, a disturbance observer and sliding mode control method were presented. A sliding manifold was designed for ensuring that when the error system runs on it, the tracking error was stable within a predefined time. A sliding mode controller was developed which enabled the dynamical system to reach the sliding surface within a predefined time. The total expected convergence time can be acquired through presetting two predefined-time parameters. The results demonstrated the feasibility of the proposed control method.

| [1] |
M. C. Ho, Y. C. Hung, Z. Y. Liu, I. M. Jiang, Reduced-order synchronization of chaotic systems with parameters unknown, Phys. Lett. A, 348 (2006), 251–259. https://doi.org/10.1016/j.physleta.2005.08.076 doi: 10.1016/j.physleta.2005.08.076

|
| [2] |
L. M. Pecora, T. L. Carroll, Synchronization in chaotic systems, Phys. Rev. Lett., 64 (1990), 821. https://doi.org/10.1103/PhysRevLett.64.821 doi: 10.1103/PhysRevLett.64.821
|
| [3] |
S. Ha, L. Y. Chen, H. Liu, Command filtered adaptive neural network synchronization control of fractional-order chaotic systems subject to unknown dead zones, J. Franklin Inst., 358 (2021), 3376–3402. https://doi.org/10.1016/j.jfranklin.2021.02.012 doi: 10.1016/j.jfranklin.2021.02.012
|
| [4] |
H. Bao, Z. Y. Hua, N. Wang, L. Zhu, M. Chen, B. C. Bao, Initials-boosted coexisting chaos in a 2-d sine map and its hardware implementation, IEEE Trans. Ind. Inf., 17 (2020), 1132–1140. https://doi.org/10.1109/TII.2020.2992438 doi: 10.1109/TII.2020.2992438
|
| [5] |
A. Altan, S. Karasu, S. Bekiros, Digital currency forecasting with chaotic meta-heurist bio-inspired signal processing techniques, Chaos Solitons Fractals, 126 (2019), 325–336. https://doi.org/10.1016/j.chaos.2019.07.011 doi: 10.1016/j.chaos.2019.07.011
|
| [6] |
C. H. Lin, C. W. Ho, G. H. Hu, B. Sreeramaneni, J. J. Yan, Secure data transmission based on adaptive chattering-free sliding mode synchronization of unied chaotic systems, Mathematics, 21 (2021), 2658. https://doi.org/10.3390/math9212658 doi: 10.3390/math9212658
|
| [7] |
G. W. Xu, S. D. Zhao, Y. Cheng, Chaotic synchronization based on improved global nonlinear integral sliding mode control, Comput. Electr. Eng., 96 (2021), 107497. https://doi.org/10.1016/j.compeleceng.2021.107497 doi: 10.1016/j.compeleceng.2021.107497
|
| [8] |
A. Izadbakhsh, N. Nikdel, Chaos synchronization using differential equations as extended state observer, Chaos Solitons Fractals, 153 (2021), 111433. https://doi.org/10.1016/j.chaos.2021.111433 doi: 10.1016/j.chaos.2021.111433
|
| [9] |
N. Cai, W. Q. Li, Y. W. Jing, Finite-time generalized synchronization of chaotic systems with different order, Nonlinear Dyn., 64 (2011), 385–393. https://doi.org/10.1007/s11071-010-9869-1 doi: 10.1007/s11071-010-9869-1
|
| [10] |
X. Y. Chen, T. W. Huang, J. D. Cao, J. H. Park, J. L. Qiu, Finite-time multi-switching sliding mode synchronisation for multiple uncertain complex chaotic systems with net-work transmission mode, IET Control Theory Appl., 13 (2019), 1246–1257. http://dx.doi.org/10.1049/iet-cta.2018.5661 doi: 10.1049/iet-cta.2018.5661
|
| [11] |
W. G. Ao, T. D. Ma, R. V. Sanchez, H. T. Gan, Finite-time and fixed-time impulsive synchronization of chaotic systems, J. Franklin Inst., 357 (2020), 11545–11557. https://doi.org/10.1016/j.jfranklin.2019.07.023 doi: 10.1016/j.jfranklin.2019.07.023
|
| [12] |
D. Zhang, J. Mei, P. Miao, Global finite-time synchronization of different dimensional chaotic systems, Appl. Math. Modell., 48 (2017), 303–315. https://doi.org/10.1016/j.apm.2017.04.009 doi: 10.1016/j.apm.2017.04.009
|
| [13] |
Q. J. Yao, Synchronization of second-order chaotic systems with uncertainties and disturbances using fixed-time adaptive sliding mode control, Chaos Solitons Fractals, 142 (2021), 110372. https://doi.org/10.1016/j.chaos.2020.110372 doi: 10.1016/j.chaos.2020.110372
|
| [14] |
M. Dutta, B. K. Roy, A new memductance-based fractional-order chaotic system and its fixed-time synchronisation, Chaos Solitons Fractals, 145 (2021), 110782. https://doi.org/10.1016/j.chaos.2021.110782 doi: 10.1016/j.chaos.2021.110782
|
| [15] |
Y. M. Sun, F. Wang, Z. Liu, Y. Zhang, C. P. Chen, Fixed-time fuzzy control for a class of nonlinear systems, IEEE Trans. Cyber., 52 (2020), 3880–3887. https://doi.org/10.1109/TCYB.2020.3018695 doi: 10.1109/TCYB.2020.3018695
|
| [16] |
S. Z. Xie, Q. Chen, Adaptive nonsingular predfiened-time control for attitude stabilization of rigid spacecrafts, IEEE Trans. Circuits Syst. II Express Briefs, 69 (2021), 189–193. https://doi.org/10.1109/TCSII.2021.3078708 doi: 10.1109/TCSII.2021.3078708
|
| [17] |
Y. Sun, Y. Gao, Y. Zhao, Z. Liu, J. Wang, J. Kuang, et al., Neural network-based tracking control of uncertain robotic systems: Predefined-time nonsingular terminal sliding-mode approach, IEEE Trans. Ind. Electron., 69 (2020), 10510–10520. https://doi.org/10.1109/TIE.2022.3161810 doi: 10.1109/TIE.2022.3161810
|
| [18] |
Y. Wang, H. Y. Li, Y. Guan, M. S. Chen, Predefine-time chaos synchronization of memristor chaotic systems by using simplified control inputs, Chaos Solitons Fractals, 161 (2022), 112282. https://doi.org/10.1016/j.chaos.2022.112282 doi: 10.1016/j.chaos.2022.112282
|
| [19] |
E. A. Assali, Predefined-time synchronization of chaotic systems with different dimensions and applications, Chaos Solitons Fractals, 147 (2021), 110988. https://doi.org/10.1016/j.chaos.2021.110988 doi: 10.1016/j.chaos.2021.110988
|
| [20] |
E. R. Wang, S. H. Yan, Q. Y. Wang, A new four-dimensional chaotic system with multistability and its predefined-time synchronization, Int. J. Bifurcation Chaos, 32 (2022), 2250207. https://doi.org/10.1142/S0218127422502078 doi: 10.1142/S0218127422502078
|
| [21] |
H. B. Xue, X. H. Liu, A novel fast terminal sliding mode with predefined-time synchronization, Chaos Solitons Fractals, 175 (2023), 114049. https://doi.org/10.1016/j.chaos.2023.114049 doi: 10.1016/j.chaos.2023.114049
|
| [22] |
C. A. Anguiano-Gijón, A. J. Muñoz-Vázquez, J. D. Sánchez-Torres, G. Romero-Galván, F. Martínez-Reyes, On predefined-time synchronisation of chaotic systems, Chaos Solitons Fractals, 122 (2019), 172–178. https://doi.org/10.1016/j.chaos.2019.03.015 doi: 10.1016/j.chaos.2019.03.015
|
| [23] |
A. J. Muñoz-Vázquez, J. D. Sánchez-Torres, C. A. Anguiano-Gijón, Single-channel predefined-time synchronisation of chaotic systems, Asian J. Control, 23 (2021), 190–198. https://doi.org/10.1002/asjc.2234 doi: 10.1002/asjc.2234
|
| [24] |
M. J. Zhang, H. Y. Zang, L. Y. Bai, A new predefined-time sliding mode control scheme for synchronizing chaotic systems, Chaos Solitons Fractals, 14 (2022), 112745. https://doi.org/10.1016/j.chaos.2022.112745 doi: 10.1016/j.chaos.2022.112745
|
| [25] |
J. K. Ni, C. X. Liu, K. Liu, L. Liu, Finite-time sliding mode synchronization of chaotic systems, Chin. Phys. B, 23 (2014), 100504. https://doi.org/10.1088/1674-1056/23/10/100504 doi: 10.1088/1674-1056/23/10/100504
|
| [26] |
M. Shirkavand, M. Pourgholi, Robust fixed-time synchronization of fractional order chaotic using free chattering nonsingular adaptive fractional sliding mode controller design, Chaos Solitons Fractals, 113 (2018), 135–147. https://doi.org/10.1016/j.chaos.2018.05.020 doi: 10.1016/j.chaos.2018.05.020
|
| [27] |
Q. P. Li, C. Yue, Predefined-time polynomial-function-based synchronization of chaotic systems via a novel sliding mode control, IEEE Access, 8 (2020), 162149–162162. https://doi.org/10.1109/ACCESS.2020.3021094 doi: 10.1109/ACCESS.2020.3021094
|
| [28] |
P. Li, L. Di, B. Simone, Boundary-layer control with unstructured uncertainties with application to adaptive autopilots, IEEE Trans. Control Syst. Technol., 2023 (2023). https://doi.org/10.1109/TCST.2023.3329908 doi: 10.1109/TCST.2023.3329908
|
| [29] |
J. Zhao, Y. F. Lv, Output-feedback robust tracking control of uncertain systems via adaptive learning, Int. J. Control Autom. Syst., 21 (2023), 1108–1118. https://doi.org/10.1007/s12555-021-0882-6 doi: 10.1007/s12555-021-0882-6
|
| [30] |
Y. X. Wang, Heterogeneous network representation learning approach for ethereum identity identification, IEEE Trans. Comput. Soc. Syst., 10 (2022), 890–899. https://doi.org/10.1109/TCSS.2022.3164719 doi: 10.1109/TCSS.2022.3164719
|
| [31] |
W. Qi, S. E. Ovur, Z. Li, A. Marzullo, R. Song, Multi-sensor guided hand gesture recognition for a teleoperated robot using a recurrent neural network, IEEE Rob. Autom. Lett., 6 (2021), 6039–6045. https://doi.org/10.1109/LRA.2021.3089999 doi: 10.1109/LRA.2021.3089999
|
| [32] |
M. P. Aghababa, S. Khanmohammadi, G. Alizadeh, Finite-time synchronization of two different chaotic systems with unknown parameters via sliding mode technique, Appl. Math. Modell., 35 (2011), 3080–3091. https://doi.org/10.1016/j.apm.2010.12.020 doi: 10.1016/j.apm.2010.12.020
|
| [33] |
X. Z. Guo, G. G. Wen, Z. X. Peng, Y. L. Zhang, Global fixed-time synchronization of chaotic systems with different dimensions, J. Franklin Inst., 357 (2020), 1155–1173. https://doi.org/10.1016/j.jfranklin.2019.11.063 doi: 10.1016/j.jfranklin.2019.11.063
|
| [34] |
J. D. Sánchez-Torres, D. Gómez-Gutiérrez, E. López, A. G. Loukianov, A class of predefined-time stable dynamical systems, IMA J. Math. Control Inf., 35 (2018), 1–29. https://doi.org/10.1093/imamci/dnx004 doi: 10.1093/imamci/dnx004
|
| [35] |
A. J. Munoz-Vazquez, J. D. Sanchez-Torres, M. l. Defoort, S, Boulaaras, Predefined-time convergence in fractional-order systems, Chaos Solitons Fractals, 143 (2021), 110571. https://doi.org/10.1016/j.chaos.2020.110571 doi: 10.1016/j.chaos.2020.110571
|
| [36] |
Q. Wang, J. D. Cao, H. Liu, Adaptive fuzzy control of nonlinear systems with predefined time and accuracy, IEEE Trans. Fuzzy Syst., 30 (2022), 5152–5165. https://doi.org/10.1109/TFUZZ.2022.3169852 doi: 10.1109/TFUZZ.2022.3169852
|
| [37] |
S. Sahoo, B. K. Roy, Design of multi-wing chaotic systems with higher largest lyapunov exponent, Chaos Solitons Fractals, 157 (2022), 111926. https://doi.org/10.1016/j.chaos.2022.111926 doi: 10.1016/j.chaos.2022.111926
|
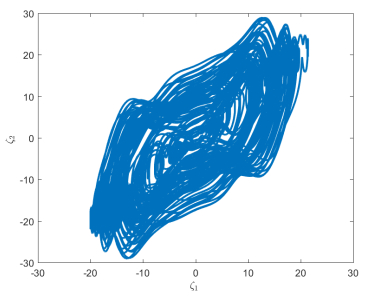
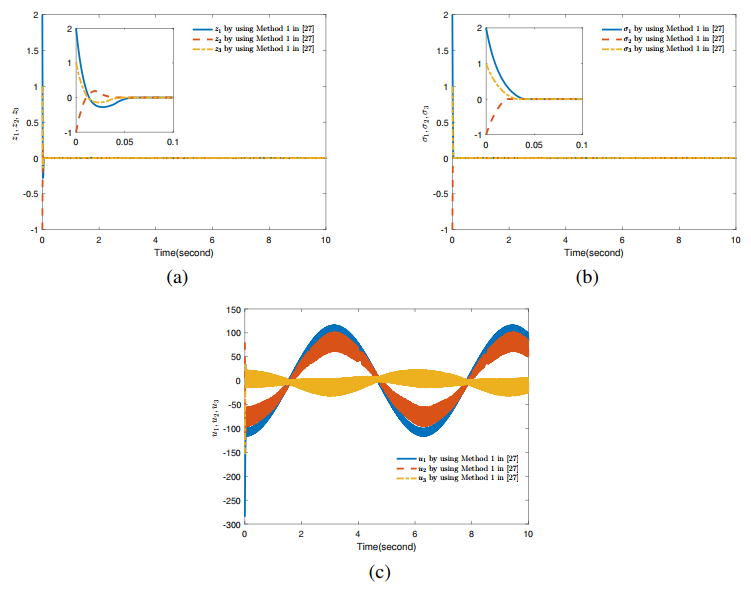
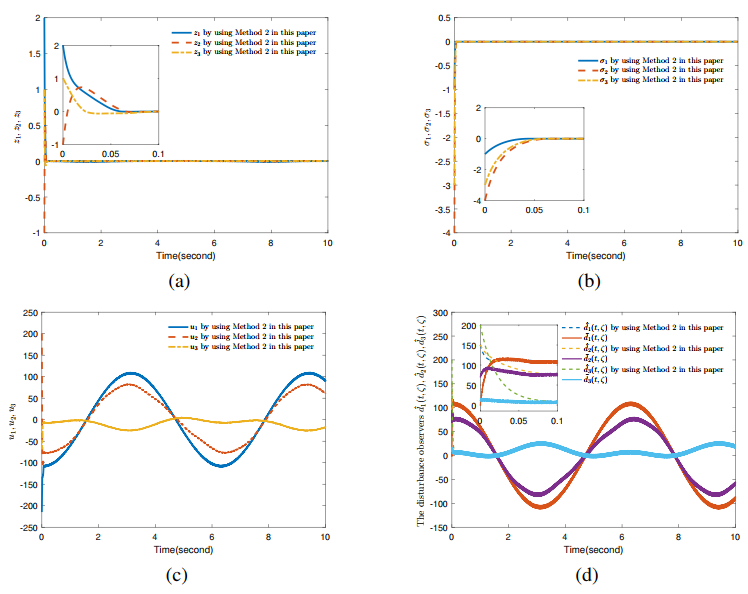
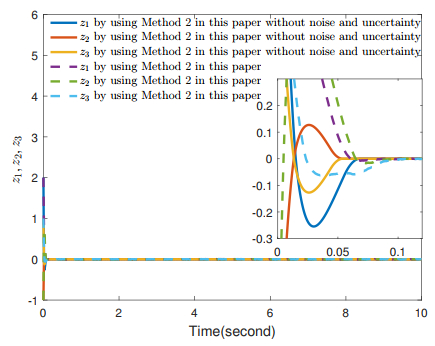
Figures(4)

Yun Liu, Yuhong Huo. Predefined-time sliding mode control of chaotic systems based on disturbance observer[J]. Mathematical Biosciences and Engineering, 2024, 21(4): 5032-5046. doi: 10.3934/mbe.2024222







 DownLoad:
DownLoad: