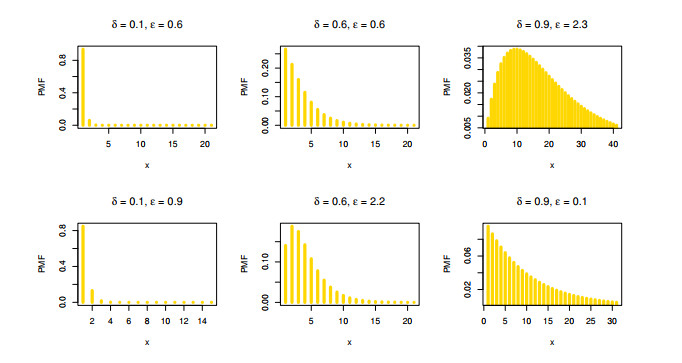
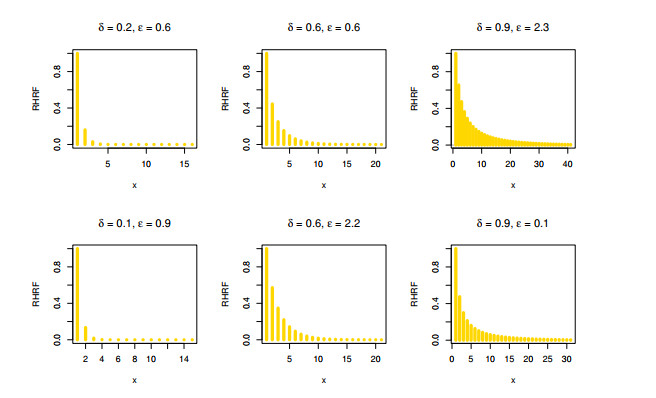
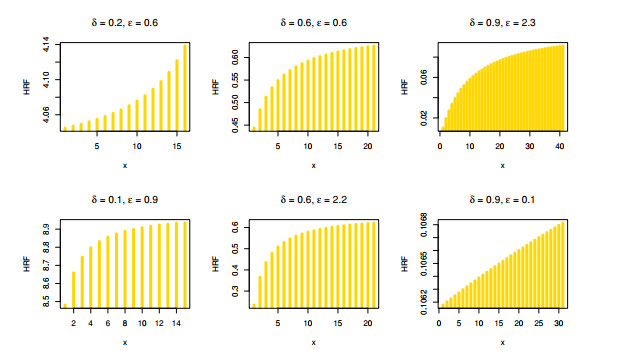
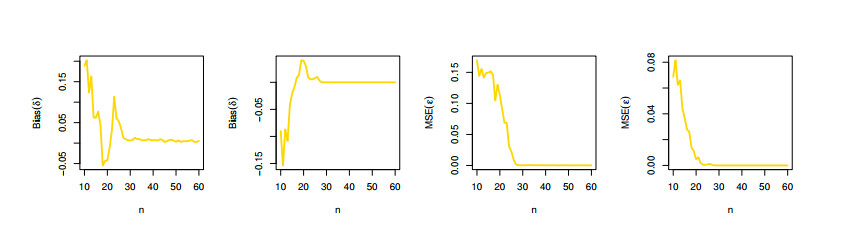
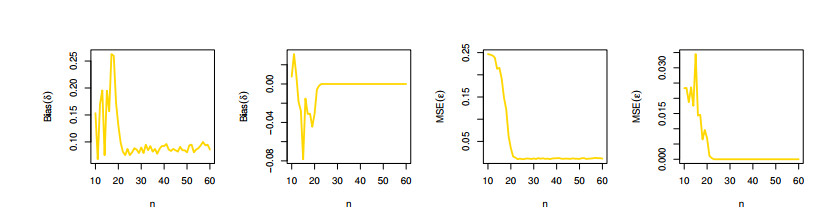
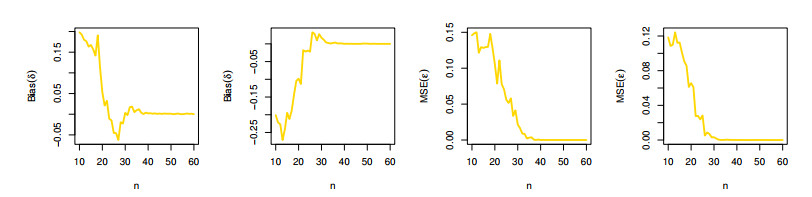
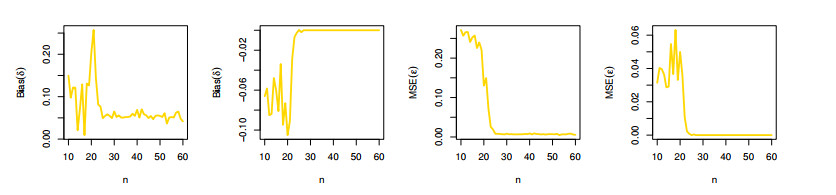
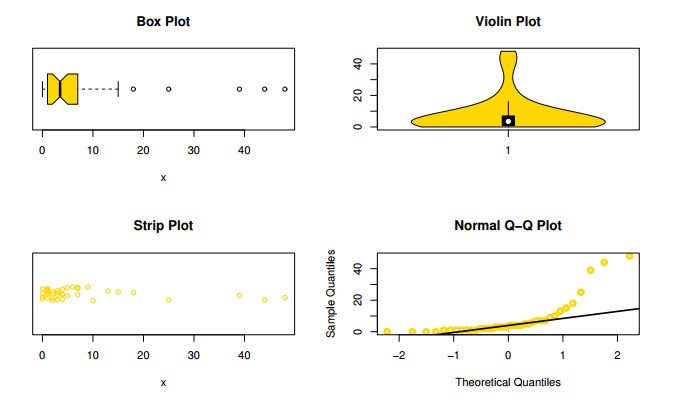
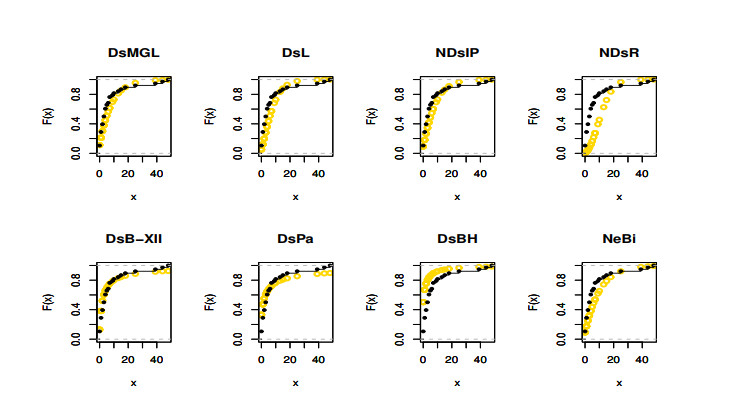
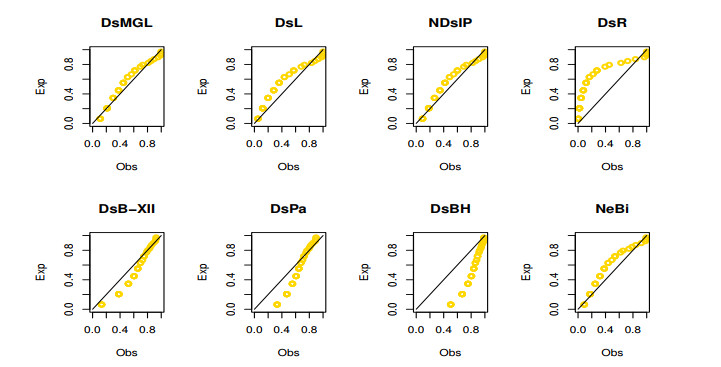
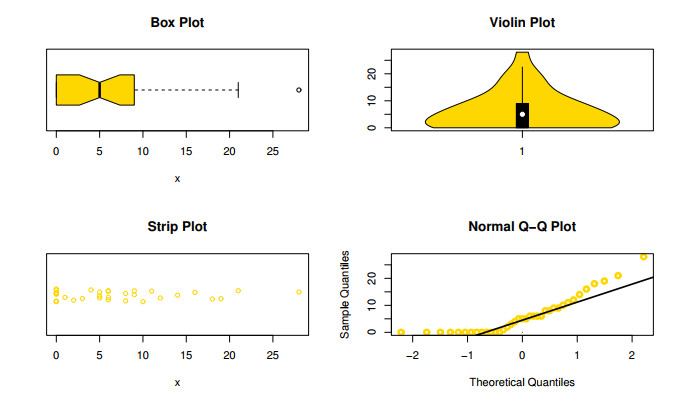
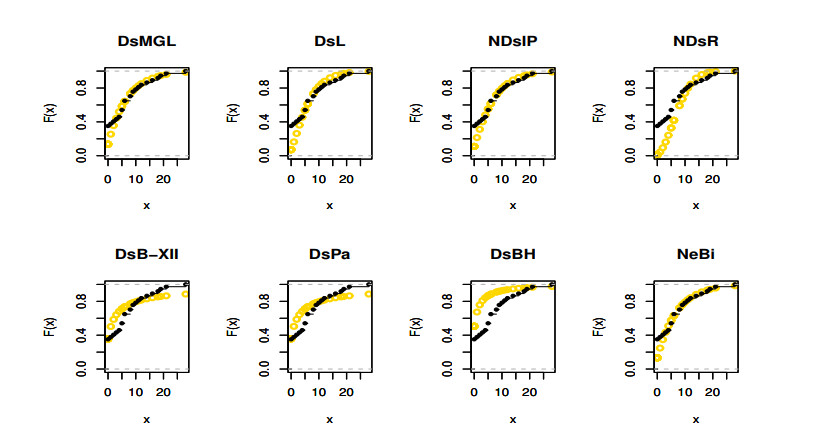
The aim of this paper is to introduce a discrete mixture model from the point of view of reliability and ordered statistics theoretically and practically for modeling extreme and outliers' observations. The base distribution can be expressed as a mixture of gamma and Lindley models. A wide range of the reported model structural properties are investigated. This includes the shape of the probability mass function, hazard rate function, reversed hazard rate function, min-max models, mean residual life, mean past life, moments, order statistics and L-moment statistics. These properties can be formulated as closed forms. It is found that the proposed model can be used effectively to evaluate over- and under-dispersed phenomena. Moreover, it can be applied to analyze asymmetric data under extreme and outliers' notes. To get the competent estimators for modeling observations, the maximum likelihood approach is utilized under conditions of the Newton-Raphson numerical technique. A simulation study is carried out to examine the bias and mean squared error of the estimators. Finally, the flexibility of the discrete mixture model is explained by discussing three COVID-19 data sets.
Citation: Mohamed S. Eliwa, Buthaynah T. Alhumaidan, Raghad N. Alqefari. A discrete mixed distribution: Statistical and reliability properties with applications to model COVID-19 data in various countries[J]. Mathematical Biosciences and Engineering, 2023, 20(5): 7859-7881. doi: 10.3934/mbe.2023340
The aim of this paper is to introduce a discrete mixture model from the point of view of reliability and ordered statistics theoretically and practically for modeling extreme and outliers' observations. The base distribution can be expressed as a mixture of gamma and Lindley models. A wide range of the reported model structural properties are investigated. This includes the shape of the probability mass function, hazard rate function, reversed hazard rate function, min-max models, mean residual life, mean past life, moments, order statistics and L-moment statistics. These properties can be formulated as closed forms. It is found that the proposed model can be used effectively to evaluate over- and under-dispersed phenomena. Moreover, it can be applied to analyze asymmetric data under extreme and outliers' notes. To get the competent estimators for modeling observations, the maximum likelihood approach is utilized under conditions of the Newton-Raphson numerical technique. A simulation study is carried out to examine the bias and mean squared error of the estimators. Finally, the flexibility of the discrete mixture model is explained by discussing three COVID-19 data sets.

| [1] |
A. El-Gohary, A. Alshamrani, A. N. Al-Otaibi, The generalized Gompertz distribution, Appl. Math. Model., 37 (2013), 13–24. https://doi.org/10.1016/j.apm.2011.05.017 doi: 10.1016/j.apm.2011.05.017

|
| [2] |
A. Saboor, H. S. Bakouch, M. N. Khan, Beta sarhan–zaindin modified Weibull distribution, Appl. Math. Model., 40 (2016), 6604–6621. https://doi.org/10.1016/j.apm.2016.01.033 doi: 10.1016/j.apm.2016.01.033
|
| [3] |
X. Jia, S. Nadarajah, B. Guo. Bayes estimation of P (Y $ < $ X) for the Weibull distribution with arbitrary parameters, Appl. Math. Model., 47 (2017), 249–259. https://doi.org/10.1016/j.apm.2017.03.020 doi: 10.1016/j.apm.2017.03.020
|
| [4] |
A. J. Fernández, Optimal lot disposition from Poisson–Lindley count data, Appl. Math. Model., 70 (2019), 595–604. https://doi.org/10.1016/j.apm.2019.01.045 doi: 10.1016/j.apm.2019.01.045
|
| [5] |
M. Alizadeh, A. Z. Afify, M. S. Eliwa, S. Ali, The odd log-logistic Lindley-G family of distributions: Properties, Bayesian and non-Bayesian estimation with applications, Comput. Stat., 35 (2020), 281–308. https://doi.org/10.1007/s00180-019-00932-9 doi: 10.1007/s00180-019-00932-9
|
| [6] |
S. Kumar, A. S. Yadav, S. Dey, M. Saha, Parametric inference of generalized process capability index Cpyk for the power Lindley distribution, Qual. Technol. Quant. Manage., 19 (2022), 153–186. https://doi.org/10.1080/16843703.2021.1944966 doi: 10.1080/16843703.2021.1944966
|
| [7] |
S. Nedjar, H. Zeghdoudi, On gamma Lindley distribution: Properties and simulations, J. Comput. Appl. Math., 15 (2016), 167–174. https://doi.org/10.1016/j.cam.2015.11.047 doi: 10.1016/j.cam.2015.11.047
|
| [8] | H. Messaadia, H. Zeghdoudi, Around gamma Lindley distribution, J. Mod. Appl. Stat. Methods., 16 (2017), 23. |
| [9] |
D. Roy, The discrete normal distribution, Commun. Stat. Theory Methods, 32 (2003), 1871–1883. https://doi.org/10.1081/STA-120023256 doi: 10.1081/STA-120023256
|
| [10] |
E. Gómez-Déniz, E. Calderín-Ojeda, The discrete Lindley distribution: Properties and applications, J. Stat. Comput. Simul., 81 (2011), 1405–1416. https://doi.org/10.1080/00949655.2010.487825 doi: 10.1080/00949655.2010.487825
|
| [11] |
M. Bebbington, C. D. Lai, M. Wellington, R. Zitikis, The discrete additive Weibull distribution: A bathtub-shaped hazard for discontinuous failure data, Reliab. Eng. Syst. Saf., 106 (2012), 37–44. https://doi.org/10.1016/j.ress.2012.06.009 doi: 10.1016/j.ress.2012.06.009
|
| [12] |
V. Nekoukhou, M. H. Alamatsaz, H. Bidram, Discrete generalized exponential distribution of a second type, Statistics, 47 (2013), 876–887. https://doi.org/10.1080/02331888.2011.633707 doi: 10.1080/02331888.2011.633707
|
| [13] | M. H. Alamatsaz, S. Dey, T. Dey, S. S. Harandi, Discrete generalized Rayleigh distribution, Pak. J. Stat., 32 (2016). |
| [14] |
M. El-Morshedy, M. S. Eliwa, H. Nagy, A new two-parameter exponentiated discrete Lindley distribution: Properties, estimation and applications, J. Appl. Stat., 47 (2020), 354–375. https://doi.org/10.1080/02664763.2019.1638893 doi: 10.1080/02664763.2019.1638893
|
| [15] |
J. Gillariose, O. S. Balogun, E. M. Almetwally, R. A. Sherwani, F. Jamal, J. Joseph, On the discrete Weibull Marshall–Olkin family of distributions: Properties, characterizations, and applications, Axioms, 10 (2021), 287. https://doi.org/10.3390/axioms10040287 doi: 10.3390/axioms10040287
|
| [16] |
B. Singh, R. P. Singh, A. S. Nayal, A. Tyagi, Discrete inverted Nadarajah-Haghighi distribution: Properties and classical estimation with application to complete and censored data, Stat. Optim. Inform. Comput., 10 (2022), 1293–1313. https://doi.org/10.19139/soic-2310-5070-1365 doi: 10.19139/soic-2310-5070-1365
|
| [17] |
B. Singh, V. Agiwal, A. S. Nayal, A. Tyagi, A discrete analogue of Teissier distribution: Properties and classical estimation with application to count data, Relia. Theory Appl., 17 (2022), 340–355. https://doi.org/10.24412/1932-2321-2022-167-340-355 doi: 10.24412/1932-2321-2022-167-340-355
|
| [18] |
M. S. Eliwa, M. El-Morshedy, A one-parameter discrete distribution for over-dispersed data: Statistical and reliability properties with applications, J. Appl. Stat., 49 (2022), 2467–2487. https://doi.org/10.1080/02664763.2021.1905787 doi: 10.1080/02664763.2021.1905787
|
| [19] |
E. Altun, M. El-Morshedy, M. S. Eliwa, A study on discrete Bilal distribution with properties and applications on integervalued autoregressive process, Stat. J., 20 (2022), 501–528. https://doi.org/10.57805/revstat.v20i4.384 doi: 10.57805/revstat.v20i4.384
|
| [20] | M. El-Morshedy, E. Altun, M. S. Eliwa, A new statistical approach to model the counts of novel coronavirus cases, Math. Sci., (2021), 1–4. https://doi.org/10.1007/s40096-021-00390-9 |
| [21] |
J. R. Hosking, L-moments: Analysis and estimation of distributions using linear combinations of order statistics, J. Royal Stat. Soc. Series B, 52 (1990), 105–124. https://doi.org/10.1111/j.2517-6161.1990.tb01775.x doi: 10.1111/j.2517-6161.1990.tb01775.x
|
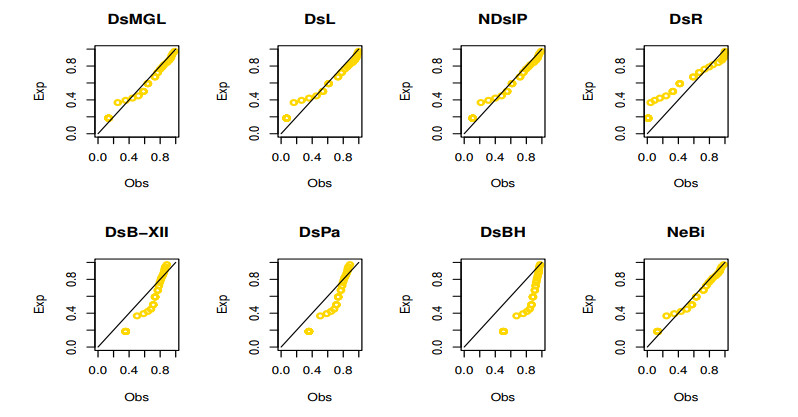
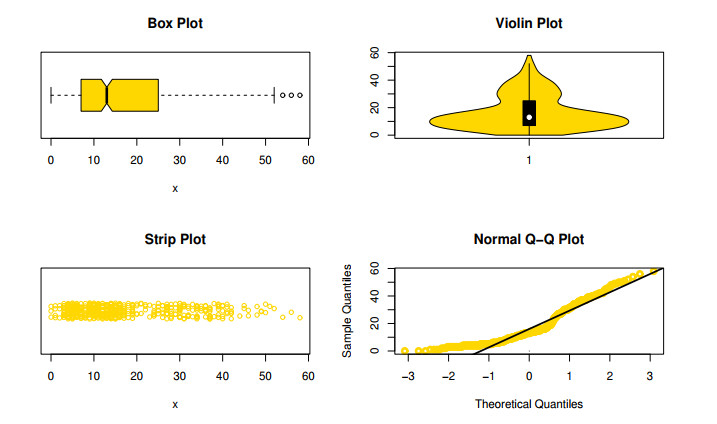
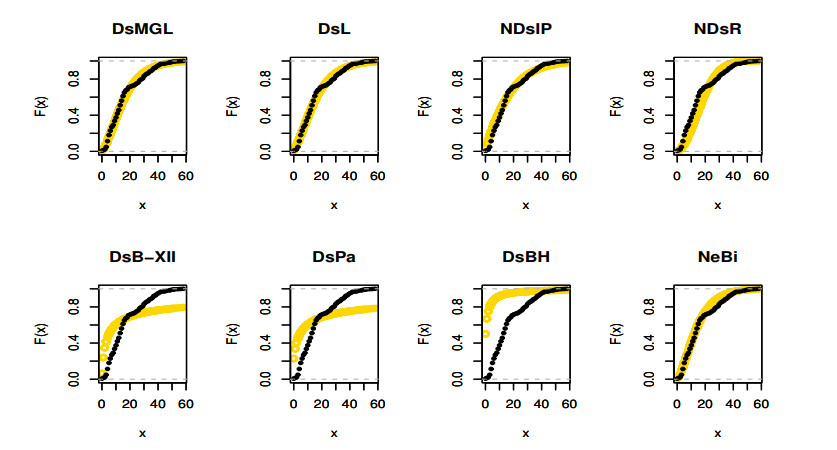
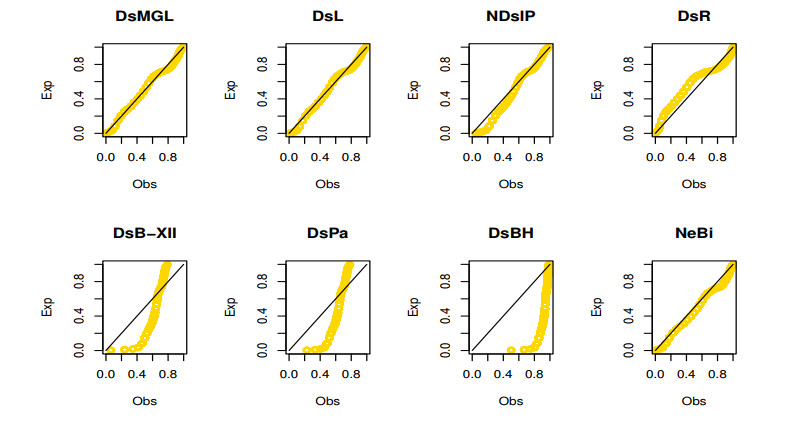
Figures(16) / Tables(12)

Mohamed S. Eliwa, Buthaynah T. Alhumaidan, Raghad N. Alqefari. A discrete mixed distribution: Statistical and reliability properties with applications to model COVID-19 data in various countries[J]. Mathematical Biosciences and Engineering, 2023, 20(5): 7859-7881. doi: 10.3934/mbe.2023340







 DownLoad:
DownLoad: