Citation: Lingyun Xiang, Guoqing Guo, Jingming Yu, Victor S. Sheng, Peng Yang. A convolutional neural network-based linguistic steganalysis for synonym substitution steganography[J]. Mathematical Biosciences and Engineering, 2020, 17(2): 1041-1058. doi: 10.3934/mbe.2020055

| [1] | Y. L. Liu, H. Peng and J. Wang, Verifiable diversity ranking search over encrypted outsourced data, CMC-Comput. Mater. Con., 55 (2018), 37-57. |
| [2] | L. Y. Xiang, Y. Li, W. Hao, et al., Reversible natural language watermarking using synonym substitution and arithmetic coding, CMC-Comput. Mater. Con., 55 (2018), 541-559. |
| [3] | H. M. Meral, B. Sankur, A. S. Ozsoy, et al., Natural language watermarking via morphosyntactic alterations, Comput. Speech Lang., 23 (2009), 107-125. |
| [4] | C. M. Taskiran, M. Topkara and E. J. Delp, Attacks on lexical natural language steganography systems, Proceed. SPIE, 6072 (2006), 607209-607209-9. |
| [5] | Z. L. Chen, L. S. Huang, H. B. Miao, et al., Steganalysis against substitution-based linguistic steganography based on context clusters, Comput. Electr. Eng., 37 (2011), 1071-1081. |
| [6] | Z. L. Chen, L. S. Huang and W. Yang, Detection of substitution-based linguistic steganography by relative frequency analysis, Digit. Invest., 8 (2011), 68-77. |
| [7] | L. Y. Xiang, X. M. Sun, G. Luo, et al., Linguistic steganalysis using the features derived from synonym frequency, Multimed. Tools Appl., 71 (2014), 1893-1911. |
| [8] | L. Y. Xiang, J. M. Yu, C. F. Yang, et al., A word-embedding-based steganalysis method for linguistic steganography via synonym-substitution, IEEE Access, 6 (2018), 64131-64141. |
| [9] | Z. S. Yu, L. S. Huang, Z. L. Chen, et al., Steganalysis of synonym-substitution based natural language watermarking, Int. J. Mult. Ubiquit. Eng., 4 (2012), 21-34. |
| [10] | Z. S. Yu, L. S. Huang, Z. L. Chen, et al., Detection of synonym-substitution modified articles using context information, Second International Conference on Future Generation Communication and Networking, (2008), 134-139. |
| [11] | Y. T. Chen, J. Xiong, W. H. Xu, et al., A novel online incremental and decremental learning algorithm based on variable support vector machine, Cluster Comput., Available from: https://doi.org/10.1007/s10586-018-1772-4. |
| [12] | L. Y. Xiang, G. H. Zhao, Q. Li, et al., TUMK-ELM: A fast unsupervised heterogeneous data learning approach, IEEE Access, 6 (2018), 35305-35315. |
| [13] | I. A. Bolshakov, A method of linguistic steganography based on collocationally-verified synonymy, International Workshop on Information Hiding, (2004), 180-191. |
| [14] | C. Y. Chang and S. Clark, Practical linguistic steganography using contextual synonym substitution and a novel vertex coding method, Comput. Linguist., 40 (2014), 403-448. |
| [15] | X. Yang, F. Li and L. Y. Xiang, Synonym substitution-based steganographic algorithm with matrix coding, J. Chinese Comput. Syst., 36 (2015), 1296-1300. |
| [16] | H. H. Hu, X. Zuo, W. M. Zhang, et al., Adaptive text steganography by exploring statistical and linguistical distortion, IEEE Second International Conference on Data Science in Cyberspace, (2017), 145-150. |
| [17] |
O. Russakovsky, J. Deng, H. Su, et al., Imagenet large scale visual recognition challenge, Int. J. Comput. Vision, 115 (2015), 211-252. doi: 10.1007/s11263-015-0816-y

|
| [18] | L. Y. Xiang, X. B. Shen, J. H. Qin, et al., Discrete multi-graph hashing for large-scale visual search, Neural Process. Lett., 49 (2019), 1055-1069. |
| [19] | J. Wang, J. H. Qin, X. Y. Xiang, et al., CAPTCHA recognition based on deep convolutional neural network, Math. Biosci. Eng., 16 (2019), 5851-5861. |
| [20] | N. Kalchbrenner, E. Grefenstette and P. Blunsom, A convolutional neural network for modelling sentences, preprint, arXiv:1404.2188. |
| [21] |
D. J. Zeng, Y. Dai, F. Li, et al., Aspect based sentiment analysis by a linguistically regularized CNN with gated mechanism, J. Intell. Fuzzy Syst., 36 (2019), 3971-3980. doi: 10.3233/JIFS-169958
|
| [22] | R. H. Meng, S. G. Rice, J. Wang, et al., A fusion steganographic algorithm based on faster R-CNN, CMC-Comput. Mater. Con., 55 (2018), 001-016. |
| [23] | S. Q. Tan and B. Li, Stacked convolutional auto-encoders for steganalysis of digital images, Signal and Information Processing Association Summit and Conference, (2014), 1-4. |
| [24] | J. Q. Ni, J. Ye and Y. Yang, Deep learning hierarchical representations for image steganalysis, IEEE T. Inf. Foren. Sec., 12 (2017), 2545-2557. |
| [25] | Y. L. Qian, J. Dong, W. Wang, et al., Deep learning for steganalysis via convolutional neural networks, Proceed. SPIE, 9409 (2015), 94090J-94090J-10. |
| [26] | G. S. Xu, H. Z. Wu and Y. Q. Shi, Structural design of convolutional neural networks for steganalysis, IEEE Signal Proc. Let., 23 (2016), 708-712. |
| [27] | J. S. Zeng, S. Q. Tan, B. Li, et al., Large-scale jpeg image steganalysis using hybrid deep learning framework, IEEE T. Inf. Foren. Sec., 13 (2018), 1200-1214. |
| [28] | A. Krizhevsky, I. Sutskever and G. E. Hinton, Imagenet classification with deep convolutional neural networks, Proceedings of the 25th International Conference on Neural Information Processing Systems, 1 (2012), 1097-1105. |
| [29] | Y. Kim, Convolutional neural networks for sentence classification, Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, (2014), 1746-1751. |
| [30] | J. Turian, L. Ratinov and Y. Bengio, Word representations: A simple and general method for semisupervised learning, Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics, (2010), 384-394. |
| [31] | G. E. Hinton, Learning distributed representations of concepts, Proceedings of the Eighth Annual Conference of the Cognitive Science Society, 1 (1986), 12-23. |
| [32] | Y. Bengio, H. Schwenk, J. Sencal, et al., Neural probabilistic language models, J. Mach. Learn. Res., 3 (2003), 1137-1155. |
| [33] | F. Morin and Y. Bengio, Hierarchical probabilistic neural network language model, Proceedings of the 10th International Workshop on Artificial Intelligence and Statistics, (2005), 246-252. |
| [34] | R. Collobert and J. Weston, A unified architecture for natural language processing: Deep neural networks with multitask learning, Proceedings of the 25th International Conference on Machine Learning, (2008), 160-167. |
| [35] | T. Mikolov, I. Sutskever, K. Chen, et al., Distributed representations of words and phrases and their compositionality, International Conference on Neural Information Processing Systems, (2013), 3111-3119. |
| [36] | B. Shen, C. W. Forstall, A. Rocha, et al., Practical text phylogeny for real-world settings, IEEE Access, 6 (2018), 41002-41012. |
| [37] | D. J. Zeng, Y. Dai, F. Li, et al., Adversarial learning for distant supervised relation extraction, CMC-Comput. Mater. Con., 55 (2018), 121-136. |
| [38] | R. Collobert, J. Weston, L. Bottou, et al., Natural language processing (almost) from scratch, J. Mach. Learn. Res., 12 (2011), 2493-2537. |
| [39] | Y. L. Boureau, N. L. Roux, F. Bach, et al., Ask the locals: Multi-way local pooling for image recognition, 2011 International Conference on Computer Vision, (2011), 2651-2658. |
| [40] | C. F. Yang, F. L. Liu, S. K. Ge, et al., Locating secret messages based on quantitative steganalysis, Math. Biosci. Eng., 16 (2019), 4908-4922. |
| [41] | C. F. Yang, X. Y. Luo, J. C. Lu, et al., Extracting hidden messages of MLSB steganography based on optimal stego subset, Sci. China Inform. Sci., 61 (2018), 119103:1-119103:3. |
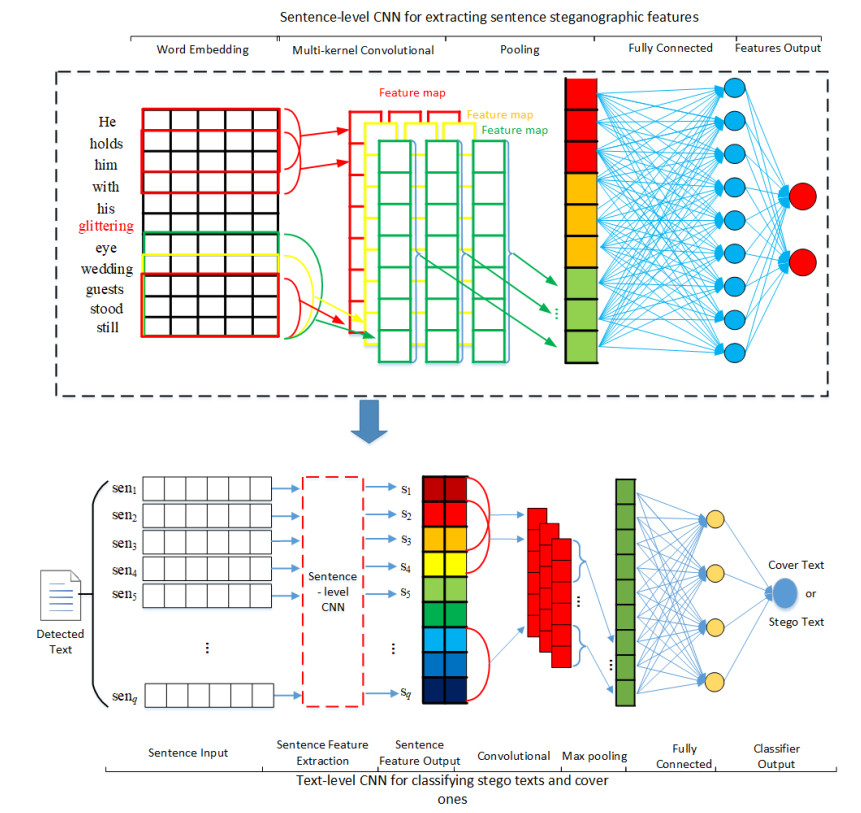
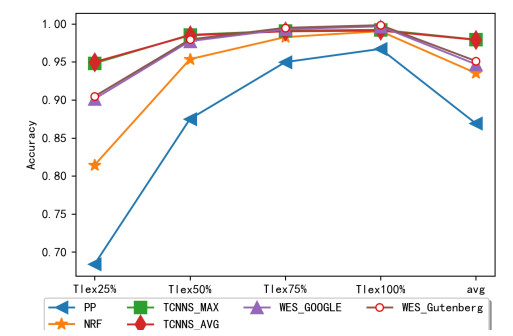
Figures(2) / Tables(3)

Lingyun Xiang, Guoqing Guo, Jingming Yu, Victor S. Sheng, Peng Yang. A convolutional neural network-based linguistic steganalysis for synonym substitution steganography[J]. Mathematical Biosciences and Engineering, 2020, 17(2): 1041-1058. doi: 10.3934/mbe.2020055







 DownLoad:
DownLoad: