Citation: Jiang Xie, Junfu Xu, Celine Nie, Qing Nie. Machine learning of swimming data via wisdom of crowd and regression analysis[J]. Mathematical Biosciences and Engineering, 2017, 14(2): 511-527. doi: 10.3934/mbe.2017031

| [1] | [ M. Bächlin,G. Tröster, Swimming performance and technique evaluation with wearable acceleration sensors, Pervasive and Mobile Computing, 8 (2012): 68-81. |
| [2] | [ R. C. Barros,M. P. Basgalupp,A. C. De Carvalho,A. Freitas, A survey of evolutionary algorithms for decision-tree induction, Systems, Man, and Cybernetics, Part C: Applications and Reviews, IEEE Transactions on, 42 (2012): 291-312. |
| [3] | [ D. Basak,S. Pal,D. C. Patranabis, Support vector regression, Neural Information Processing-Letters and Reviews, 11 (2007): 203-224. |
| [4] | [ C. Cai,G. Wang,Y. Wen,J. Pei,X. Zhu,W. Zhuang, Superconducting transition temperature t c estimation for superconductors of the doped mgb2 system using topological index via support vector regression, Journal of Superconductivity and Novel Magnetism, 23 (2010): 745-748. |
| [5] | [ D. Cai, X. He and J. Han, Semi-supervised discriminant analysis, in Computer Vision, 2007. ICCV 2007. IEEE 11th International Conference on, IEEE, 2007, 1-7. |
| [6] | [ J. Cao,S. Kwong,R. Wang, A noise-detection based adaboost algorithm for mislabeled data, Pattern Recognition, 45 (2012): 4451-4465. |
| [7] | [ J. J. Cheh,R. S. Weinberg,K. C. Yook, An application of an artificial neural network investment system to predict takeover targets, Journal of Applied Business Research (JABR), 15 (2013): 33-46. |
| [8] | [ J. L. Dye,V. A. Nicely, A general purpose curve fitting program for class and research use, Journal of chemical Education, 48 (1971): 443. |
| [9] | [ M. A. Friedl,C. E. Brodley, Decision tree classification of land cover from remotely sensed data, Remote Sensing of Environment, 61 (1997): 399-409. |
| [10] | [ K. Fukunaga,P. M. Narendra, A branch and bound algorithm for computing k-nearest neighbors, Computers, IEEE Transactions on, 100 (1975): 750-753. |
| [11] | [ A. Garg and K. Tai, Comparison of regression analysis, artificial neural network and genetic programming in handling the multicollinearity problem, in Modelling, Identification & Control (ICMIC), 2012 Proceedings of International Conference on, IEEE, 2012,353-358. |
| [12] | [ Z. Guo,W. Zhao,H. Lu,J. Wang, Multi-step forecasting for wind speed using a modified emd-based artificial neural network model, Renewable Energy, 37 (2012): 241-249. |
| [13] | [ I. Hmeidi,B. Hawashin,E. El-Qawasmeh, Performance of knn and svm classifiers on full word arabic articles, Advanced Engineering Informatics, 22 (2008): 106-111. |
| [14] | [ Y. Jiang, J. Lin, B. Cukic and T. Menzies, Variance analysis in software fault prediction models, in Software Reliability Engineering, 2009. ISSRE'09. 20th International Symposium on, IEEE, 2009, 99-108. |
| [15] | [ A. Liaw,M. Wiener, Classification and regression by randomforest, R news, 2 (2002): 18-22. |
| [16] | [ B. Liu and G. Qiu, Illuminant classification based on random forest, in Machine Vision Applications (MVA), 2015 14th IAPR International Conference on, IEEE, 2015,106-109. |
| [17] | [ D. Marbach,R. J. Prill,T. Schaffter,C. Mattiussi,D. Floreano,G. Stolovitzky, Revealing strengths and weaknesses of methods for gene network inference, Proceedings of the National Academy of Sciences, 107 (2010): 6286-6291. |
| [18] | [ F. Pedregosa,G. Varoquaux,A. Gramfort,V. Michel,B. Thirion,O. Grisel,M. Blondel,P. Prettenhofer,R. Weiss,V. Dubourg,J. Vanderplas,A. Passos,D. Cournapeau,M. Brucher,M. Perrot,E. Duchesnay, Scikit-learn: Machine learning in Python, Journal of Machine Learning Research, 12 (2011): 2825-2830. |
| [19] | [ M.-T. Puth,M. Neuhäuser,G. D. Ruxton, Effective use of pearson's product--moment correlation coefficient, Animal Behaviour, 93 (2014): 183-189. |
| [20] | [ G. Rätsch,T. Onoda,K.-R. Müller, Soft margins for adaboost, Machine Learning, 42 (2001): 287-320. |
| [21] | [ J. F. Reis,F. B. Alves,P. M. Bruno,V. Vleck,G. P. Millet, Oxygen uptake kinetics and middle distance swimming performance, Journal of Science and Medicine in Sport, 15 (2012): 58-63. |
| [22] | [ B. Scholkopft,K.-R. Mullert, Fisher discriminant analysis with kernels, Neural Networks for Signal Processing Ⅸ, 1 (1999): p1. |
| [23] | [ C. Schüldt, I. Laptev and B. Caputo, Recognizing human actions: A local svm approach, in Pattern Recognition, 2004. ICPR 2004. Proceedings of the 17th International Conference on, IEEE, 3 (2004), 32-36. |
| [24] | [ A. J. Smola,B. Schölkopf, A tutorial on support vector regression, Statistics and Computing, 14 (2004): 199-222. |
| [25] | [ M. Vaso,B. Knechtle,C. A. Rüst,T. Rosemann,R. Lepers, Age of peak swim speed and sex difference in performance in medley and freestyle swimming. a comparison between 200 m and 400 m in swiss elite swimmers, Journal of Human Sport and Exercise, 8 (2013): 954-965. |
| [26] | [ Q. Wang,G. M. Garrity,J. M. Tiedje,J. R. Cole, Naive bayesian classifier for rapid assignment of rrna sequences into the new bacterial taxonomy, Applied and Environmental Microbiology, 73 (2007): 5261-5267. |
| [27] | [ S.-C. Wang, Artificial neural network, in Interdisciplinary Computing in Java Programming, Springer, 2003, 81-100. |
| [28] | [ C.-H. Wu,J.-M. Ho,D.-T. Lee, Travel-time prediction with support vector regression, Intelligent Transportation Systems, IEEE Transactions on, 5 (2004): 276-281. |
| [29] | [ J. Wu, Z. Cai, S. Zeng and X. Zhu, Artificial immune system for attribute weighted naive bayes classification, in Neural Networks (IJCNN), The 2013 International Joint Conference on, IEEE, 2013, 1-8. |
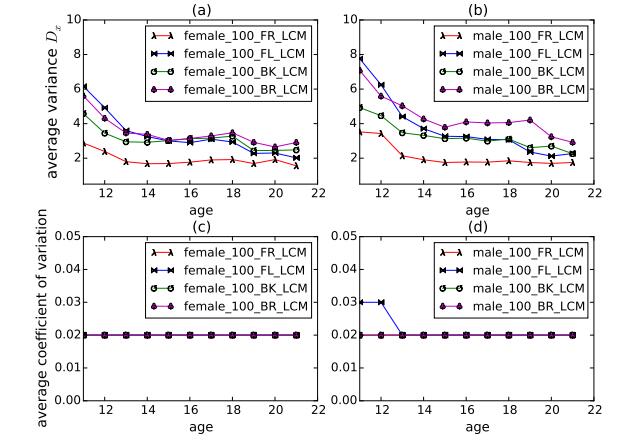
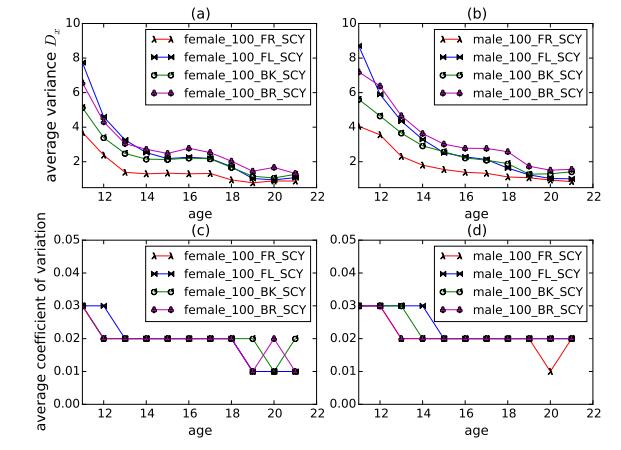
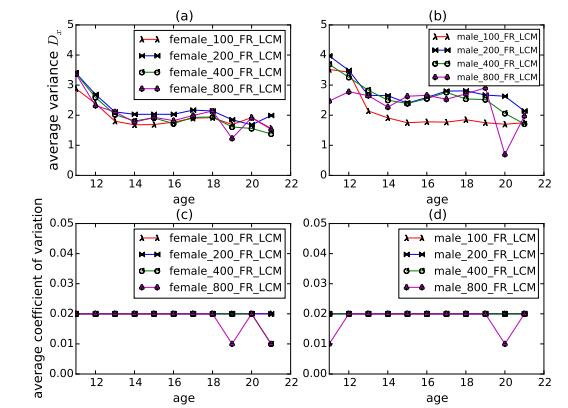
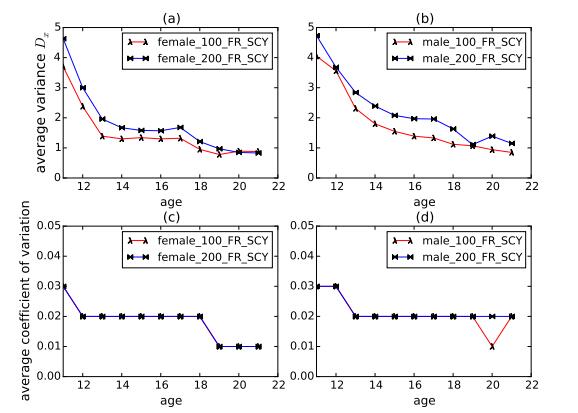

Figures(10) / Tables(8)

Jiang Xie, Junfu Xu, Celine Nie, Qing Nie. Machine learning of swimming data via wisdom of crowd and regression analysis[J]. Mathematical Biosciences and Engineering, 2017, 14(2): 511-527. doi: 10.3934/mbe.2017031







 DownLoad:
DownLoad: