The present paper intensively studies various properties of certain topologies on the set of integers $ {\mathbb Z} $ (resp. $ {\mathbb Z}^n $) which are either homeomorphic or not homeomorphic to the typical Khalimsky line topology (resp. $ n $-dimensional Khalimsky topology). This finding plays a crucial role in addressing some problems which remain open in the field of digital topology.
Citation: Sang-Eon Han, Saeid Jafari, Jeong Min Kang, Sik Lee. Remarks on topological spaces on $ {\mathbb Z}^n $ which are related to the Khalimsky $ n $-dimensional space[J]. AIMS Mathematics, 2022, 7(1): 1224-1240. doi: 10.3934/math.2022072
The present paper intensively studies various properties of certain topologies on the set of integers $ {\mathbb Z} $ (resp. $ {\mathbb Z}^n $) which are either homeomorphic or not homeomorphic to the typical Khalimsky line topology (resp. $ n $-dimensional Khalimsky topology). This finding plays a crucial role in addressing some problems which remain open in the field of digital topology.

| [1] |
P. S. Alexandorff, Uber die Metrisation der im Kleinen kompakten topologischen R$\ddot{a}$ume, Math. Ann., 92 (1924), 294–301. doi: 10.1007/BF01448011. doi: 10.1007/BF01448011

|
| [2] | P. Alexandorff, Diskrete R$\ddot{a}$ume, Mat. Sb., 2 (1937), 501–518. |
| [3] | V. A. Chatyrko, S. E. Han, Y. Hattori, Some remarks concerning semi-$T_{\frac{1}{2}}$ spaces, Filomat, 28 (2014), 21–25. |
| [4] | W. Dunham, $T_{\frac{1}{2}}$-spaces, Kyungpook Math. J., 17 (1977), 161–169. |
| [5] |
S. E. Han, Covering rough set structures for a locally finite covering approximation space, Inf. Sci., 480 (2019), 420–437. doi: 10.1016/j.ins.2018.12.049. doi: 10.1016/j.ins.2018.12.049
|
| [6] |
S. E. Han, Roughness measures of locally finite covering rough sets, Int. J. Approx. Reason., 105 (2019), 368–385. doi: 10.1016/j.ijar.2018.12.003. doi: 10.1016/j.ijar.2018.12.003
|
| [7] | S. E. Han, Digital topological rough set structures and topological operators, Topol. Appl., 301 (2021), 107507, 1–19. doi: 10.1016/j.topol.2020.107507. |
| [8] |
S. E. Han, S. Jafari, J. M. Kang, Topologies on ${\mathbb Z}^n$ that are not homeomorphic to the $n$-dimensional Khalimsky topological space, Mathematics, 7 (2019), 1072. doi: 10.3390/math711072. doi: 10.3390/math711072
|
| [9] |
S. E. Han, A. Sostak, A compression of digital images derived from a Khalimsky topological structure, Comput. Appl. Math., 32 (2013), 521–536. doi: 10.1007/s40314-013-0034-6. doi: 10.1007/s40314-013-0034-6
|
| [10] |
J. M. Kang, S. E. Han, Compression of Khalimsky topological spaces, Filomat, 26 (2012), 1101–1114. doi: 10.2298/FIL1206101K. doi: 10.2298/FIL1206101K
|
| [11] | E. D. Khalimsky, Applications of connected ordered topological spaces in topology, Conf. Math. Dep. Povolosia, 1970. |
| [12] |
E. Khalimsky, R. Kopperman, P. R. Meyer, Computer graphics and connected topologies on finite ordered sets, Topol. Appl., 36 (1990), 1–17. doi: 10.1016/0166-8641(90)90031-V. doi: 10.1016/0166-8641(90)90031-V
|
| [13] | C. O. Kiselman, Digital Geometry and Mathematical Morphology, Lecture Notes, Uppsala University, Department of Mathematics, 2002. |
| [14] |
N. Levine, Semi-open sets and semi-continuity in topological spaces, Am. Math. Mon., 70 (1963), 36–41. doi: 10.2307/2312781. doi: 10.2307/2312781
|
| [15] |
J. J. Li, Topological properties of approximation spaces and their applications, Math. Pract. Theor., 39 (2009), 145–151. doi: 10.1360/972009-1650. doi: 10.1360/972009-1650
|
| [16] |
E. F. Lashin, A. M. Kozae, A. A. Abo Khadra, T. Medhat, Rough set theory for topolgoical spaces, Int. J. Approx. Reason., 40 (2005), 35–43. doi: 10.1016/j.ijar.2004.11.007. doi: 10.1016/j.ijar.2004.11.007
|
| [17] | J. R. Munkres, Topology: A First Course, Prentice-Hall Inc., 1975. doi: 10.2307/3615551. |
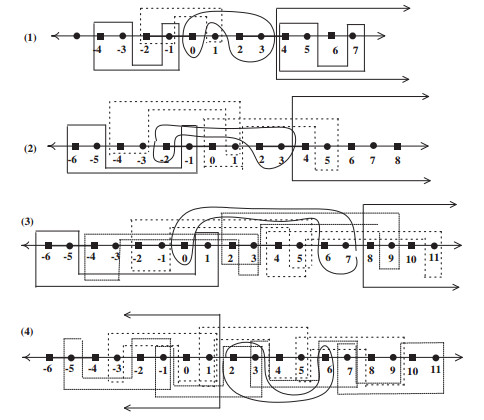
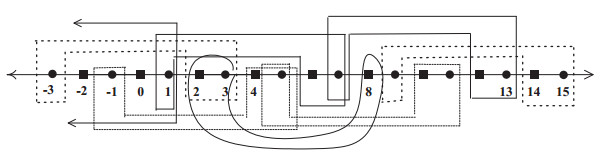
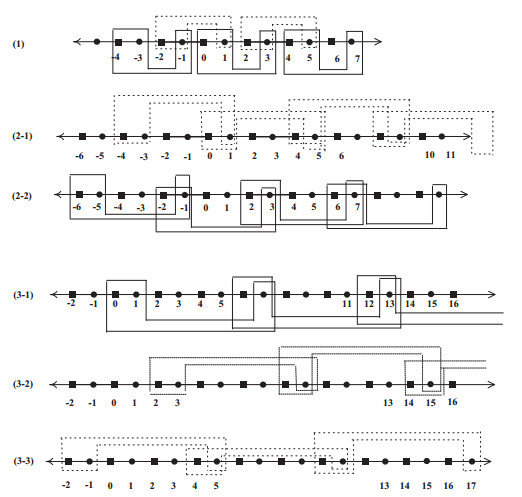
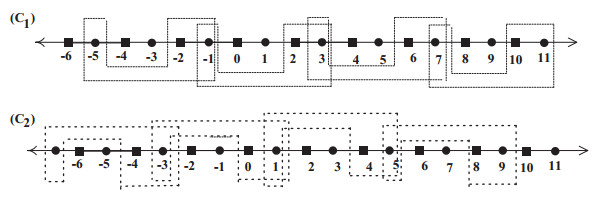
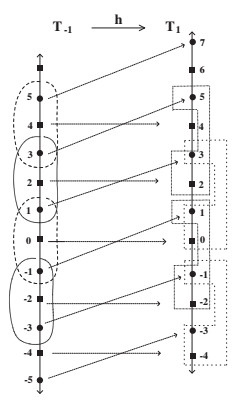
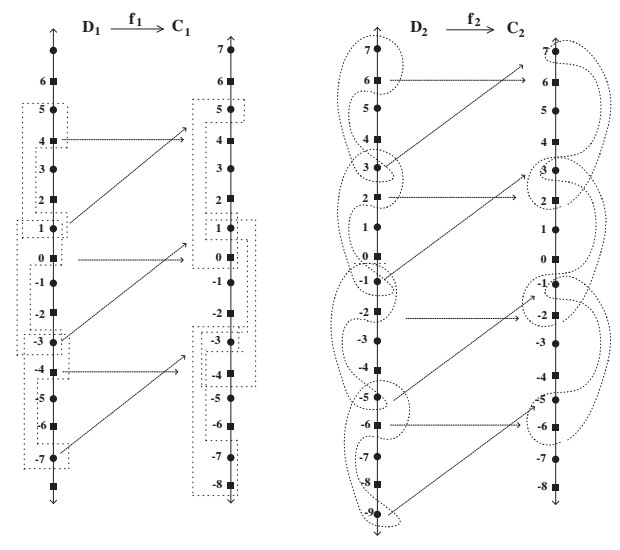
Figures(6)

Sang-Eon Han, Saeid Jafari, Jeong Min Kang, Sik Lee. Remarks on topological spaces on $ {\mathbb Z}^n $ which are related to the Khalimsky $ n $-dimensional space[J]. AIMS Mathematics, 2022, 7(1): 1224-1240. doi: 10.3934/math.2022072







 DownLoad:
DownLoad: