Citation: Sitalakshmi Venkatraman, Ramanathan Venkatraman. Big data security challenges and strategies[J]. AIMS Mathematics, 2019, 4(3): 860-879. doi: 10.3934/math.2019.3.860

| [1] |
M. Chen, S. Mao and Y. Liu, Big Data: A Survey, Mobile Netw. Appl., 19 (2014), 171-209. doi: 10.1007/s11036-013-0489-0

|
| [2] | W. Tian and Y. Zhao, Big data technologies and cloud computing, Optimized Cloud Resource Management and Scheduling Theory and Practice, (2015), 17-49. |
| [3] |
C. L. McNeely, J. Hahm, The big (data) bang: policy, prospects, and challenges, Review of Policy Research, 31 (2014), 304-310. doi: 10.1111/ropr.12082
|
| [4] |
A. Gandomi, M. Haider, Beyond the hype: Big data concepts, methods, and analytics, International Journal of Information Management, 35 (2015), 137-144. doi: 10.1016/j.ijinfomgt.2014.10.007
|
| [5] | D. Laney, 3D Data Management: Controlling Data Volume Velocity and Variety, META Group research note, 6 (2001), 1. |
| [6] |
J. Frizzo-Barker, P. A. Chow-White, M. Mozafari, et al. An empirical study of the rise of big data in business scholarship, International Journal of Information Management, 36 (2016), 403-413. doi: 10.1016/j.ijinfomgt.2016.01.006
|
| [7] | T. Huang, L. Lan, X. Fang, et al. Promises and challenges of big data computing in health sciences, Big Data Res., 2 (2015), 2-11. |
| [8] | B. Nelson, T. Olovsson, Security and privacy for big data: A systematic literature review. In: 2016 IEEE International Conference on Big Data (Big Data), (2016), 3693-3702 |
| [9] | M. Li-chuan, P. Qing-qi, L. Hao, et al. Survey of Security Issues in Big Data, Radio Communications Technology, 41 (2015), 1-7. |
| [10] | F. Deng-Guo, Z. Min, L. Hao, Big Data Security and Privacy Protection, Chinese Journal of Computers, 37 (2014), 246-258. |
| [11] | N. B. Kshetri, The emerging role of Big Data in key development issues: Opportunities, challenges, and concerns, Big Data & Society, 1 (2014), 1-20. |
| [12] |
X. Jin, B. Wah, X. Cheng, et al. Significance and challenges of big data research, Big Data Research, 2 (2015), 59-64. doi: 10.1016/j.bdr.2015.01.006
|
| [13] |
W. Xindong, Z. Xingquan, W. Gong-Qing, et al. Data Mining with Big Data, IEEE T. Knowl. Data En., 26 (2014), 97-107. doi: 10.1109/TKDE.2013.109
|
| [14] |
V. Chang and G. Wills, A model to compare cloud and non-cloud storage of Big Data, Future Gener. Comp. Sy., 57 (2016), 56-76. doi: 10.1016/j.future.2015.10.003
|
| [15] |
Z. Goli-Malekabadi, M. Sargolzaei-Javan, M. K. Akbari, An effective model for store and retrieve big health data in cloud computing, Comput. Meth. Prog. Bio., 132 (2016), 75-82. doi: 10.1016/j.cmpb.2016.04.016
|
| [16] | N. Kumar, A. V. Vasilakos, and J. Rodrigues, A multi-tenant cloud-based DC nano grid for self-sustained smart buildings in smart cities, IEEE Commun. Mag., 55 (2017), 14-21. |
| [17] |
S. Subashini and V. Kavitha, A survey on security issues in service delivery models of cloud computing, J. Netw. Comput. Appl., 34 (2011), 1-11. doi: 10.1016/j.jnca.2010.07.006
|
| [18] | H. Cheng, W. Wang, and C. Rong, Privacy protection beyond encryption for cloud big data. In: Proceedings of the 2nd International Conference on Information Technology and Electronic Commerce, (2014), 188-191, IEEE. |
| [19] | P. Jing, A new model of data protection on cloud storage, Journal of Networks, 9 (2014), 666-671. |
| [20] |
C. Liu, C. Yang, X. Zhang, et al. External integrity verification for outsourced big data in cloud and IoT: a big picture, Future Gener. Comp. Sy., 49 (2015), 58-67. doi: 10.1016/j.future.2014.08.007
|
| [21] | H. Kun, L. Di, L. Minghui, Research on Security Connotation and Response Strategies for Big Data, Telecommunications Science, 30 (2014), 112-117. |
| [22] |
T. Matzner, Why privacy is not enough privacy in the context of ubiquitous computing and big data, Journal of Information, Communication and Ethics in Society, 12 (2014), 93-106. doi: 10.1108/JICES-08-2013-0030
|
| [23] | D. Thilakanathan, Y. Zhao, S. Chen, et al. Protecting and Analysing Health Care Data on Cloud. In: Proceedings of the 2nd International Conference on Advanced Cloud and Big Data, (2014), 143-149, IEEE. |
| [24] |
I. de la Torre-Díez, B. Garcia-Zapirain, M. Lopez-Coronado, et al. Proposing telecardiology services on cloud for different medical institutions: a model of reference, Telemedicine and e-Health, 23 (2017), 654-661. doi: 10.1089/tmj.2016.0234
|
| [25] | G. Lafuente. The big data security challenge, Network Security, 2015 (2015), 12-14. |
| [26] | R. Lu, H. Zhu, X. Liu, et al. Toward efficient and privacy-preserving computing in big data era, Network IEEE, 28 (2014), 46-50. |
| [27] |
J. W. Crampton, Collect it all: national security, Big Data and governance, GeoJournal, 80 (2015), 519-531. doi: 10.1007/s10708-014-9598-y
|
| [28] | D. Lyon, Surveillance, snowden, and big data: Capacities, consequences, critique, Big Data & Society, 1 (2014), 1-13. |
| [29] |
X. Hu, M. Yuan, J. Yao, et al. Differential Privacy in Telco Big Data Platform, Proceedings of the VLDB Endowment, 8 (2015), 1692-1703. doi: 10.14778/2824032.2824067
|
| [30] | M. Benjamin, S. B. Michelle and T. B. Nadya, Eigenspace Analysis for Threat Detection in Social Networks. In: 14th International Conference on Information Fusion, (2011), 1-7, IEEE. |
| [31] |
A. Leman, T. Hanghang, K. Danai, Graph based anomaly detection and description: a survey, Data Min. Knowl. Disc., 29 (2015), 626-688. doi: 10.1007/s10618-014-0365-y
|
| [32] | C. Rebello, E. Tavares, Big Data Privacy Context: Literature Effects On Secure Informational Assets, Transactions on Data Privacy, 11 (2018), 199-217. |
| [33] | C. R. Silva, E. M. T. Rodrigues, Privacy In Big Data: Overview And Research Agenda, Sistemas & Gestao, 12 (2017), 491-505. |
| [34] | M. A. Khan, M. F. Uddin, N. Gupta, Seven V's of Big Data Understanding Big Data to extract Value. In: Proceedings of 2014 Zone 1 Conference of the American Society for Engineering Education, (2014), 1-5. |
| [35] | S. Hota, Big Data Analysis on YouTube Using Hadoop And Mapreduce, International Journal of Computer Engineering In Research Trends, 5 (2018), 98-104. |
| [36] | A. Patrizio, IDC: Expect 175 zettabytes of data worldwide by 2025, Network World, 2018. |
| [37] | K. D. Gronwald, Big Data Analytics. In: Integrated Business Information Systems A Holistic View of the Linked Business Process Chain ERP-SCM-CRM-BI-Big Data, (2017), 127-157. |
| [38] | E. Y. Gorodov and V. V. Gubarev, Analytical review of data visualization methods in application to big data, Journal of Electrical and Computer Engineering, 2013 (2013), 22. |
| [39] | G. B. Tarekegn, Y. Y. Munaye, Big Data: Security Issues, Challenges and Future Scope, International Journal of Computer Engineering & Technology, 7 (2016), 12-24. |
| [40] | F. Almeida, Big Data: Concept, Potentialities and Vulnerabilities, Emerging Science Journal, 2 (2018), 1-10. |
| [41] |
B. A. Kumar, S. Maninder, Data mining-based integrated network traffic visualization framework for threat detection, Neural Computing and Applications, 26 (2015), 117-130. doi: 10.1007/s00521-014-1701-2
|
| [42] |
Z. Yan, W. Ding, V. Niemi, et al. Two schemes of privacy-preserving trust evaluation, Future Gener. Comput. Sy., 62 (2016), 175-189. doi: 10.1016/j.future.2015.11.006
|
| [43] |
N. Rastogi, M. J. K. Gloria, J. Hendler, Security and Privacy of Performing Data Analytics in the Cloud, Journal of Information Policy, 5 (2015), 129-154. doi: 10.5325/jinfopoli.5.2015.0129
|
| [44] |
E. Bozdag, Bias in algorithmic filtering and personalization, Ethics and information technology, 15 (2013), 209-227. doi: 10.1007/s10676-013-9321-6
|
| [45] | H. Xiao, B. Biggio, G. Brown, et al. Is Feature Selection Secure against Training Data Poisoning? International Conference on Machine Learning, (2015), 1689-1698. |
| [46] | D. Puthal, S. Nepal, R. Ranjan, et al. A dynamic prime number based efficient security mechanism for big sensing data streams, J. Comput. Syst. Sci., 83 (2017), 22-42. |
| [47] |
Y. Zhe, M. Philip and R. Michael, Anomaly Detection Using Proximity Graph and PageRank Algorithm, IEEE T. Inf. Foren. Sec., 7 (2012), 1288-1300. doi: 10.1109/TIFS.2012.2191963
|
| [48] |
T. D. Huynh, M. Ebden, J. Fischer, et al. Provenance Network Analytics: An approach to data analytics using data provenance, Data Min. Knowl. Disc., 32 (2018), 708-735. doi: 10.1007/s10618-017-0549-3
|
| [49] |
G. Zhou, D. Zhang, Y. Liu, et al. A novel image encryption algorithm based on chaos and line map, Neurocomputing, 169 (2015), 150-157. doi: 10.1016/j.neucom.2014.11.095
|
| [50] |
Z. Wang, C. Cao, N. Yang, et al. ABE with improved auxiliary input for big data security, J. Comput. Syst. Sci., 89 (2017), 41-50. doi: 10.1016/j.jcss.2016.12.006
|
| [51] | C. Hsu, B. Zeng and M. Zhang, A novel group key transfer for big data security, Appl. Math. Comput., 249 (2014), 436-443. |
| [52] | D. L. G. Filho and P. S. L. M. Barreto, Demonstrating data possession and uncheatable data transfer, IACR Cryptology ePrint Archive, 2006 (2006), 150. |
| [53] |
K. P. Kibiwott, Y. Zhao, J. Kogo, et al. Verifiable fully outsourced attribute-based signcryption system for IoT eHealth big data in cloud computing, Mathematical Biosciences and Engineering, 16 (2019), 3561-3594. doi: 10.3934/mbe.2019178
|
| [54] |
G. Fuchs, H. Stange, D. Hecker, et al. Constructing semantic interpretation of routine and anomalous mobility behaviors from big data, SIGSPATIAL Special, 7 (2015), 27-34. doi: 10.1145/2782759.2782765
|
| [55] | G. Remya, A. Mohan, Distributed Computing Based Methods for Anomaly Analysis in Large Datasets, International Journal of Advanced Research in Computer and Communication Engineering, 4 (2015), 427-430. |
| [56] |
F. Restuccia, S. D. Kanhere, T. Melodia, et al. Blockchain for the Internet of Things: Present and Future, IEEE Internet of Things Journal, 1 (2018), 1-8. doi: 10.1109/MIOT.2018.8717586
|
| [57] |
K. Christidis, M. Devetsiokiotis, Blockchains and Smart Contracts for the IoT, IEEE Access, 4 (2016), 2292-2303. doi: 10.1109/ACCESS.2016.2566339
|
| [58] | D. Yaga, P. Mell, N. Roby, et al. Blockchain Technology Overview, National Institute of Standards and Technology, U.S. Department of Commerce, (2018), 1-27. |
| [59] | U. U. Uchibeke, K. A. Schneider, S. H. Kassani, et al. Blockchain Access Control Ecosystem for Big Data Security. In: 2018 IEEE International Conference on Internet of Things (iThings) and IEEE Green Computing and Communications (GreenCom) and IEEE Cyber, Physical and Social Computing (CPSCom) and IEEE Smart Data (SmartData), (2018), 1373-1378. |
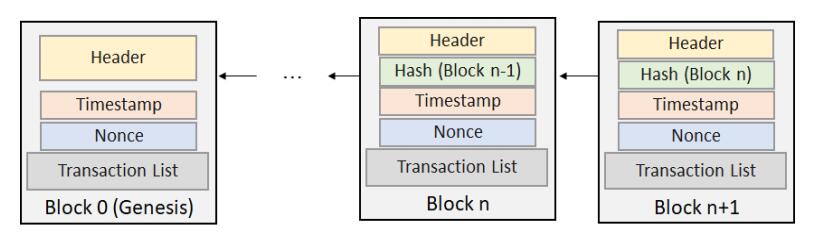
Figures(5)

Sitalakshmi Venkatraman, Ramanathan Venkatraman. Big data security challenges and strategies[J]. AIMS Mathematics, 2019, 4(3): 860-879. doi: 10.3934/math.2019.3.860







 DownLoad:
DownLoad: