Citation: Brian E. Bunker, Jason A. Tullis, Jackson D. Cothren, Jesse Casana, Mohamed H. Aly. Object-based Dimensionality Reduction in Land Surface Phenology Classification[J]. AIMS Geosciences, 2016, 2(4): 302-328. doi: 10.3934/geosci.2016.4.302

| [1] |
Garonna I, de Jong R, Schaepman ME (2016) Variability and Evolution of Global Land Surface Phenology Over the Past Three Decades (1982–2012). Glob Ch Biol 22: 1456-1468. doi: 10.1111/gcb.13168

|
| [2] | Morisette JT, Richardson AD, Knapp AK, et al. (2009) Tracking the Rhythm of the Seasons in the Face of Global Change: Phenological Research in the 21st Century. Front in Ecol and the Environ 7: 253-260. |
| [3] |
Trigo RM, Gouveia CM, Barriopedro D (2010) The Intense 2007–2009 Drought in the Fertile Crescent: Impacts and Associated Atmospheric Circulation. Agric For Meteorol 150: 1245-1257. doi: 10.1016/j.agrformet.2010.05.006
|
| [4] |
Bajgiran PR, Darvishsefat AA, Khalili A, et al. (2008) Using AVHRR-based Vegetation Indices for Drought Monitoring in the Northwest of Iran. J of Arid Environ 72: 1086-1096. doi: 10.1016/j.jaridenv.2007.12.004
|
| [5] |
Beaumont P (1996) Agricultural and Environmental Changes in the Upper Euphrates Catchment of Turkey and Syria and Their Political and Economic Implications. Appl Geogr 16: 137-157. doi: 10.1016/0143-6228(95)00033-X
|
| [6] | Perrin de Brichambaut G, Wallen CC (1963) A Study of Agroclimatology in Semi-arid and Arid Zones of the Near East. Geneva, Switzerland: World Meteorological Organisation. Technical Note No. 56 Technical Note No. 56. p. 64. |
| [7] | Wilkinson TJ (2003) Archaeological Landscapes of the Near East. Tucson: University of Arizona Press. |
| [8] |
Gu Y, Brown JF, Miura T, et al. (2010) Phenological Classification of the United States: A Geographic Framework for Extending Multi-Sensor Time-Series Data. Remote Sens 2: 526-544. doi: 10.3390/rs2020526
|
| [9] |
Bisquert M, Begue A, Deshayes M (2015) Object-based Delineation of Homogeneous Landscape Units at Regional Scale Based on MODIS Time Series. Int J of Appl Earth Obs and Geoinform 37: 72-82. doi: 10.1016/j.jag.2014.10.004
|
| [10] |
Gómez C, White JC, Wulder MA (2016) Optical Remotely Sensed Time Series Data for Land Cover Classification: A Review. ISPRS J of Photogramm and Remote Sens 116: 55-72. doi: 10.1016/j.isprsjprs.2016.03.008
|
| [11] |
Shao Y, Lunetta RS, Wheeler B, et al. (2016) An Evaluation of Time-series Smoothing Algorithms for Land-cover Classifications Using MODIS-NDVI Multi-temporal Data. Remote Sens of Environ 174: 258-265. doi: 10.1016/j.rse.2015.12.023
|
| [12] | Bajocco S, Dragozi E, Gitas I, et al. (2015) Mapping Forest Fuels through Vegetation Phenology: the Role of Coarse-resolution Satellite Time-series. Plos One 10. |
| [13] | Jensen JR (2007) Remote Sensing of the Environment: An Earth Resource Perspective; Clarke KC, editor. Upper Saddle River, New Jersey: Prentice Hall. p. 592. |
| [14] |
Holben BN (1986) Characteristics of Maximum-value Composite Images from Temporal AVHRR Data. Int J of Remote Sens 7: 1417-1434. doi: 10.1080/01431168608948945
|
| [15] |
Vermote E, Kaufman YJ (1995) Absolute Calibration of AVHRR Visible and Near-infrared Channels Using Ocean and Cloud Views. Int J of Remote Sens 16: 2317-2340. doi: 10.1080/01431169508954561
|
| [16] |
Los SO (1998) Estimation of the Ratio of Sensor Degradation Between NOAA AVHRR Channels 1 and 2 from Monthly NDVI Composites. IEEE Trans on Geosci and Remote Sens 36: 206-213. doi: 10.1109/36.655330
|
| [17] |
Vermote E, El Saleous N, Kaufman YJ, et al. (1997) Data Pre-processing: Stratospheric Aerosol Perturbing Effect on the Remote Sensing of Vegetation: Correction Method for the Composite NDVI After the Pinatubo Eruption. Remote Sens Rev 15: 7-21. doi: 10.1080/02757259709532328
|
| [18] | Pinzón JE, Brown ME, Tucker CJ (2005) EMD Correction of Orbital Drift Artifacts in Satellite Data Stream. Hilbert-Huang Transform: Introd and Appl. pp. 167-186. |
| [19] | Clark RN, Swayze GA, Wise RA, et al. (2007) USGS Digital Spectral Library splib06a. Denver, Colorado: U.S. Geological Survey. |
| [20] |
Tucker CJ, Pinzon JE, Brown ME, et al. (2005) An Extended AVHRR 8-km NDVI Data Set Compatible with MODIS and SPOT Vegetation NDVI Data. Int J of Remote Sens 26: 4485-4498. doi: 10.1080/01431160500168686
|
| [21] | Deering DW, Rouse Jr. JW, Haas RH, et al. (1975) Measuring 'Forage Production' of Grazing Units From Landsat MSS Data. Proc of the 10th Int Symp on Remote Sens of the Environ 2: 1169-1178. |
| [22] |
Tucker CJ (1979) Red and Photographic Infrared Linear Combinations for Monitoring Vegetation. Remote Sens of Environ 8: 127-150. doi: 10.1016/0034-4257(79)90013-0
|
| [23] |
Geerken RA (2009) An Algorithm to Classify and Monitor Seasonal Variations in Vegetation Phenologies and their Inter-annual Change. ISPRS J of Photogramm and Remote Sens 64: 422-431. doi: 10.1016/j.isprsjprs.2009.03.001
|
| [24] |
Kouchoukos N (2001) Satellite Images and Near Eastern Landscapes. Near Earstern Archaeol 64: 80-91. doi: 10.2307/3210823
|
| [25] |
Nguyen TTH, De Bie CAJM, Ali A, et al. (2012) Mapping the Irrigated Rice Cropping Patterns of the Mekong Delta, Vietnam, Through Hyper-temporal SPOT NDVI Image Analysis. Int J of Remote Sens 33: 415-434. doi: 10.1080/01431161.2010.532826
|
| [26] |
Al-Bakri JT, Taylor JC (2003) Application of NOAA AVHRR for Monitoring Vegetation Conditions and Biomass in Jordan. J of Arid Environ 54: 579-593. doi: 10.1006/jare.2002.1081
|
| [27] |
Benedetti R, Rossini P, Taddei R (1994) Vegetation Classification in the Middle Mediterranean Area by Satellite Data. Int J of Remote Sens 15: 583-596. doi: 10.1080/01431169408954098
|
| [28] |
Evans J, Geerken R (2006) Classifying Rangeland Vegetation Type and Coverage Using a Fourier Component Based Similarity Measure. Remote Sens of Environ 105: 1-8. doi: 10.1016/j.rse.2006.05.017
|
| [29] |
Hölbling D, Friedl B, Eisank C (2015) An Object-based Approach for Semi-automated Landslide Change Detection and Attribution of Changes to Landslide Classes in Northern Taiwan. Earth Sci Inform 8: 327-335. doi: 10.1007/s12145-015-0217-3
|
| [30] |
Bontemps S, Bogaert P, Titeux N, et al. (2008) An Object-based Change Detection Method Accounting for Temporal Dependences in Time Series with Medium to Coarse Spatial Resolution. Remote Sens of Environ 112: 3181-3191. doi: 10.1016/j.rse.2008.03.013
|
| [31] |
Hüttich C, Herold M, Strohbach B, et al. (2011) Integrating In-situ, Landsat, and MODIS Data for Mapping in Southern African Savannas: Experiences of LCCS-based Land-cover Mapping in the Kalahari in Namibia. Environ Monit and Assess 176: 531-547. doi: 10.1007/s10661-010-1602-5
|
| [32] |
De Angelis A, Bajocco S, Ricotta C (2012) Phenological Variability Drives the Distribution of Wildfires in Sardinia. Landsc Ecol 27: 1535-1545. doi: 10.1007/s10980-012-9808-2
|
| [33] |
Zhong LH, Gong P, Biging GS (2012) Phenology-based Crop Classification Algorithm and its Implications on Agricultural Water Use Assessments in California's Central Valley. Photogramm Eng and Remote Sens 78: 799-813. doi: 10.14358/PERS.78.8.799
|
| [34] | Tou JT, Gonzalez RC (1974) Pattern Recognition Principles. Reading, Massachusetts: Addison-Wesley. |
| [35] | Swain PH, Davis SM (1978) Remote Sensing: The Quantitative Approach: McGraw-Hill International Book Co. |
| [36] |
Cohen J (1960) A Coefficient of Agreement for Nominal Scales. Educ Psychol Meas 20: 37-46. doi: 10.1177/001316446002000104
|
| [37] | Jensen JR (2016) Introductory Digital Image Processing: A Remote Sensing Perspecitve; Clarke KC, editor: Pearson Education. p. 623. |
| [38] |
Arbelaitz O, Gurrutxaga I, Muguerza J, et al. (2013) An Extensive Comparative Study of Cluster Validity Indices. Pattern Recognit 46: 243-256. doi: 10.1016/j.patcog.2012.07.021
|
| [39] | ERDAS (2010) ERDAS Field Guide. Norcross, GA: ERDAS, Inc. 812 p. |
| [40] |
Ward JH (1963) Hierarchical Grouping to Optimize an Objective Function. J Am Stat Assoc 58: 236-244. doi: 10.1080/01621459.1963.10500845
|
| [41] | Baatz M, Schäpe A. Multiresolution Segmentation: an Optimization Approach for High Quality Multi-scale Image Segmentation; 2000 2000. Herbert Wichmann Verlag. |
| [42] |
Sun W, Li W, Li J, et al. (2015) Band Selection Using Sparse Nonnegative Matrix Factorization with the Thresholded Earth’s Mover Distance for Hyperspectral Imagery Classification. Earth Sci Inform 8: 907-918. doi: 10.1007/s12145-014-0201-3
|
| [43] | Hole F, Zaitchik BF (2007) Policies, Plans, Practice, and Prospects: Irrigation in Northeastern Syria. Land Degrad & Dev 18: 133-152. |
| [44] |
Riehl S (2012) Variability in Ancient Near Eastern Environmental and Agricultural Development. J of Arid Environ 86: 113-121. doi: 10.1016/j.jaridenv.2011.09.014
|
| [45] |
Wilkinson TJ (1994) The Structure and Dynamics of Dry-Farming States in Upper Mesopotamia. Curr Anthropol 35: 483-520. doi: 10.1086/204314
|
| [46] |
Staubwasser M, Weiss H (2006) Holocene Climate and Cultural Evolution in Late Prehistoric–early Historic West Asia. Quat Res 66: 372-387. doi: 10.1016/j.yqres.2006.09.001
|
| [47] |
Bar-Yosef O (2011) Climatic Fluctuations and Early Farming in West and East Asia. Curr Anthropol 52: S175-S193. doi: 10.1086/659784
|
| [48] |
Ur JA (2010) Cycles of Civilization in Northern Mesopotamia, 4400-2000 BC. J of Archaeol Res 18: 387-431. doi: 10.1007/s10814-010-9041-y
|
| [49] | NASA (2016) Reverb | ECHO: The Next Generation Earth Science Discovery Tool. |
| [50] | Solano R, Didan K, Jacobson A, et al. (2010) MODIS Vegetation Index User's Guide (MOD13 Series) Version 2.00. Vegetation Index and Phenology Lab, The University of Arizona. |
| [51] | USGS (2016) USGS Global Visualization Viewer. |
| [52] | Trimble (2013) eCognition Software. |
| [53] | Congalton R (2010) Remote Sensing: An Overview. GISci & Remote Sens 47: 443-459. |
| [54] | Casana J, Cothren J, Kalayci T (2012) Swords into Ploughshares: Archaeological Applications of CORONA Satellite Imagery in the Near East. Internet Archaeology. |
| [55] |
Li QT, Wang CZ, Zhang B, et al. (2015) Object-based Crop Classification with Landsat-MODIS Enhanced Time-series Data. Remote Sens 7: 16091-16107. doi: 10.3390/rs71215820
|
| [56] |
Zehtabian A, Ghassemian H (2015) An Adaptive Pixon Extraction Technique for Multispectral/Hyperspectral Image Classification. IEEE Geosci and Remote Sens Lett 12: 831-835. doi: 10.1109/LGRS.2014.2363586
|
| [57] | Zehtabian A, Ghassemian H (2016) Automatic Object-Based Hyperspectral Image Classification Using Complex Diffusions and a New Distance Metric. IEEE Trans on Geosci and Remote Sens 54: 4106-4114. |
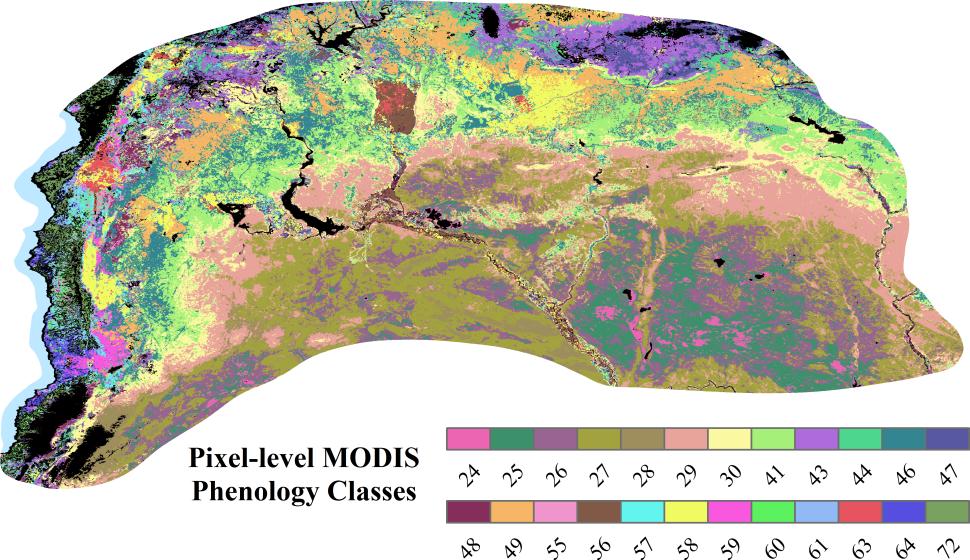
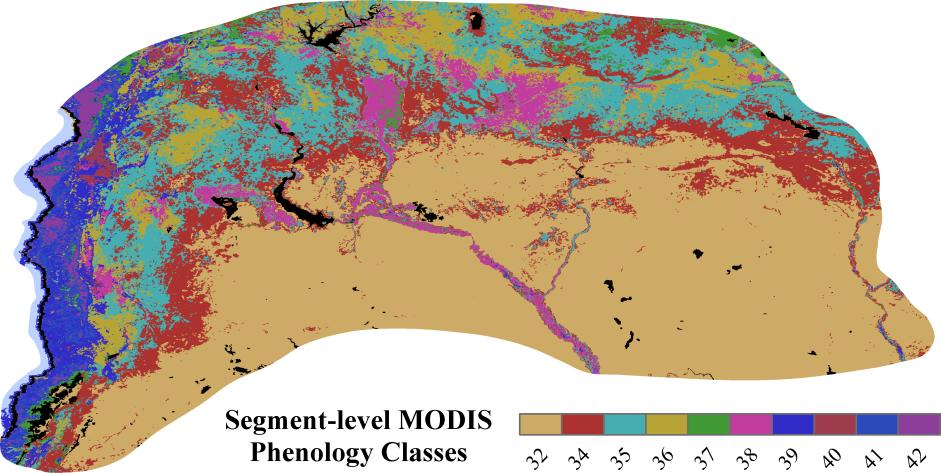



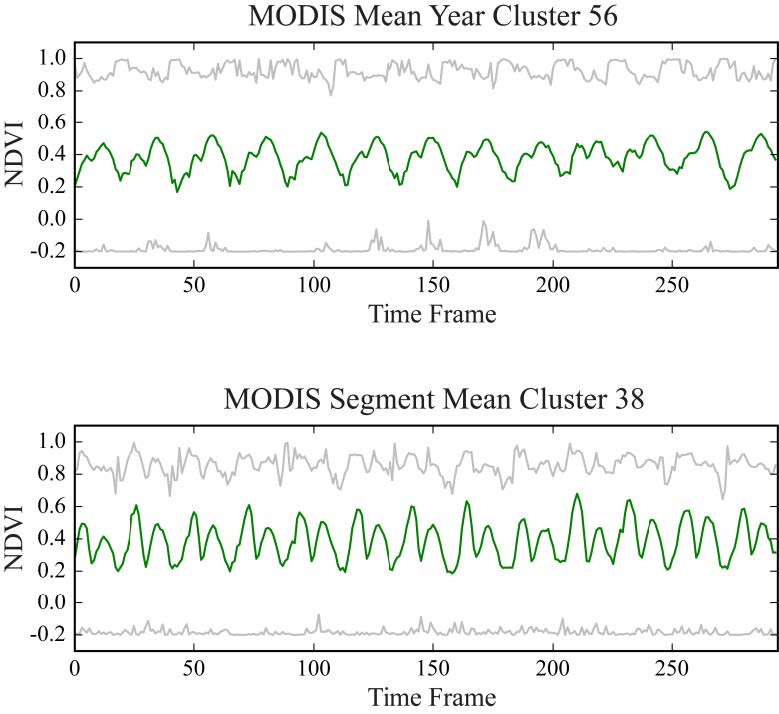
Figures(14) / Tables(2)

Brian E. Bunker, Jason A. Tullis, Jackson D. Cothren, Jesse Casana, Mohamed H. Aly. Object-based Dimensionality Reduction in Land Surface Phenology Classification[J]. AIMS Geosciences, 2016, 2(4): 302-328. doi: 10.3934/geosci.2016.4.302







 DownLoad:
DownLoad: