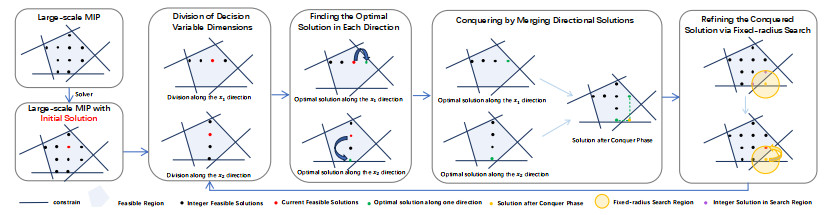
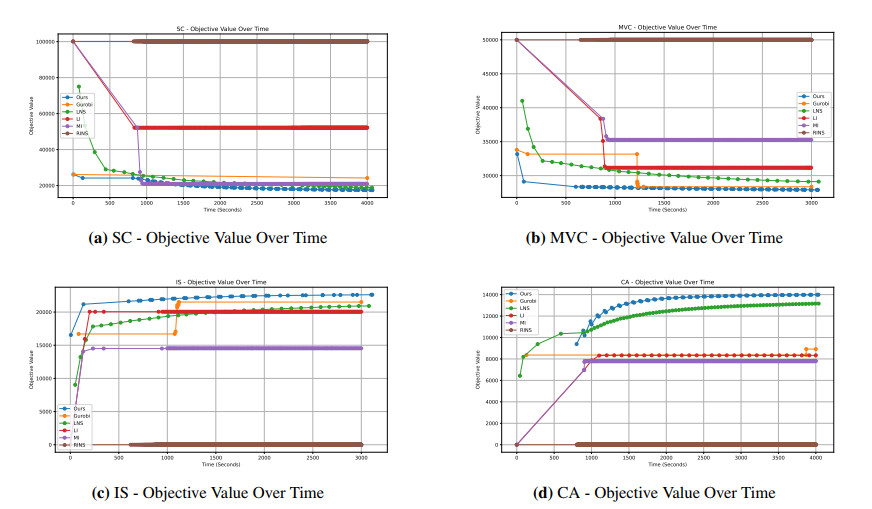
Integer programming (IP) is a fundamental combinatorial optimization problem, traditionally solved using branch-and-bound methods. However, these methods often struggle with large-scale instances as they attempt to solve the entire problem at once. Existing heuristics, such as a large neighborhood search (LNS), improve efficiency but lack a structured decomposition strategy. We have proposed a divide-and-conquer strategy for IP, which partitions decision variables based on constraint relationships, optimizes them in smaller subproblems, and progressively merges solutions while repairing constraints. This structured approach significantly enhances both solution quality and computational efficiency. Experiments on four standard benchmarks—minimum vertex cover (MVC), maximum independent set (MIS), set cover (SC), and combinatorial auction (CA)—demonstrated that our method significantly outperforms both state-of-the-art solvers (e.g., Gurobi, SCIP) and advanced LNS-based heuristics. When using Gurobi and SCIP as sub-solvers, our approach achieved up to 30× improvement in objective value on certain tasks (e.g., MIS), and reduced solution cost by over 44% compared to exact solvers in minimization settings (e.g., MVC). In addition, our method showed consistently faster convergence and better final solution quality across all tested problems. These results highlight the robustness and scalability of our divide-and-conquer strategy, establishing it as a powerful framework for solving large-scale integer programming problems beyond the capabilities of traditional and heuristic-based solvers.
Citation: Chao Yang, Xifeng Ning, Dejun Yu, Hailu Sun, Guohui Kang, Hongyan Wang. A divide-and-conquer strategy for integer programming problems[J]. Electronic Research Archive, 2025, 33(6): 3950-3967. doi: 10.3934/era.2025175
Integer programming (IP) is a fundamental combinatorial optimization problem, traditionally solved using branch-and-bound methods. However, these methods often struggle with large-scale instances as they attempt to solve the entire problem at once. Existing heuristics, such as a large neighborhood search (LNS), improve efficiency but lack a structured decomposition strategy. We have proposed a divide-and-conquer strategy for IP, which partitions decision variables based on constraint relationships, optimizes them in smaller subproblems, and progressively merges solutions while repairing constraints. This structured approach significantly enhances both solution quality and computational efficiency. Experiments on four standard benchmarks—minimum vertex cover (MVC), maximum independent set (MIS), set cover (SC), and combinatorial auction (CA)—demonstrated that our method significantly outperforms both state-of-the-art solvers (e.g., Gurobi, SCIP) and advanced LNS-based heuristics. When using Gurobi and SCIP as sub-solvers, our approach achieved up to 30× improvement in objective value on certain tasks (e.g., MIS), and reduced solution cost by over 44% compared to exact solvers in minimization settings (e.g., MVC). In addition, our method showed consistently faster convergence and better final solution quality across all tested problems. These results highlight the robustness and scalability of our divide-and-conquer strategy, establishing it as a powerful framework for solving large-scale integer programming problems beyond the capabilities of traditional and heuristic-based solvers.

| [1] |
J. J. Troncoso, R. A. Garrido, Forestry production and logistics planning: an analysis using mixed-integer programming, For. Policy Econ., 7 (2005), 625–633. https://doi.org/10.1016/j.forpol.2003.12.002 doi: 10.1016/j.forpol.2003.12.002

|
| [2] |
N. Ö. Demirel, H. Gökçen, A mixed integer programming model for remanufacturing in reverse logistics environment, Int. J. Adv. Manuf. Technol., 39 (2008), 1197–1206. https://doi.org/10.1007/s00170-007-1290-7 doi: 10.1007/s00170-007-1290-7
|
| [3] | D. M. Ryan, B. A. Foster, An integer programming approach to scheduling, Comput. Sched. Public Transport Urban Passenger Veh. Crew Sched., (1981), 269–280. |
| [4] |
K. Wilken, J. Liu, M. Heffernan, Optimal instruction scheduling using integer programming, ACM Sigplan Not., 35 (2000), 121–133. https://doi.org/10.1145/358438.349318 doi: 10.1145/358438.349318
|
| [5] |
Y. Dong, J. Tao, Y. Zhang, W. Lin, J. Ai, Deep learning in aircraft design, dynamics, and control: Review and prospects, IEEE Trans. Aerosp. Electron. Syst., 57 (2021), 2346–2368. https://doi.org/10.1109/TAES.2021.3056086 doi: 10.1109/TAES.2021.3056086
|
| [6] | S. Muroga, Logical design of optimal digital networks by integer programming, in Advances in Information Systems Science, Springer, Boston, MA, (1970), 283–348. https://doi.org/10.1007/978-1-4615-8243-4_5 |
| [7] |
R. G. Garroppo, S. Giordano, G. Nencioni, M. G. Scutellà, Mixed integer non-linear programming models for green network design, Comput. Oper. Res., 40 (2013), 273–281. https://doi.org/10.1016/j.cor.2012.06.014 doi: 10.1016/j.cor.2012.06.014
|
| [8] | H. Ye, H. Xu, H. Wang, C. Wang, Y. Jiang, GNN & GBDT-guided fast optimizing framework for large-scale integer programming, in Proceedings of the 40th International Conference on Machine Learning, PMLR, 202 (2023), 39864–39878. |
| [9] | H. Ye, H. Xu, H. Wang, Light-MILPOpt: Solving large-scale mixed integer linear programs with lightweight optimizer and small-scale training dataset, in The Twelfth International Conference on Learning Representations, 2024. |
| [10] | A. Paulus, M. Rolínek, V. Musil, B. Amos, G. Martius, Comboptnet: Fit the right NP-hard problem by learning integer programming constraints, in Proceedings of the 38th International Conference on Machine Learning, PMLR, 139 (2021), 8443–8453. |
| [11] | L. Huang, X. Chen, W. Huo, J. Wang, F. Zhang, B. Bai, et al., Branch and bound in mixed integer linear programming problems: A survey of techniques and trends, preprint, arXiv: 2111.06257. https://doi.org/10.48550/arXiv.2111.06257 |
| [12] |
J. A. Tomlin, An improved branch-and-bound method for integer programming, Oper. Res., 19 (1971), 1070–1075. https://doi.org/10.1287/opre.19.4.1070 doi: 10.1287/opre.19.4.1070
|
| [13] | S. Boyd, J. Mattingley, Branch and bound methods, Notes for EE364b, Stanford University, 2007. |
| [14] |
G. A. Kochenberger, B. A. McCarl, F. P. Wyman, A heuristic for general integer programming, Decis. Sci., 5 (1974). https://doi.org/10.1111/j.1540-5915.1974.tb00593.x doi: 10.1111/j.1540-5915.1974.tb00593.x
|
| [15] | H. Ye, H. Wang, H. Xu, C. Wang, Y. Jiang, Adaptive constraint partition based optimization framework for large-scale integer linear programming (student abstract), in Proceedings of the AAAI Conference on Artificial Intelligence, 37 (2023), 16376–16377. https://doi.org/10.1609/aaai.v37i13.27048 |
| [16] |
D. Chen, X. Zheng, C. Chen, W. Zhao, Remaining useful life prediction of the lithium-ion battery based on CNN-LSTM fusion model and grey relational analysis, Electron. Res. Arch., 31 (2023), 633–655. https://doi.org/10.3934/era.2023031 doi: 10.3934/era.2023031
|
| [17] |
R. Ramalingam, S. Basheer, P. Balasubramanian, M. Rashid, G. Jayaraman, EECHS-ARO: Energy-efficient cluster head selection mechanism for livestock industry using artificial rabbits optimization and wireless sensor networks, Electron. Res. Arch., 31 (2023), 3123–3144. https://doi.org/10.3934/era.2023158 doi: 10.3934/era.2023158
|
| [18] | J. Song, Y. Yue, B. Dilkina, A general large neighborhood search framework for solving integer linear programs, Adv. Neural Inf. Process. Syst., 33 (2020), 20012–20023. |
| [19] |
G. Hendel, Adaptive large neighborhood search for mixed integer programming, Math. Program. Comput., 14 (2022), 185–221. https://doi.org/10.1007/s12532-021-00209-7 doi: 10.1007/s12532-021-00209-7
|
| [20] |
J. M. Robson, Algorithms for maximum independent sets, J. Algorithms, 7 (1986), 425–440. https://doi.org/10.1016/0196-6774(86)90032-5 doi: 10.1016/0196-6774(86)90032-5
|
| [21] | D. S. Hochbaum, Approximating covering and packing problems: set cover, vertex cover, independent set, and related problems, Approximation Algorithms NP-Hard Probl., (1997), 94–143. |
| [22] | N. Alon, B. Awerbuch, Y. Azar, The online set cover problem, in Proceedings of the Thirty-Fifth Annual ACM Symposium on Theory of Computing, (2003), 100–105. https://doi.org/10.1145/780542.780558 |
| [23] | P. Cramton, Y. Shoham, R. Steinberg, Introduction to combinatorial auctions, Comb. Auctions, (2006), 1–14. |
| [24] | J. P. Pedroso, Optimization with Gurobi and Python, in INESC Porto and Universidade do Porto, Porto, Portugal, 1 (2011). |
| [25] |
T. Achterberg, SCIP: Solving constraint integer programs, Math. Program. Comput., 1 (2009), 1–41. https://doi.org/10.1007/s12532-008-0001-1 doi: 10.1007/s12532-008-0001-1
|
| [26] | T. Berthold, Primal Heuristics for Mixed Integer Programs, Ph.D. thesis, Zuse Institute Berlin (ZIB), 2006. |
| [27] | V. Nair, M. Alizadeh, Neural large neighborhood search, in Learning Meets Combinatorial Algorithms at NeurIPS2020, 2020. |
| [28] |
E. Danna, E. Rothberg, C. L. Pape, Exploring relaxation induced neighborhoods to improve MIP solutions, Math. Program., 102 (2005), 71–90. https://doi.org/10.1007/s10107-004-0518-7 doi: 10.1007/s10107-004-0518-7
|
| [29] | L. A. Wolsey, G. L. Nemhauser, Integer and Combinatorial Optimization, John Wiley & Sons, 1999. https://doi.org/10.1057/jors.1990.26 |
| [30] | J. E. Mitchell, Branch-and-cut algorithms for combinatorial optimization problems, Handb. Appl. Optim., 1 (2002), 65–77. |
| [31] |
Y. Wu, W. Song, Z. Cao, J. Zhang, Learning large neighborhood search policy for integer programming, Adv. Neural Inf. Process. Syst., 34 (2021), 30075–30087. https://doi.org/10.48550/arXiv.2111.03466 doi: 10.48550/arXiv.2111.03466
|
| [32] | N. Sonnerat, P. Wang, I. Ktena, S. Bartunov, V. Nair, Learning a large neighborhood search algorithm for mixed integer programs, preprint, arXiv: 2107.10201. https://doi.org/10.48550/arXiv.2107.10201 |
| [33] |
A. W. Beggs, On the convergence of reinforcement learning, J. Econ. Theory, 122 (2005), 1–36. https://doi.org/10.1016/j.jet.2004.03.008 doi: 10.1016/j.jet.2004.03.008
|
| [34] | T. Huang, A. M. Ferber, Y. Tian, B. Dilkina, B. Steiner, Searching large neighborhoods for integer linear programs with contrastive learning, in Proceedings of the 40th International Conference on Machine Learning, PMLR, (2023), 13869–13890. https://doi.org/10.48550/arXiv.2302.01578 |
Figures(2) / Tables(4)
Chao Yang, Xifeng Ning, Dejun Yu, Hailu Sun, Guohui Kang, Hongyan Wang. A divide-and-conquer strategy for integer programming problems[J]. Electronic Research Archive, 2025, 33(6): 3950-3967. doi: 10.3934/era.2025175







 DownLoad:
DownLoad: