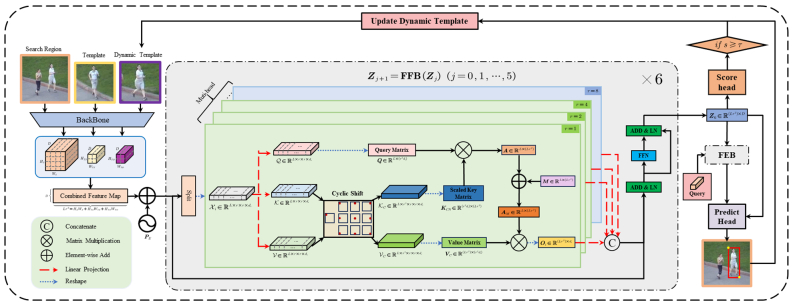
In recent years, Transformer-based object trackers have demonstrated exceptional performance in object tracking. However, traditional methods often employ single-scale pixel-level attention mechanisms to compute the correlation between templates and search regions, disrupting object's integrity and positional information. To address these issues, we introduce a cyclic-shift mechanism to expand the diversity of sample positions and replace the traditional single-scale pixel-level attention mechanism with a multi-scale window-level attention mechanism. This approach not only preserves the object's integrity but also enriches the diversity of samples. Nevertheless, the introduced cyclic-shift operation heavily burdens storage and computation. To this end, we treat the attention computation of shifted and static windows in the spatial domain as convolution. By leveraging the convolution theorem, we transform the attention computation of cyclic shift samples from the spatial domain to element-wise multiplication in the frequency domain. This approach enhances computational efficiency and reduces data storage requirements. We conducted extensive experiments on the proposed module. The results demonstrate that the proposed module outperforms multiple existing tracking algorithms regarding performance. Moreover, ablation studies show that the method effectively reduces the storage and computational burden without compromising performance.
Citation: Huanyu Wu, Yingpin Chen, Changhui Wu, Ronghuan Zhang, Kaiwei Chen. A multi-scale cyclic-shift window Transformer object tracker based on fast Fourier transform[J]. Electronic Research Archive, 2025, 33(6): 3638-3672. doi: 10.3934/era.2025162
In recent years, Transformer-based object trackers have demonstrated exceptional performance in object tracking. However, traditional methods often employ single-scale pixel-level attention mechanisms to compute the correlation between templates and search regions, disrupting object's integrity and positional information. To address these issues, we introduce a cyclic-shift mechanism to expand the diversity of sample positions and replace the traditional single-scale pixel-level attention mechanism with a multi-scale window-level attention mechanism. This approach not only preserves the object's integrity but also enriches the diversity of samples. Nevertheless, the introduced cyclic-shift operation heavily burdens storage and computation. To this end, we treat the attention computation of shifted and static windows in the spatial domain as convolution. By leveraging the convolution theorem, we transform the attention computation of cyclic shift samples from the spatial domain to element-wise multiplication in the frequency domain. This approach enhances computational efficiency and reduces data storage requirements. We conducted extensive experiments on the proposed module. The results demonstrate that the proposed module outperforms multiple existing tracking algorithms regarding performance. Moreover, ablation studies show that the method effectively reduces the storage and computational burden without compromising performance.

| [1] |
Y. Li, X. Yuan, H. Wu, L. Zhang, R. Wang, J. Chen, CVT-track: Concentrating on valid tokens for one-stream tracking, IEEE Trans. Circuits Syst. Video Technol., 34 (2024), 321–334. https://doi.org/10.1109/TCSVT.2024.3452231 doi: 10.1109/TCSVT.2024.3452231

|
| [2] |
S. Zhang, Y. Chen, ATM-DEN: Image inpainting via attention transfer module and decoder-encoder network, SPIC, 133 (2025), 117268. https://doi.org/10.1016/j.image.2025.117268 doi: 10.1016/j.image.2025.117268
|
| [3] |
F. Chen, X. Wang, Y. Zhao, S. Lv, X. Niu, Visual object tracking: A survey, Comput. Vision Image Underst., 222 (2022), 103508. https://doi.org/10.1016/j.cviu.2022.103508 doi: 10.1016/j.cviu.2022.103508
|
| [4] |
F. Zhang, S. Ma, Z. Qiu, T. Qi, Learning target-aware background-suppressed correlation filters with dual regression for real-time UAV tracking, Signal Process., 191 (2022), 108352. https://doi.org/10.1016/j.sigpro.2021.108352 doi: 10.1016/j.sigpro.2021.108352
|
| [5] |
S. Ma, B. Zhao, Z. Hou, W. Yu, L. Pu, X. Yang, SOCF: A correlation filter for real-time UAV tracking based on spatial disturbance suppression and object saliency-aware, Expert Syst. Appl., 238 (2024), 122131. https://doi.org/10.1016/j.eswa.2023.122131 doi: 10.1016/j.eswa.2023.122131
|
| [6] |
J. Lin, J. Peng, J. Chai, Real-time UAV correlation filter based on response-weighted background residual and spatio-temporal regularization, IEEE Geosci. Remote Sens. Lett., 20 (2023), 1–5. https://doi.org/10.1109/LGRS.2023.3272522 doi: 10.1109/LGRS.2023.3272522
|
| [7] |
J. Cao, H. Zhang, L. Jin, J. Lv, G. Hou, C. Zhang, A review of object tracking methods: From general field to autonomous vehicles, Neurocomputing, 585 (2024), 127635. https://doi.org/10.1016/j.neucom.2024.127635 doi: 10.1016/j.neucom.2024.127635
|
| [8] |
X. Hao, Y. Xia, H. Yang, Z. Zuo, Asynchronous information fusion in intelligent driving systems for target tracking using cameras and radars, IEEE Trans. Ind. Electron., 70 (2023), 2708–2717. https://doi.org/10.1109/TIE.2022.3169717 doi: 10.1109/TIE.2022.3169717
|
| [9] |
L. Liang, Z. Chen, L. Dai, S. Wang, Target signature network for small object tracking, Eng. Appl. Artif. Intell., 138 (2024), 109445. https://doi.org/10.1016/j.engappai.2024.109445 doi: 10.1016/j.engappai.2024.109445
|
| [10] |
R. Yao, L. Zhang, Y. Zhou, H. Zhu, J. Zhao, Z. Shao, Hyperspectral object tracking with dual-stream prompt, IEEE Trans. Geosci. Remote Sens., 63 (2025), 1–12. https://doi.org/10.1109/TGRS.2024.3516833 doi: 10.1109/TGRS.2024.3516833
|
| [11] |
N. K. Rathore, S. Pande, A. Purohit, An efficient visual tracking system based on extreme learning machine in the defence and military sector, Def. Sci. J., 74 (2024), 643–650. https://doi.org/10.14429/dsj.74.19576 doi: 10.14429/dsj.74.19576
|
| [12] |
Y. Chen, Y. Tang, Y. Xiao, Q. Yuan, Y. Zhang, F. Liu, et al., Satellite video single object tracking: A systematic review and an oriented object tracking benchmark, ISPRS J. Photogramm. Remote Sens., 210 (2024), 212–240. https://doi.org/10.1016/j.isprsjprs.2024.03.013 doi: 10.1016/j.isprsjprs.2024.03.013
|
| [13] | W. Cai, Q. Liu, Y. Wang, HIPTrack: Visual tracking with historical prompts, in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2024), 19258–19267. https://doi.org/10.1109/CVPR52733.2024.01822 |
| [14] |
L. Sun, J. Zhang, D. Gao, B. Fan, Z. Fu, Occlusion-aware visual object tracking based on multi-template updating Siamese network, Digit. Signal Process., 148 (2024), 104440. https://doi.org/10.1016/j.dsp.2024.104440 doi: 10.1016/j.dsp.2024.104440
|
| [15] |
Y. Chen, L. Wang, eMoE-Tracker: Environmental MoE-based transformer for robust event-guided object tracking, IEEE Robot. Autom. Lett., 10 (2025), 1393–1400. https://doi.org/10.1109/LRA.2024.3518305 doi: 10.1109/LRA.2024.3518305
|
| [16] |
Y. Sun, T. Wu, X. Peng, M. Li, D. Liu, Y. Liu, et al., Adaptive representation-aligned modeling for visual tracking, Knowl. Based Syst., 309 (2025), 112847. https://doi.org/10.1016/j.knosys.2024.112847 doi: 10.1016/j.knosys.2024.112847
|
| [17] |
J. Wang, S. Yang, Y. Wang, G. Yang, PPTtrack: Pyramid pooling based Transformer backbone for visual tracking, Expert Syst. Appl., 249 (2024), 123716. https://doi.org/10.1016/j.eswa.2024.123716 doi: 10.1016/j.eswa.2024.123716
|
| [18] |
C. Wu, J. Shen, K. Chen, Y. Chen, Y. Liao, UAV object tracking algorithm based on spatial saliency-aware correlation filter, Electron. Res. Arch., 33 (2025), 1446–1475. https://doi.org/10.3934/era.2025068 doi: 10.3934/era.2025068
|
| [19] |
A. Lukežič, T. Vojíř, L. Čehovin, J. Matas, M. Kristan, Discriminative correlation filter with channel and spatial reliability, Int. J. Comput. Vision, 126 (2018), 671–688. https://doi.org/10.1007/s11263-017-1061-3 doi: 10.1007/s11263-017-1061-3
|
| [20] |
T. Xu, Z. Feng, X. Wu, J. Kittler, Learning adaptive discriminative correlation filters via temporal consistency preserving spatial feature selection for robust visual object tracking, IEEE Trans. Image Process., 28 (2019), 5596–5609. https://doi.org/10.1109/TIP.2019.2919201 doi: 10.1109/TIP.2019.2919201
|
| [21] |
J. F. Henriques, R. Caseiro, P. Martins, J. Batista, High-speed tracking with kernelized correlation filters, IEEE Trans. Pattern Anal. Mach. Intell., 37 (2015), 583–596. https://doi.org/10.1109/TPAMI.2014.2345390 doi: 10.1109/TPAMI.2014.2345390
|
| [22] |
E. O. Brigham, R. E. Morrow, The fast Fourier transform, IEEE Spectrum, 4 (1967), 63–70. https://doi.org/10.1109/MSPEC.1967.5217220 doi: 10.1109/MSPEC.1967.5217220
|
| [23] | H. K. Galoogahi, A. Fagg, S. Lucey, Learning background-aware correlation filters for visual tracking, in IEEE International Conference on Computer Vision (ICCV), (2017), 1144–1152. https://doi.org/10.1109/ICCV.2017.129 |
| [24] | Z. Zhang, H. Peng, J. Fu, B. Li, W. Hu, Ocean: Object-aware anchor-free tracking, in European Conference on Computer Vision (ECCV), (2020), 771–787. https://doi.org/10.1007/978-3-030-58589-1_46 |
| [25] |
Y. Zhang, H. Pan, J. Wang, Enabling deformation slack in tracking with temporally even correlation filters, Neural Networks, 181 (2025), 106839. https://doi.org/10.1016/j.neunet.2024.106839 doi: 10.1016/j.neunet.2024.106839
|
| [26] |
Y. Chen, H. Wu, Z. Deng, J. Zhang, H. Wang, L. Wang, et al., Deep-feature-based asymmetrical background-aware correlation filter for object tracking, Digit. Signal Process., 148 (2024), 104446. https://doi.org/10.1016/j.dsp.2024.104446 doi: 10.1016/j.dsp.2024.104446
|
| [27] |
K. Chen, L. Wang, H. Wu, C. Wu, Y. Liao, Y. Chen, et al., Background-aware correlation filter for object tracking with deep CNN features, Eng. Lett., 32 (2024), 1353–1363. https://doi.org/10.1016/j.dsp.2024.104446 doi: 10.1016/j.dsp.2024.104446
|
| [28] |
J. Zhang, Y. He, W. Chen, L. D. Kuang, B. Zheng, CorrFormer: Context-aware tracking with cross-correlation and transformer, Comput. Electr. Eng., 114 (2024), 109075. https://doi.org/10.1016/j.compeleceng.2024.109075 doi: 10.1016/j.compeleceng.2024.109075
|
| [29] | L. Bertinetto, J. Valmadre, J. F. Henriques, A. Vedaldi, P. H. Torr, Fully-convolutional siamese networks for object tracking, in European Conference on Computer Vision (ECCV), (2016), 850–865. https://doi.org/10.1007/978-3-319-48881-3_56 |
| [30] | Q. Guo, W. Feng, C. Zhou, R. Huang, L. Wan, S. Wang, Learning dynamic siamese network for visual object tracking, in IEEE International Conference on Computer Vision (ICCV), (2017), 1781–1789. https://doi.org/10.1109/ICCV.2017.196 |
| [31] | B. Li, J. Yan, W. Wu, Z. Zhu, X. Hu, High performance visual tracking with siamese region proposal network, in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2018), 8971–8980. |
| [32] | B. Li, W. Wu, Q. Wang, F. Zhang, J. Xing, J. Yan, SiamRPN++: Evolution of siamese visual tracking with very deep networks, in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2019), 4277–4286. |
| [33] |
L. Zhao, C. Fan, M. Li, Z. Zheng, X. Zhang, Global-local feature-mixed network with template update for visual tracking, Pattern Recognit. Lett., 188 (2025), 111–116. https://doi.org/10.1016/j.patrec.2024.11.034 doi: 10.1016/j.patrec.2024.11.034
|
| [34] |
F. Gu, J. Lu, C. Cai, Q. Zhu, Z. Ju, RTSformer: A robust toroidal transformer with spatiotemporal features for visual tracking, IEEE Trans. Human Mach. Syst., 54 (2024), 214–225. https://doi.org/10.1109/THMS.2024.3370582 doi: 10.1109/THMS.2024.3370582
|
| [35] |
O. Abdelaziz, M. Shehata, DMTrack: Learning deformable masked visual representations for single object tracking, SIViP, 19 (2025), 61. https://doi.org/10.1007/s11760-024-03713-0 doi: 10.1007/s11760-024-03713-0
|
| [36] | A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, et al., Attention is all you need, in the 31st International Conference on Neural Information Processing Systems (NIPS), (2017), 6000–6010. |
| [37] |
O. C. Koyun, R. K. Keser, S. O. Şahin, D. Bulut, M. Yorulmaz, V. Yücesoy, et al., RamanFormer: A Transformer-based quantification approach for raman mixture components, ACS Omega, 9 (2024), 23241–23251. https://doi.org/10.1021/acsomega.3c09247 doi: 10.1021/acsomega.3c09247
|
| [38] | H. Fan, X. Wang, S. Li, H. Ling, Joint feature learning and relation modeling for tracking: A one-stream framework, in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2022), 341–357. https://doi.org/10.1007/978-3-031-20047-2_20 |
| [39] |
H. Zhang, J. Song, H. Liu, Y. Han, Y. Yang, H. Ma, AwareTrack: Object awareness for visual tracking via templates interaction, Image Vision Comput., 154 (2025), 105363. https://doi.org/10.1016/j.imavis.2024.105363 doi: 10.1016/j.imavis.2024.105363
|
| [40] |
Z. Wang, L. Yuan, Y. Ren, S. Zhang, H. Tian, ADSTrack: Adaptive dynamic sampling for visual tracking, Complex Intell. Syst., 11 (2025), 79. https://doi.org/10.1007/s40747-024-01672-0 doi: 10.1007/s40747-024-01672-0
|
| [41] | X. Chen, B. Yan, J. Zhu, D. Wang, X. Yang, H. Lu, Transformer tracking, in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2021), 8122–8131. https://doi.org/10.1109/CVPR46437.2021.00803 |
| [42] | A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, et al., An image is worth 16x16 words: Transformers for image recognition at scale, preprint, arXiv: 2010.11929. https://doi.org/10.48550/arXiv.2010.11929 |
| [43] | B. Yan, H. Peng, J. Fu, D. Wang, H. Lu, Learning spatio-temporal transformer for visual tracking, in IEEE International Conference on Computer Vision (ICCV), (2021), 10428–10437. https://doi.org/10.1109/ICCV48922.2021.01028 |
| [44] | Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, et al., Swin Transformer: Hierarchical vision transformer using shifted windows, in IEEE/CVF International Conference on Computer Vision (ICCV), (2021), 10012–10022. https://doi.org/10.1109/ICCV48922.2021.00986 |
| [45] | L. Lin, H. Fan, Z. Zhang, Y. Xu, H. Ling, SwinTrack: A simple and strong baseline for transformer tracking, in Advances in Neural Information Processing Systems (NIPS), 35 (2022), 16743–16754. |
| [46] | Z. Song, J. Yu, Y. P. P. Chen, W. Yang, Transformer tracking with cyclic shifting window attention, in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2022), 8781–8790. https://doi.org/10.1109/CVPR52688.2022.00859 |
| [47] |
Y. Chen, K. Chen, Four mathematical modeling forms for correlation filter object tracking algorithms and the fast calculation for the filter, Electron. Res. Arch., 32 (2024), 4684–4714. https://doi.org/10.3934/era.2024213 doi: 10.3934/era.2024213
|
| [48] | H. Fan, L. Lin, F. Yang, P. Chu, G. Deng, S. Yu, et al., LaSOT: A high-quality benchmark for large-scale single object tracking, in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2019), 5369–5378. https://doi.org/10.1109/CVPR.2019.00552 |
| [49] | Y. Wu, J. Lim, M. -H. Yang, Online object tracking: A benchmark, in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2013), 2411–2418. https://doi.org/10.1109/CVPR.2013.312 |
| [50] | M. Mueller, N. Smith, B. Ghanem, A benchmark and simulator for UAV tracking, in Computer Vision–ECCV 2016, (2016), 445–461. https://doi.org/10.1007/978-3-319-46448-0_27 |
| [51] |
Y. Huang, Y. Chen, C. Lin, Q. Hu, J. Song, Visual attention learning and antiocclusion-based correlation filter for visual object tracking, J. Electron. Imaging, 32 (2023), 23. https://doi.org/10.1117/1.JEI.32.1.013023 doi: 10.1117/1.JEI.32.1.013023
|
| [52] | K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2016), 770–778. |
| [53] | N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, S. Zagoruyko, End-to-end object detection with transformers, in European Conference on Computer Vision (ECCV), (2020), 213–229. https://doi.org/10.1007/978-3-030-58452-8_13 |
| [54] | D. P. Kingma, J. Ba, Adam: A method for stochastic optimization, preprint, arXiv: 1412.6980. https://doi.org/10.48550/arXiv.1412.6980 |
| [55] |
Y. Cui, C. Jiang, G. Wu, L. Wang, MixFormer: End-to-end tracking with iterative mixed attention, IEEE Trans. Pattern Anal. Mach. Intell., 46 (2024), 4129–4146. https://doi.org/10.1109/TPAMI.2024.3349519 doi: 10.1109/TPAMI.2024.3349519
|
| [56] |
J. Shen, Y. Liu, X. Dong, X. Lu, F. S. Khan, S. Hoi, Distilled siamese networks for visual tracking, IEEE Trans. Pattern Anal. Mach. Intell., 44 (2022), 8896–8909. https://doi.org/10.1109/TPAMI.2021.3127492 doi: 10.1109/TPAMI.2021.3127492
|
| [57] |
X. Dong, J. Shen, F. Porikli, J. Luo, L. Shao, Adaptive siamese tracking with a compact latent network, IEEE Trans. Pattern Anal. Mach. Intell., 45 (2023), 8049–8062. https://doi.org/10.1109/TPAMI.2022.3230064 doi: 10.1109/TPAMI.2022.3230064
|
| [58] |
Z. Cao, Z. Huang, L. Pan, S. Zhang, Z. Liu, C. Fu, Towards real-world visual tracking with temporal contexts, IEEE Trans. Pattern Anal. Mach. Intell., 45 (2023), 15834–15849. https://doi.org/10.1109/TPAMI.2023.3307174 doi: 10.1109/TPAMI.2023.3307174
|
| [59] |
Y. Yang, X. Gu, Attention-based gating network for robust segmentation tracking, IEEE Trans. Circuits Syst. Video Technol., 35 (2025), 245–258. https://doi.org/10.1109/TCSVT.2024.3460400 doi: 10.1109/TCSVT.2024.3460400
|
| [60] |
W. Han, X. Dong, Y. Zhang, D. Crandall, C. Z. Xu, J. Shen, Asymmetric Convolution: An efficient and generalized method to fuse feature maps in multiple vision tasks, IEEE Trans. Pattern Anal. Mach. Intell., 46 (2024), 7363–7376. https://doi.org/10.1109/TPAMI.2024.3400873 doi: 10.1109/TPAMI.2024.3400873
|
| [61] |
X. Zhu, Y. Wu, D. Xu, Z. Feng, J. Kittler, Robust visual object tracking via adaptive attribute-aware discriminative correlation filters, IEEE Trans. Multimedia, 23 (2021), 2625–2638. https://doi.org/10.1109/TMM.2021.3050073 doi: 10.1109/TMM.2021.3050073
|
| [62] | M. Danelljan, H. Gustav, F. Shahbaz Khan, M. Felsberg, Learning spatially regularized correlation filters for visual tracking, in IEEE International Conference on Computer Vision (ICCV), (2015), 4310–4318. https://doi.org/10.1109/ICCV.2015.490 |
| [63] | J. Valmadre, L. Bertinetto, J. Henriques, A. Vedaldi, P. H. S. Torr, End-to-end representation learning for correlation filter based tracking, in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2017), 5000–5008. https://doi.org/10.1109/CVPR.2017.531 |
| [64] | G. Bhat, M. Danelljan, L. V. Gool, R. Timofte, Learning discriminative model prediction for tracking, in IEEE/CVF International Conference on Computer Vision (ICCV), (2019), 6182–6191. https://doi.org/10.1109/ICCV.2019.00628 |
| [65] | N. Wang, W. Zhou, J. Wang, H. Li, Transformer meets tracker: exploiting temporal context for robust visual tracking, in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2021), 1571–1580. https://doi.org/10.1109/CVPR46437.2021.00162 |
| [66] | Z. Chen, B. Zhong, G. Li, S. Zhang, R. Ji, Siamese box adaptive network for visual tracking, in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2020), 6668–6677. https://doi.org/10.1109/CVPR42600.2020.00670 |
| [67] | Y. Guo, H. Li, L. Zhang, L. Zhang, K. Deng, F. Porikli, SiamCAR: Siamese fully convolutional classification and regression for visual tracking, in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2020), 1176–1185. https://doi.org/10.1109/CVPR42600.2020.00630 |
| [68] | D. Xing, N. Evangeliou, A. Tsoukalas, A. Tzes, Siamese transformer pyramid networks for real-time UAV tracking, in IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), (2022), 1898–1907. https://doi.org/10.1109/WACV51458.2022.00196 |













Figures(14) / Tables(4)
Huanyu Wu, Yingpin Chen, Changhui Wu, Ronghuan Zhang, Kaiwei Chen. A multi-scale cyclic-shift window Transformer object tracker based on fast Fourier transform[J]. Electronic Research Archive, 2025, 33(6): 3638-3672. doi: 10.3934/era.2025162







 DownLoad:
DownLoad: