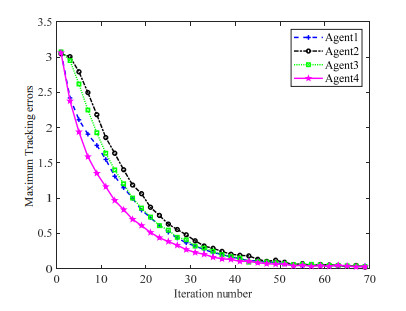
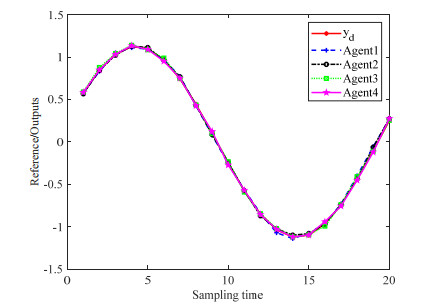
This article studies a distributed data-driven iterative learning control (ILC) strategy based on the identified input–output coupled parameters (IOCPs) to address the consensus trajectory tracking problem of discrete time-varying multi-agent systems (MASs). First, by leveraging the repeatability of the control system, a special learning scheme is designed by using system input and output data to identify the unknown IOCPs. Then the reciprocal of the identified IOCPs is selected as the learning gain to construct the ILC law of the MASs. Second, the case of measurement noise in the MASs is considered, where the maximum allowable control deviation is incorporated into the learning mechanism for identification of the IOCPs, thereby minimizing adverse effects of the noise on the learning scheme's performance and bolstering robustness. Finally, three numerical simulations are employed to validate the effectiveness of the designed IOCP identification method and iterative learning control strategy.
Citation: Duhui Chang, Yan Geng. Distributed data-driven iterative learning control for multi-agent systems with unknown input-output coupled parameters[J]. Electronic Research Archive, 2025, 33(2): 867-889. doi: 10.3934/era.2025039
This article studies a distributed data-driven iterative learning control (ILC) strategy based on the identified input–output coupled parameters (IOCPs) to address the consensus trajectory tracking problem of discrete time-varying multi-agent systems (MASs). First, by leveraging the repeatability of the control system, a special learning scheme is designed by using system input and output data to identify the unknown IOCPs. Then the reciprocal of the identified IOCPs is selected as the learning gain to construct the ILC law of the MASs. Second, the case of measurement noise in the MASs is considered, where the maximum allowable control deviation is incorporated into the learning mechanism for identification of the IOCPs, thereby minimizing adverse effects of the noise on the learning scheme's performance and bolstering robustness. Finally, three numerical simulations are employed to validate the effectiveness of the designed IOCP identification method and iterative learning control strategy.

| [1] |
S. Arimoto, S. Kawamura, F. Miyazaki, Bettering operation of robots by learning, J. Rob. Syst., 1 (1984), 123–140. https://doi.org/10.1002/rob.4620010203 doi: 10.1002/rob.4620010203

|
| [2] |
J. Huang, W. Wang, X. Su, Adaptive iterative learning control of multiple autonomous vehicles with a time-varying reference under actuator faults, IEEE Trans. Neural Networks Learn. Syst., 32 (2021), 5512–5525. https://doi.org/10.1109/TNNLS.2021.3069209 doi: 10.1109/TNNLS.2021.3069209
|
| [3] |
S. Saab, D. Shen, M. Orabi, D. Kors, R. Jaafar, Iterative learning control: Practical implementation and automation, IEEE Trans. Ind. Electron., 69 (2022), 1858–1866. https://doi.org/10.1109/TIE.2021.3063866 doi: 10.1109/TIE.2021.3063866
|
| [4] |
L. Zhang, W. Chen, J. Liu, C. Wen, A robust adaptive iterative learning control for trajectory tracking of permanent-magnet spherical actuator, IEEE Trans. Ind. Electron., 63 (2015), 291–301. https://doi.org/10.1109/TIE.2015.2464186 doi: 10.1109/TIE.2015.2464186
|
| [5] |
D. Yang, K. Lee, H. Ahn, J. H. Lee, Experimental application of a quadratic optimal iterative learning control method for control of wafer temperature uniformity in rapid thermal processing, IEEE Trans. Semicond., 16 (2003), 36–44. https://doi.org/10.1109/TSM.2002.807740 doi: 10.1109/TSM.2002.807740
|
| [6] |
M. Zhou, J. Wang, D. Shen, Iterative learning control for continuous-time multi-agent differential inclusion systems with full learnability, Chaos, Solitons Fractals, 174 (2023), 113895. https://doi.org/10.1016/j.chaos.2023.113895 doi: 10.1016/j.chaos.2023.113895
|
| [7] |
M. Naserian, A. Ramazani, A. Khaki-Sedigh, A. Moarefianpour, Fast terminal sliding mode control for a nonlinear multi-agent robot system with disturbance, Syst. Sci. Control Eng., 8 (2020), 328–338. https://doi.org/10.1080/21642583.2020.1764408 doi: 10.1080/21642583.2020.1764408
|
| [8] |
N. Pavlov, A. Petrochenkov, A. Romodin, A multi-agent approach for modeling power-supply systems with MicroGrid, Russ. Electr. Eng., 92 (2021), 637–643. https://doi.org/10.3103/S1068371221110110 doi: 10.3103/S1068371221110110
|
| [9] |
Y. Zhang, Y. Zhou, H. Lu, H. Fujita, Cooperative multi-agent actor–critic control of traffic network flow based on edge computing, Future Gener. Comput. Syst., 123 (2021), 128–141. https://doi.org/10.1016/j.future.2021.04.018 doi: 10.1016/j.future.2021.04.018
|
| [10] |
Y. Tian, Y. Chang, F. H. Arias, C. Nieto-Granda, J. P. How, L. Carlone, Kimera-multi: Robust, distributed, densemetric-semantic SLAM for multi-robot systems, IEEE Trans. Rob., 38 (2022), 2022–2038. https://doi.org/10.1109/TRO.2021.3137751 doi: 10.1109/TRO.2021.3137751
|
| [11] |
P. Wang, M. Govindarasu, Multi-agent based attack resilient system integrity protection for smart grid, IEEE Trans. Smart Grid, 11 (2020), 3447–3456. https://doi.org/10.1109/TSG.2020.2970755 doi: 10.1109/TSG.2020.2970755
|
| [12] | H. Ahn, Y. Chen, Iterative learning control for multi-agent formation, in 2009 Institute of Chemistry Chinese Academy of Sciences-Society of Instrument and Control Engineers, IEEE, (2009), 3111–3116. |
| [13] |
D. Meng, Y. Jia, Formation control for multi‐agent systems through an iterative learning design approach, Int. J. Robust Nonlinear Control, 24 (2014), 340–361. https://doi.org/10.1002/rnc.2890 doi: 10.1002/rnc.2890
|
| [14] |
X. Dai, C. Wang, S. Tian, Q. Huang, Consensus control via iterative learning for distributed parameter models multi-agent systems with time-delay, J. Franklin Inst., 356 (2019), 5240–5259. https://doi.org/10.1016/j.jfranklin.2019.05.015 doi: 10.1016/j.jfranklin.2019.05.015
|
| [15] |
Y. Chen, J. Sun, Distributed optimal control for multi-agent systems with obstacle avoidance, Neurocomputing, 173 (2016), 2014–2021. https://doi.org/10.1016/j.neucom.2015.08.085 doi: 10.1016/j.neucom.2015.08.085
|
| [16] |
Z. Hou, S. Jin, A novel data-driven control approach for a class of discrete-time nonlinear systems, IEEE Trans. Control Syst. Technol., 19 (2010), 1549–1558. https://doi.org/10.1109/TCST.2010.2093136 doi: 10.1109/TCST.2010.2093136
|
| [17] |
X. Bu, Q. Yu, Z. Hou, W. Qian, Model free adaptive iterative learning consensus tracking control for a class of nonlinear multi-agent systems, IEEE Trans. Syst. Man Cybern.: Syst., 49 (2017), 677–686. https://doi.org/10.1109/TSMC.2017.2734799 doi: 10.1109/TSMC.2017.2734799
|
| [18] |
C. Liu, X. Ruan, Input-output‐driven gain‐adaptive iterative learning control for linear discrete‐time‐invariant systems, Int. J. Robust Nonlinear Control, 31 (2021), 8551–8568. https://doi.org/10.1002/rnc.5753 doi: 10.1002/rnc.5753
|
| [19] |
Y. Geng, S. Wang, X. Ruan, The convergence of data-driven optimal iterative learning control for linear multi-phase batch processes, Mathematics, 10 (2022), 2304. https://doi.org/10.3390/math10132304 doi: 10.3390/math10132304
|
| [20] |
N. Lin, R. Chi, B. Huang, Event-triggered ILC for optimal consensus at specified data points of heterogeneous networked agents with switching topologies, IEEE Trans. Cybern., 52 (2021), 8951–8961. https://doi.org/10.1109/TCYB.2021.3054421 doi: 10.1109/TCYB.2021.3054421
|
| [21] |
Y. Zhang, J. Liu, X. Ruan, Iterative learning control for uncertain nonlinear networked control systems with random packet dropout, Int. J. Robust Nonlinear Control, 29 (2019), 3529–3546. https://doi.org/10.1002/rnc.4568 doi: 10.1002/rnc.4568
|
| [22] |
J. Liu, W. Chen, X. Ruan, Y. Zheng, Data‐based iterative learning mechanism for unknown input‐output coupling parameters/matrices, Int. J. Robust Nonlinear Control, 30 (2020), 1275–1297. https://doi.org/10.1002/rnc.4827 doi: 10.1002/rnc.4827
|
| [23] |
A. Hock, A. Schoellig, Distributed iterative learning control for multi-agent systems: Theoretic developments and application to formation flying, Auton. Robot., 43 (2019), 1989–2010. https://doi.org/10.1007/s10514-019-09845-4 doi: 10.1007/s10514-019-09845-4
|
| [24] |
P. Pakshin, A. Koposov, J. Emelianova, Iterative learning control of a multiagent system under random perturbations, Autom. Remote Control, 81 (2020), 483–502. https://doi.org/10.1134/S0005117920030078 doi: 10.1134/S0005117920030078
|
| [25] | G. Ortega, F. Muñoz, E. Quesada, L. R. Garcia, P. Ordaz, Implementation of leader-follower linear consensus algorithm for coordination of multiple aircrafts, in 2015 Workshop on Research, Education and Development of Unmanned Aerial Systems (RED-UAS), IEEE, (2015), 25–32. https://doi.org/10.1109/RED-UAS.2015.7440987 |
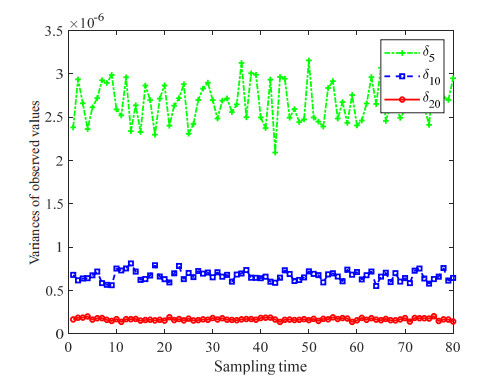
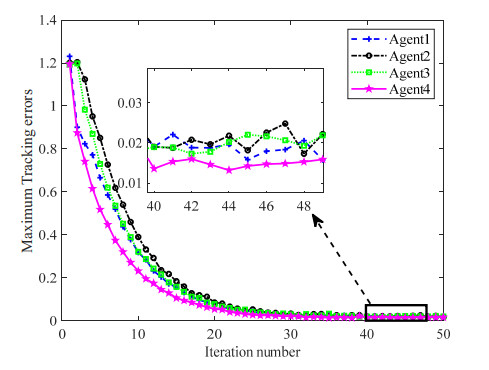
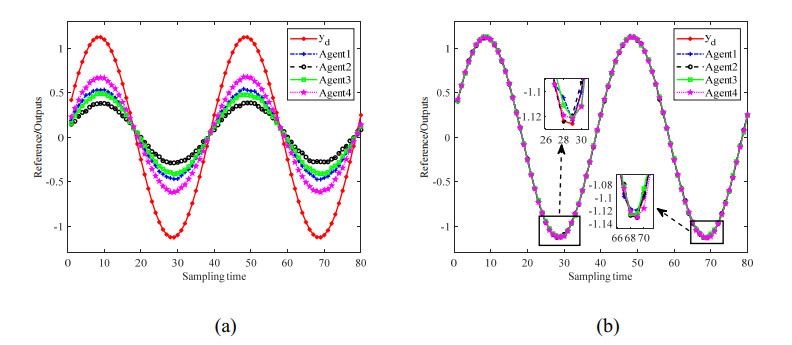
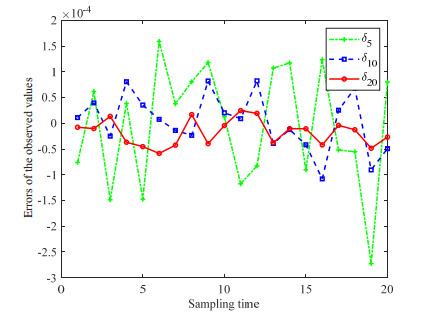
Figures(10)
Duhui Chang, Yan Geng. Distributed data-driven iterative learning control for multi-agent systems with unknown input-output coupled parameters[J]. Electronic Research Archive, 2025, 33(2): 867-889. doi: 10.3934/era.2025039







 DownLoad:
DownLoad: