Weapon target assignment (WTA) is a typical problem in the command and control of modern warfare. Despite the significance of the problem, traditional algorithms still have shortcomings in terms of efficiency, solution quality, and generalization. This paper presents a novel multi-objective evolutionary optimization algorithm (MOEA) that integrates a deep Q-network (DQN)-based adaptive mutation operator and a greedy-based crossover operator, designed to enhance the solution quality for the multi-objective WTA (MO-WTA). Our approach (NSGA-DRL) evolves NSGA-II by embedding these operators to strike a balance between exploration and exploitation. The DQN-based adaptive mutation operator is developed for predicting high-quality solutions, thereby improving the exploration process and maintaining diversity within the population. In parallel, the greedy-based crossover operator employs domain knowledge to minimize ineffective searches, focusing on exploitation and expediting convergence. Ablation studies revealed that our proposed operators significantly boost the algorithm performance. In particular, the DQN mutation operator shows its predictive effectiveness in identifying candidate solutions. The proposed NSGA-DRL outperforms state-and-art MOEAs in solving MO-WTA problems by generating high-quality solutions.
Citation: Shiqi Zou, Xiaoping Shi, Shenmin Song. MOEA with adaptive operator based on reinforcement learning for weapon target assignment[J]. Electronic Research Archive, 2024, 32(3): 1498-1532. doi: 10.3934/era.2024069
Weapon target assignment (WTA) is a typical problem in the command and control of modern warfare. Despite the significance of the problem, traditional algorithms still have shortcomings in terms of efficiency, solution quality, and generalization. This paper presents a novel multi-objective evolutionary optimization algorithm (MOEA) that integrates a deep Q-network (DQN)-based adaptive mutation operator and a greedy-based crossover operator, designed to enhance the solution quality for the multi-objective WTA (MO-WTA). Our approach (NSGA-DRL) evolves NSGA-II by embedding these operators to strike a balance between exploration and exploitation. The DQN-based adaptive mutation operator is developed for predicting high-quality solutions, thereby improving the exploration process and maintaining diversity within the population. In parallel, the greedy-based crossover operator employs domain knowledge to minimize ineffective searches, focusing on exploitation and expediting convergence. Ablation studies revealed that our proposed operators significantly boost the algorithm performance. In particular, the DQN mutation operator shows its predictive effectiveness in identifying candidate solutions. The proposed NSGA-DRL outperforms state-and-art MOEAs in solving MO-WTA problems by generating high-quality solutions.

| [1] | R. A. Murphey, Target-Based Weapon Target Assignment Problems, Springer US, 2000. |
| [2] |
R. K. Ahuja, A. Kumar, K. C. Jha, J. B. Orlin, Exact and heuristic algorithms for the weapon-target assignment problem, Oper. Res., 55 (2007), 1136–1146. https://doi.org/10.1287/opre.1070.0440 doi: 10.1287/opre.1070.0440

|
| [3] |
Y. Lu, D. Z. Chen, A new exact algorithm for the weapon-target assignment problem, Omega, 98 (2021), 102138. https://doi.org/10.1016/j.omega.2019.102138 doi: 10.1016/j.omega.2019.102138
|
| [4] |
C. Leboucher, H. Shin, S. Le Ménec, A. Tsourdos, A. Kotenkoff, P. Siarry, et al., Novel evolutionary game based multi-objective optimisation for dynamic weapon target assignment, IFAC Proc. Vol., 47 (2014), 3936–3941. https://doi.org/10.3182/20140824-6-ZA-1003.02150 doi: 10.3182/20140824-6-ZA-1003.02150
|
| [5] |
B. Xin, J. Chen, Z. Peng, L. Dou, J. Zhang, An efficient rule-based constructive heuristic to solve dynamic weapon-target assignment problem, IEEE Trans. Syst. Man Cybern. Part A, 41 (2010), 598–606. https://doi.org/10.1109/TSMCA.2010.2089511 doi: 10.1109/TSMCA.2010.2089511
|
| [6] |
Z. J. Lee, C. Y. Lee, S. F. Su, An immunity-based ant colony optimization algorithm for solving weapon–target assignment problem, Appl. Soft Comput., 2 (2002), 39–47. https://doi.org/10.1016/S1568-4946(02)00027-3 doi: 10.1016/S1568-4946(02)00027-3
|
| [7] | X. Li, D. Zhou, Q. Pan, Y. Tang, J. Huang, Weapon-target assignment problem by multiobjective evolutionary algorithm based on decomposition, Complexity, 2018 (2018). https://doi.org/10.1155/2018/8623051 |
| [8] |
T. Chang, D. Kong, N. Hao, K. Xu, G. Yang, Solving the dynamic weapon target assignment problem by an improved artificial bee colony algorithm with heuristic factor initialization, Appl. Soft Comput., 70 (2018), 845–863. https://doi.org/10.1016/j.asoc.2018.06.014 doi: 10.1016/j.asoc.2018.06.014
|
| [9] |
Y. Wang, B. Xin, J. Chen, An adaptive memetic algorithm for the joint allocation of heterogeneous stochastic resources, IEEE Trans. Cybern., 52 (2021), 11526–11538. https://doi.org/10.1109/TCYB.2021.3087363 doi: 10.1109/TCYB.2021.3087363
|
| [10] |
L. Zhao, Z. An, B. Wang, Y. Zhang, Y. Hu, A hybrid multi-objective bi-level interactive fuzzy programming method for solving ecm-dwta problem, Complex Intell. Syst., 8 (2022), 4811–4829. https://doi.org/10.1007/s40747-022-00730-9 doi: 10.1007/s40747-022-00730-9
|
| [11] |
X. Chang, J. Shi, Z. Luo, Y. Liu, Adaptive large neighborhood search algorithm for multi-stage weapon target assignment problem, Comput. Ind. Eng., 181 (2023), 109303. https://doi.org/10.1016/j.cie.2023.109303 doi: 10.1016/j.cie.2023.109303
|
| [12] |
Q. Zhang, H. Li, MOEA/D: A multiobjective evolutionary algorithm based on decomposition, IEEE Trans. Evol. Comput., 11 (2007), 712–731. https://doi.org/10.1109/TEVC.2007.892759 doi: 10.1109/TEVC.2007.892759
|
| [13] |
M. Behzadian, S. K. Otaghsara, M. Yazdani, J. Ignatius, A state-of the-art survey of TOPSIS applications, Expert Syst. Appl., 39 (2012), 13051–13069. https://doi.org/10.1016/j.eswa.2012.05.056 doi: 10.1016/j.eswa.2012.05.056
|
| [14] | Q. Cheng, D. Chen, J. Gong, Weapon-target assignment of ballistic missiles based on q-learning and genetic algorithm, in 2021 IEEE International Conference on Unmanned Systems (ICUS), (2021), 908–912. https://doi.org/10.1109/ICUS52573.2021.9641190 |
| [15] |
H. Mouton, H. L. Roux, J. Roodt, Applying reinforcement learning to the weapon assignment problem in air defence, Sci. Militaria S. Afr. J. Military Stud., 39 (2011), 99–116. https://doi.org/10.5787/39-2-115 doi: 10.5787/39-2-115
|
| [16] |
F. Meng, K. Tian, C. Wu, Deep reinforcement learning-based radar network target assignment, IEEE Sens. J., 21 (2021), 16315–16327. https://doi.org/10.1109/JSEN.2021.3074826 doi: 10.1109/JSEN.2021.3074826
|
| [17] |
S. Li, X. He, X. Xu, T. Zhao, C. Song, J. Li, Weapon-target assignment strategy in joint combat decision-making based on multi-head deep reinforcement learning, IEEE Access, 11 (2023), 113740–113751. https://doi.org/10.1109/ACCESS.2023.3324193 doi: 10.1109/ACCESS.2023.3324193
|
| [18] | C. Li, B. Xin, Y. He, D. Wang, Y. Li, Dynamic weapon target assignment based on deep q network, in 2023 42nd Chinese Control Conference (CCC), (2023), 1773–1778. https://doi.org/10.23919/CCC58697.2023.10240428 |
| [19] |
T. Wang, L. Fu, Z. Wei, Y. Zhou, S. Gao, Unmanned ground weapon target assignment based on deep q-learning network with an improved multi-objective artificial bee colony algorithm, Eng. Appl. Artif. Intell., 117 (2023), 105612. https://doi.org/10.1016/j.engappai.2022.105612 doi: 10.1016/j.engappai.2022.105612
|
| [20] |
K. Deb, A. Pratap, S. Agarwal, T. Meyarivan, A fast and elitist multiobjective genetic algorithm: NSGA-II, IEEE Trans. Evol. Comput., 6 (2002), 182–197. https://doi.org/10.1109/4235.996017 doi: 10.1109/4235.996017
|
| [21] |
H. Cai, J. Liu, Y. Chen, H. Wang, Survey of the research on dynamic weapon-target assignment problem, J. Syst. Eng. Electron., 17 (2006), 559–565. https://doi.org/10.1016/S1004-4132(06)60097-2 doi: 10.1016/S1004-4132(06)60097-2
|
| [22] |
A. Kline, D. Ahner, R. Hill, The weapon-target assignment problem, Comput. Oper. Res., 105 (2019), 226–236. https://doi.org/10.1016/j.cor.2018.10.015 doi: 10.1016/j.cor.2018.10.015
|
| [23] | R. A. Murphey, An Approximate Algorithm For A Weapon Target Assignment Stochastic Program, Springer US, 2000. |
| [24] |
O. Karasakal, Air defense missile-target allocation models for a naval task group, Comput. Oper. Res., 35 (2008), 1759–1770. https://doi.org/10.1016/j.cor.2006.09.011 doi: 10.1016/j.cor.2006.09.011
|
| [25] |
M. S. Hughes, B. J. Lunday, The weapon target assignment problem: Rational inference of adversary target utility valuations from observed solutions, Omega, 107 (2022), 102562. https://doi.org/10.1016/j.omega.2021.102562 doi: 10.1016/j.omega.2021.102562
|
| [26] |
Z. J. Lee, S. F. Su, C. Y. Lee, Efficiently solving general weapon-target assignment problem by genetic algorithms with greedy eugenics, IEEE Trans. Syst. Man Cybern. Part B, 33 (2003), 113–121. https://doi.org/10.1109/TSMCB.2003.808174 doi: 10.1109/TSMCB.2003.808174
|
| [27] |
A. M. Madni, M. Andrecut, Efficient heuristic approach to the weapon-target assignment problem, J. Aerosp. Comput. Inf. Commun., 6 (2009), 405–414. https://doi.org/10.2514/1.34254 doi: 10.2514/1.34254
|
| [28] |
Z. R. Bogdanowicz, A. Tolano, K. Patel, N. P. Coleman, Optimization of weapon–target pairings based on kill probabilities, IEEE Trans. Cybern., 43 (2012), 1835–1844. https://doi.org/10.1109/TSMCB.2012.2231673 doi: 10.1109/TSMCB.2012.2231673
|
| [29] |
H. Liang, F. Kang, Adaptive chaos parallel clonal selection algorithm for objective optimization in WTA application, Optik, 127 (2016), 3459–3465. https://doi.org/10.1016/j.ijleo.2015.12.122 doi: 10.1016/j.ijleo.2015.12.122
|
| [30] |
Z. Li, Y. Chang, Y. Kou, H. Yang, A. Xu, Y. Li, Approach to WTA in air combat using IAFSA-IHS algorithm, J. Syst. Eng. Electron., 29 (2018), 519–529. https://doi.org/10.21629/JSEE.2018.03.09 doi: 10.21629/JSEE.2018.03.09
|
| [31] |
M. Cao, W. Fang, Swarm intelligence algorithms for weapon-target assignment in a multilayer defense scenario: A comparative study, Symmetry, 12 (2020), 824. https://doi.org/10.3390/sym12050824 doi: 10.3390/sym12050824
|
| [32] | J. Li, J. Chen, B. Xin, L. Dou, Solving multi-objective multi-stage weapon target assignment problem via adaptive NSGA-II and adaptive MOEA/D: A comparison study, in 2015 IEEE Congress on Evolutionary Computation (CEC), (2015), 3132–3139. https://doi.org/10.1109/CEC.2015.7257280 |
| [33] |
W. Xu, C. Chen, S. Ding, P. M. Pardalos, A bi-objective dynamic collaborative task assignment under uncertainty using modified MOEA/D with heuristic initialization, Expert Syst. Appl., 140 (2020), 112844. https://doi.org/10.1016/j.eswa.2019.112844 doi: 10.1016/j.eswa.2019.112844
|
| [34] |
Y. Zhao, J. Liu, J. Jiang, Z. Zhen, Shuffled frog leaping algorithm with non-dominated sorting for dynamic weapon-target assignment, J. Syst. Eng. Electron., 34 (2023), 1007–1019. https://doi.org/10.23919/JSEE.2023.000102 doi: 10.23919/JSEE.2023.000102
|
| [35] | R. Durgut, M. E. Aydin, I. Atli, Adaptive operator selection with reinforcement learning, Inf. Sci., 581 (2021), 773–790. https://doi.org/10.1016/j.ins.2021.10.025 https://doi.org/10.1007/978-3-030-85672-4 https://doi.org/10.1007/978-3-030-85672-4_3 |
| [36] |
Y. Tian, X. Li, H. Ma, X. Zhang, K. C. Tan, Y. Jin, Deep reinforcement learning based adaptive operator selection for evolutionary multi-objective optimization, IEEE Trans. Emerging Top. Comput. Intell., 7 (2023), 1051–1064. https://doi.org/10.1109/TETCI.2022.3146882 doi: 10.1109/TETCI.2022.3146882
|
| [37] |
M. A. Wiering, M. V. Otterlo, Reinforcement learning, Adapt. Learn. Optim., 12 (2012), 729. https://doi.org/10.1007/978-3-642-27645-3 doi: 10.1007/978-3-642-27645-3
|
| [38] | V. Mnih, K. Kavukcuoglu, D. Silver, A. Graves, I. Antonoglou, D. Wierstra, et al., Playing atari with deep reinforcement learning, preprint, arXiv: 1312.5602. https://doi.org/10.48550/arXiv.1312.5602 |
| [39] | D. P. Kingma, J. Ba, Adam: A method for stochastic optimization, preprint, arXiv: 1412.6980. https://doi.org/10.48550/arXiv.1412.6980 |
| [40] | R. Girshick, Fast R-CNN, in Proceedings of the IEEE international conference on computer vision, (2015), 1440–1448. https://doi.org/10.1109/ICCV.2015.169 |
| [41] | T. Blickle, Tournament selection, Evol. Comput., 1 (2000), 181–186. https://doi.org/10.1887/0750308958 |
| [42] |
X. Zhang, Y. Tian, R. Cheng, Y. Jin, An efficient approach to nondominated sorting for evolutionary multiobjective optimization, IEEE Trans. Evol. Comput., 19 (2014), 201–213. https://doi.org/10.1109/TEVC.2014.2308305 doi: 10.1109/TEVC.2014.2308305
|
| [43] |
F. Ming, W. Gong, H. Zhen, S. Li, L. Wang, Z. Liao, A simple two-stage evolutionary algorithm for constrained multi-objective optimization, Knowl. Based Syst., 228 (2021), 107263. https://doi.org/10.1016/j.knosys.2021.107263 doi: 10.1016/j.knosys.2021.107263
|
| [44] | A. Panichella, An improved pareto front modeling algorithm for large-scale many-objective optimization, in Proceedings of the Genetic and Evolutionary Computation Conference, (2022), 565–573. https://doi.org/10.1145/3512290.3528732 |
| [45] |
A. P. Guerreiro, C. M. Fonseca, L. Paquete, The hypervolume indicator: {C}omputational problems and algorithms, ACM Comput. Surv., 54 (2021), 1–42. https://doi.org/10.1145/3453474 doi: 10.1145/3453474
|
| [46] | A. Freddi, M. Salmon, Introduction to the Taguchi Method, Springer International Publishing, 2019. |
| [47] | W. K. Mashwani, A. Salhi, M. A. Jan, R. A. Khanum, M. Sulaiman, Impact analysis of crossovers in a multi-objective evolutionary algorithm, Sci. Int., 27 (2015), 4943–4956. |
| [48] |
X. Shi, S. Zou, S. Song, R. Guo, A multi-objective sparse evolutionary framework for large-scale weapon target assignment based on a reward strategy, J. Intell. Fuzzy Syst., 40 (2021), 10043–10061. https://doi.org/10.3233/JIFS-202679 doi: 10.3233/JIFS-202679
|
| [49] |
S. Zou, X. Shi, S. Song, A multi-objective optimization framework with rule-based initialization for multi-stage missile target allocation, Math. Biosci. Eng., 20 (2023), 7088–7112. https://doi.org/10.3934/mbe.2023306 doi: 10.3934/mbe.2023306
|
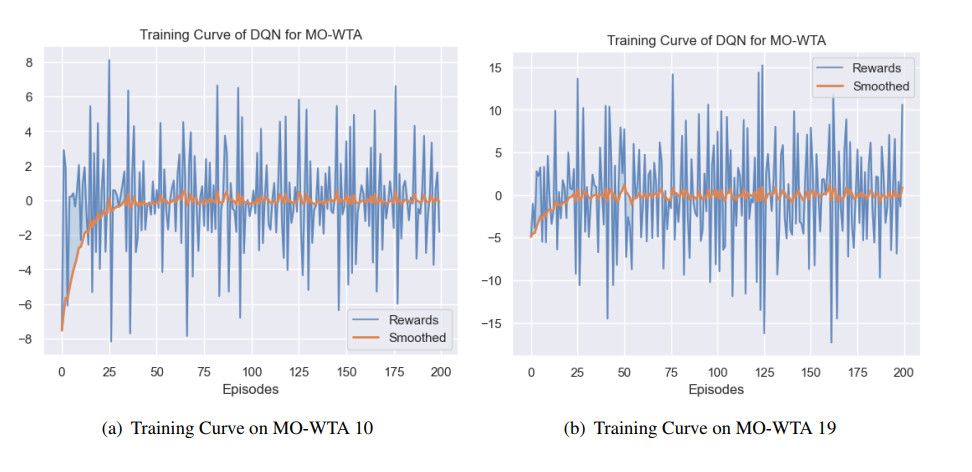
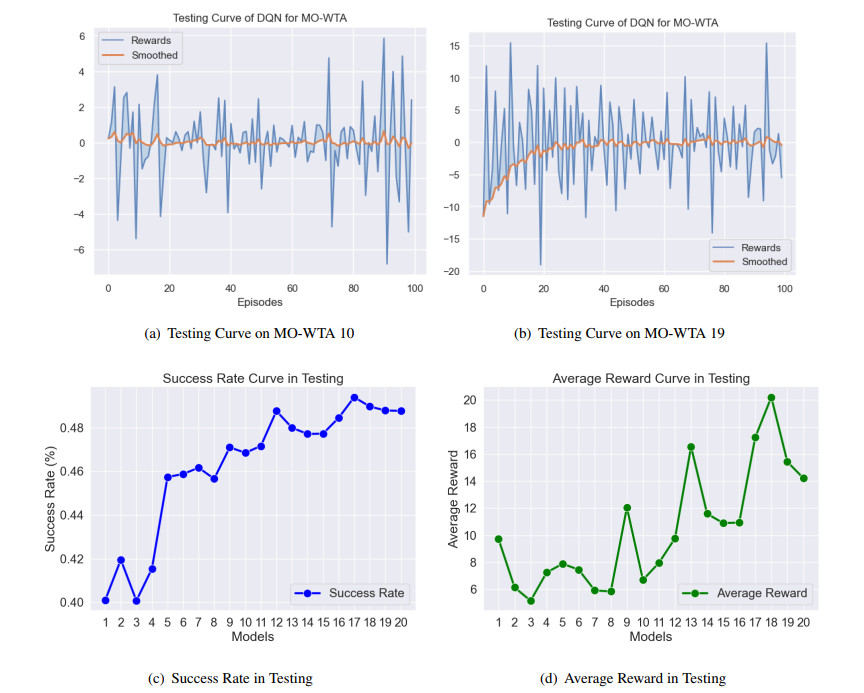
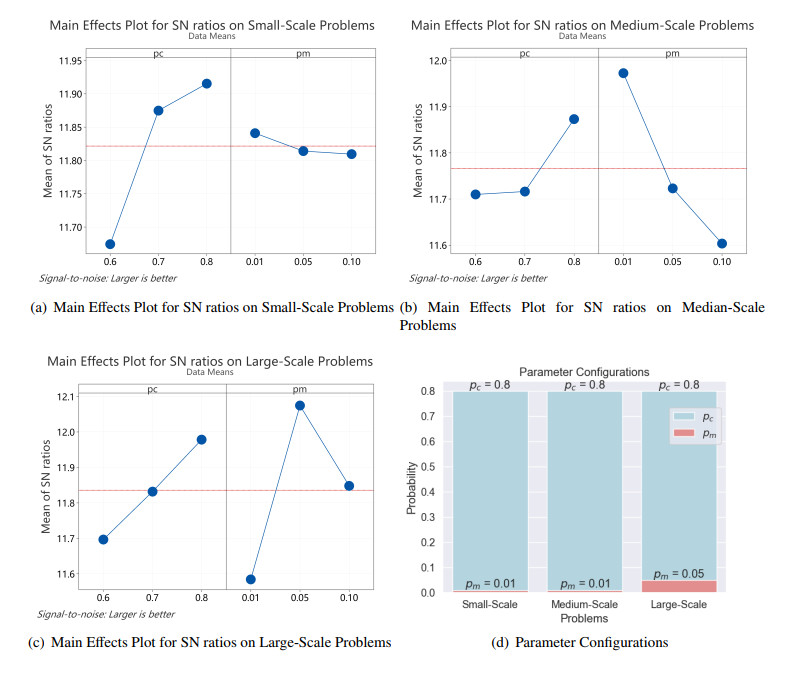
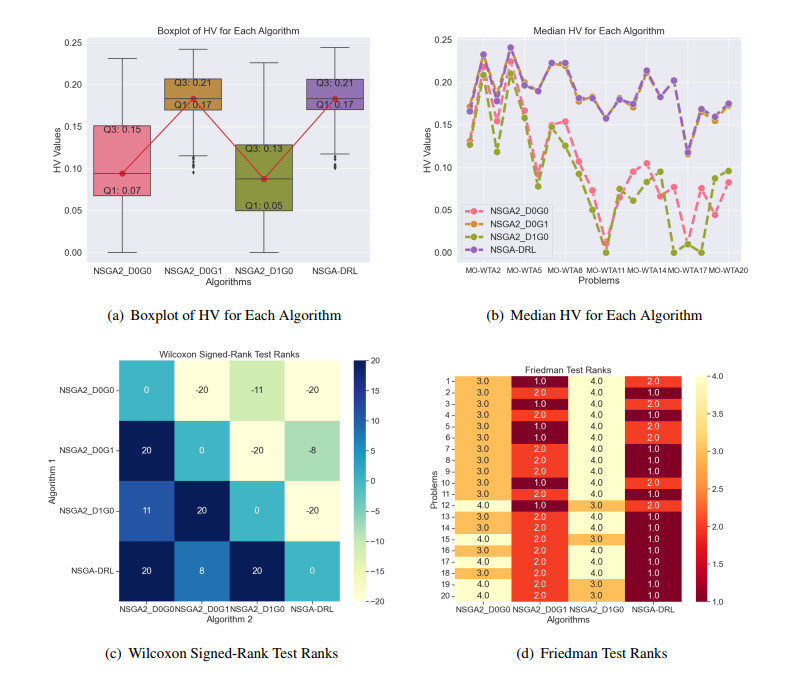
Figures(10) / Tables(6)
Shiqi Zou, Xiaoping Shi, Shenmin Song. MOEA with adaptive operator based on reinforcement learning for weapon target assignment[J]. Electronic Research Archive, 2024, 32(3): 1498-1532. doi: 10.3934/era.2024069







 DownLoad:
DownLoad: