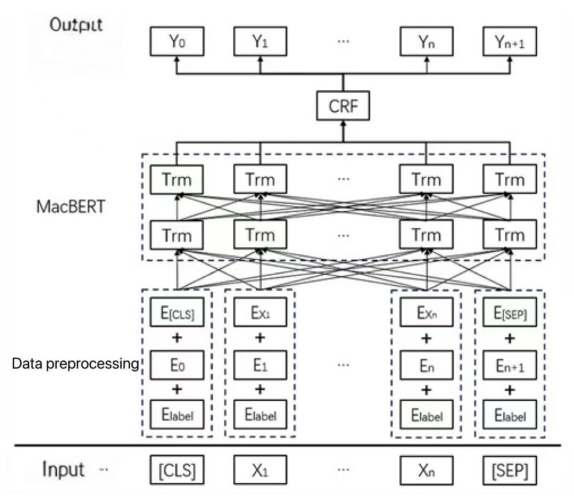
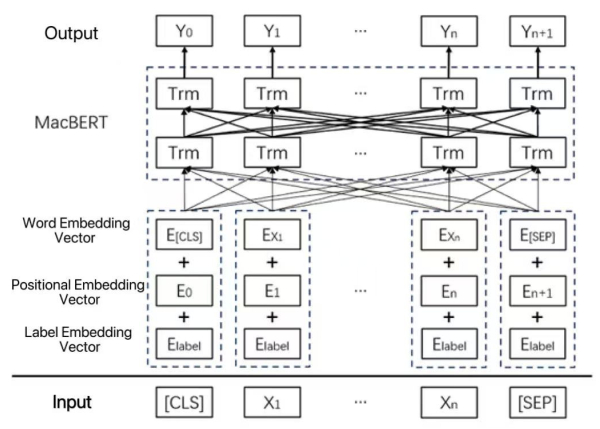
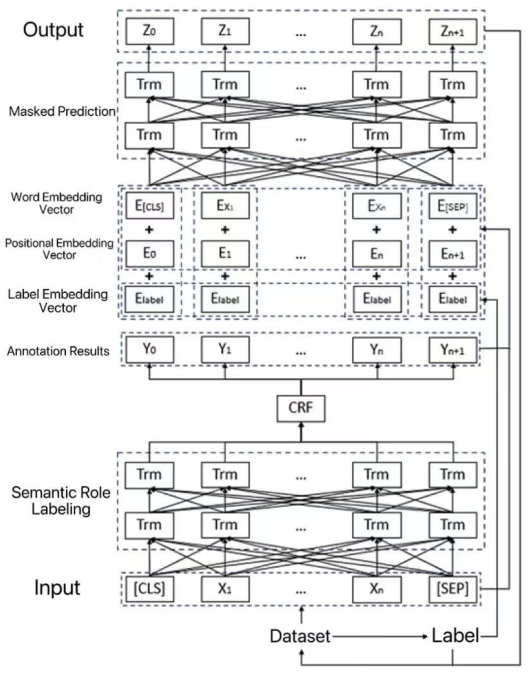
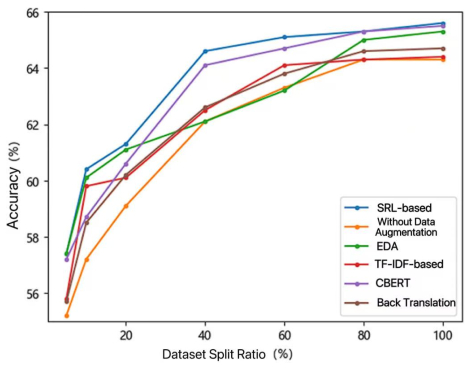
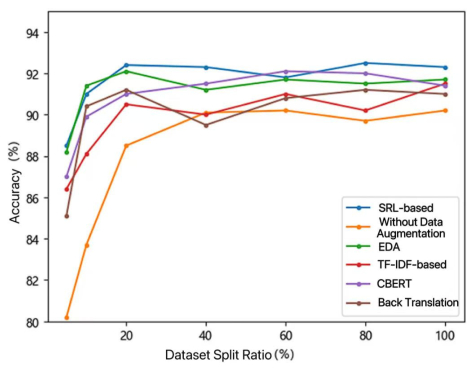
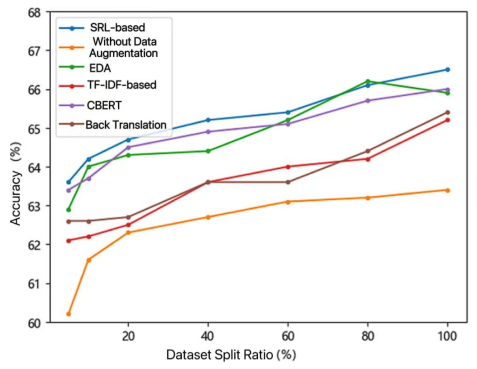
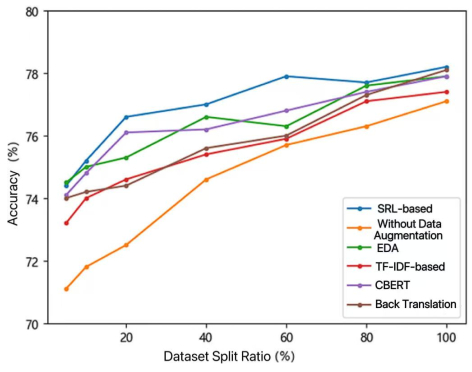
The performance of deep learning models in natural language processing (NLP) is heavily dependent on the volume and quality of training data. However, acquiring large amounts of high-quality labeled data is often costly and challenging. Text data augmentation presents a low-cost and efficient solution to expand datasets by generating diversified new samples. A critical limitation of traditional augmentation methods, such as synonym replacement and random manipulation, is the "non-core word replacement" problem. These methods often replace functionally unimportant words (e.g., prepositions, conjunctions), resulting in limited semantic variation and ineffective augmented data. To address this issue, this paper innovatively introduces semantic roles into the data augmentation process, proposing a novel semantic role-based data augmentation (SRDA) method. Our approach consists of three key components: (1) we constructed an advanced MacBERT-CRF model for semantic role labeling (SRL) that outperforms traditional architectures; (2) we developed a tailored masked prediction model with semantic role-level masking, an increased masking ratio, dynamic N-gram masking, and a novel label embedding mechanism; and (3) we demonstrated the method's effectiveness through rigorous evaluation on four distinct Chinese datasets. Experimental results demonstrated that our method consistently outperforms various traditional augmentation techniques across different data volumes and domains, significantly enhancing downstream text classification performance.
Citation: Yutong Wang, Guole Shang, Jianlin Wang, Junfang Zhao. Text data augmentation based on semantic roles[J]. Big Data and Information Analytics, 2026, 10: 81-95. doi: 10.3934/bdia.2026005
The performance of deep learning models in natural language processing (NLP) is heavily dependent on the volume and quality of training data. However, acquiring large amounts of high-quality labeled data is often costly and challenging. Text data augmentation presents a low-cost and efficient solution to expand datasets by generating diversified new samples. A critical limitation of traditional augmentation methods, such as synonym replacement and random manipulation, is the "non-core word replacement" problem. These methods often replace functionally unimportant words (e.g., prepositions, conjunctions), resulting in limited semantic variation and ineffective augmented data. To address this issue, this paper innovatively introduces semantic roles into the data augmentation process, proposing a novel semantic role-based data augmentation (SRDA) method. Our approach consists of three key components: (1) we constructed an advanced MacBERT-CRF model for semantic role labeling (SRL) that outperforms traditional architectures; (2) we developed a tailored masked prediction model with semantic role-level masking, an increased masking ratio, dynamic N-gram masking, and a novel label embedding mechanism; and (3) we demonstrated the method's effectiveness through rigorous evaluation on four distinct Chinese datasets. Experimental results demonstrated that our method consistently outperforms various traditional augmentation techniques across different data volumes and domains, significantly enhancing downstream text classification performance.

| [1] | Munappy A, Bosch J, Olsson HH, Arpteg A, Brinne B, (2019) Data management challenges for deep learning, In: 2019 45th Euromicro Conference on Software Engineering and Advanced Applications (SEAA), 140–147. https://doi.org/10.1109/SEAA.2019.00030 |
| [2] |
Li B, Hou Y, Che W, (2022) Data augmentation approaches in natural language processing: A survey. Ai Open 3: 71–90. https://doi.org/10.1016/j.aiopen.2022.03.001 doi: 10.1016/j.aiopen.2022.03.001

|
| [3] | Feng SY, Gangal V, Wei J, Chandar S, Vosoughi S, Mitamura T, et al. (2021) A survey of data augmentation approaches for NLP, In: Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, 968–988. https://aclanthology.org/2021.findings-acl.84 |
| [4] | Sennrich R, Haddow B, Birch A, (2016) Improving neural machine translation models with Monolingual data, In: Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, 86–96. |
| [5] | Kobayashi S, (2018) Contextual augmentation: Data augmentation by words with paradigmatic relations, In: Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 452–457. https://doi.org/10.18653/v1/N18-2072 |
| [6] | Wei J, Zou K, (2019) EDA: Easy data augmentation techniques for boosting performance on text classification tasks, In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), 6382–6388. https://doi.org/10.18653/v1/D19-1670 |
| [7] | Wu X, Lv S, Zang L, Han J, Hu S, (2019) Conditional bert contextual augmentation, In: International Conference on Computational Science, 84–95. https://doi.org/10.1007/978-3-030-22747-0_7 |
| [8] | Xie Q, Dai Z, Hovy E, Luong T, Le Q, (2020) Unsupervised data augmentation for consistency training. Adv Neural Inf Process Syst 33: 6256–6268. |
| [9] | Cui Y, Che W, Liu T, Qin B, Wang S, Hu G, (2020) Revisiting pre-trained models for Chinese natural language processing, In: Findings of the Association for Computational Linguistics: EMNLP 2020, 657–668. https://doi.org/10.18653/v1/2020.findings-emnlp.58 |
| [10] |
Gildea D, Jurafsky D, (2002) Automatic labeling of semantic roles. Comput Linguist 28: 245–288. https://doi.org/10.1162/089120102760275983 doi: 10.1162/089120102760275983
|
| [11] | Zhang H, (2018) Research on Semantic Role Labeling Based on Bi-LSTM-CRF, Master's thesis, Beijing Institute of Technology. |
| [12] | Wang Y, Wan F, Ma N, (2020) Chinese semantic role labeling integrating multi-level features. CAAI Trans Intell Syst 15: 107–113. |
| [13] | Wang XH, Li R, Wang ZQ, Chai QH, Han XQ, (2022) Syntax-aware Chinese frame semantic role labeling based on self-attention. J Chin Inf Process 36: 38–44. |
| [14] | Devlin J, Chang MW, Lee K, Toutanova K, (2019) BERT: Pre-training of deep bidirectional transformers for language understanding, In: Proceedings of NAACL-HLT 2019, 4171–4186. https://doi.org/10.18653/v1/N19-1423 |
| [15] | Lafferty J, McCallum A, Pereira FCN, (2001) Conditional random fields: Probabilistic models for segmenting and labeling sequence data, In: Proceedings of ICML 2001, 282–289. |
| [16] |
Palmer M, Xue N, (2009) Adding semantic roles to the Chinese Treebank. Natural Lang Eng 15: 143–172. https://doi.org/10.1017/S1351324908004902 doi: 10.1017/S1351324908004902
|
Figures(7) / Tables(11)

Yutong Wang, Guole Shang, Jianlin Wang, Junfang Zhao. Text data augmentation based on semantic roles[J]. Big Data and Information Analytics, 2026, 10: 81-95. doi: 10.3934/bdia.2026005









 DownLoad:
DownLoad: