Citation: John A. Doucette, Robin Cohen. A testbed to enable comparisons between competing approaches for computational social choice[J]. Big Data and Information Analytics, 2016, 1(4): 309-340. doi: 10.3934/bdia.2016013

| [1] | [ H. Azari, D. Parkes and L. Xia, Random Utility Theory for Social Choice, in Advances in Neural Information Processing Systems, NIPS Foundation, 2012, 126-134. |
| [2] | [ A. Balz and R. Senge, WEKA-LR:A Label Ranking Extension for WEKA, URL http://www.uni-marburg.de/fb12/kebi/research/software/labelrankdoc.pdf. |
| [3] | [ S. Bouveret, Whale3-WHich ALternative is Elected, URL http://strokes.imag.fr/whale3/. |
| [4] | [ F. Brandt, G. Chabin and C. Geist, Pnyx:A Powerful and User-friendly Tool for Preference Aggregation, in Proceedings of the 2015 International Conference on Autonomous Agents and Multiagent Systems, International Foundation for Autonomous Agents and Multiagent Systems, 2015, 1915-1916. |
| [5] | [ C.-C. Chang and C.-J. Lin, LIBSVM:a library for support vector machines, ACM Transactions on Intelligent Systems and Technology (TIST), 2(2011), 27-66. |
| [6] | [ G. Charwat and A. Pfandler, Democratix:A Declarative Approach to Winner Determination, in Algorithmic Decision Theory, Springer, 2015, 253-269. |
| [7] | [ C. Cortes and V. Vapnik, Support-vector networks, Machine Learning, 20(1995), 273-297. |
| [8] | [ J. Dean and S. Ghemawat, MapReduce:simplified data processing on large clusters, Communications of the ACM, 51(2008), 107-113. |
| [9] | [ P. Diaconis and R. L. Graham, Spearman's footrule as a measure of disarray, Journal of the Royal Statistical Society. Series B (Methodological), 262-268. |
| [10] | [ J. P. Dickerson, A. D. Procaccia and T. Sandholm, Price of fairness in kidney exchange, in Proceedings of the 2014 international conference on Autonomous agents and multi-agent systems, International Foundation for Autonomous Agents and Multiagent Systems, 2014, 1013-1020. |
| [11] | [ E. Dimitriadou, K. Hornik, F. Leisch, D. Meyer and A. Weingessel, Misc functions of the Department of Statistics (e1071), TU Wien, R package, 1(2008), 5-24. |
| [12] | [ J. A. Doucette, K. Larson and R. Cohen, Conventional machine learning for social choice, in Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, AAAI Press, 2015. |
| [13] | [ G. H. Dunteman, Principal Components Analysis, no. 69 in Quantitative Applications in the Social Sciences, Sage, 1989. |
| [14] | [ V. E. Farrugia, H. P. Martínez and G. N. Yannakakis, The preference learning toolbox, arXiv preprint arXiv:1506.01709. |
| [15] | [ M. Gebser, B. Kaufmann, R. Kaminski, M. Ostrowski, T. Schaub and M. Schneider, Potassco:The Potsdam answer set solving collection, AI Communications, 24(2011), 107-124. |
| [16] | [ M. Gelfond and V. Lifschitz, Classical negation in logic programs and disjunctive databases, New Generation Computing, 9(1991), 365-385. |
| [17] | [ J. Goldman and A. D. Procaccia, Spliddit:Unleashing fair division algorithms, ACM SIGecom Exchanges, 13(2015), 41-46. |
| [18] | [ M. Hall, E. Frank, G. Holmes, B. Pfahringer, P. Reutemann and I. H. Witten, The WEKA data mining software:an update, ACM SIGKDD explorations newsletter, 11(2009), 10-18. |
| [19] | [ L. Hatton, The T-experiments:errors in scientific software, in Quality of Numerical Software, Springer, 1997, 12-31. |
| [20] | [ L. Hatton and A. Roberts, How accurate is scientific software?, IEEE Transactions on Software Engineering, 20(1994), 785-797. |
| [21] | [ M. R. Hestenes and E. Stiefel, Methods of Conjugate Gradients for Solving Linear Systems1, Journal of Research of the National Bureau of Standards, 49. |
| [22] | [ E. Hüllermeier and J. Fürnkranz, Learning from label preferences, in Proceedings of the 14th International Conference on Discovery Science, Springer, 2011, 2-17. |
| [23] | [ T. Joachims, Optimizing search engines using clickthrough data, in Proceedings of the Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, ACM, 2002, 133-142. |
| [24] | [ T. Joachims, Training linear SVMs in linear time, in Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, ACM, 2006, 217-226. |
| [25] | [ D. Kelly and R. Sanders, The challenge of testing scientific software, in In Proceedings of the 2008 Conference for the Association for Software Testing, AST, 2008, 30-36. |
| [26] | [ M. G. Kendall, A new measure of rank correlation, Biometrika, 30(1938), 81-93. |
| [27] | [ S. Kullback and R. A. Leibler, On information and sufficiency, The Annals of Mathematical Statistics, 22(1951), 79-86. |
| [28] | [ T. Lu and C. Boutilier, Learning Mallows models with pairwise preferences, in Proceedings of the 28th International Conference on Machine Learning (ICML-11), 2011, 145-152. |
| [29] | [ T. Lu and C. Boutilier, Robust approximation and incremental elicitation in voting protocols, in Proceedings of the Twenty-First International Joint Conference on Artificial Intelligence, AAAI Press, 2011, 287-213. |
| [30] | [ R. D. Luce, Individual Choice Behavior:A Theoretical Analysis, Wiley, 1959. |
| [31] | [ C. L. Mallows, Non-null ranking models. I, Biometrika, 44(1957), 114-130. |
| [32] | [ N. Mattei and T. Walsh, Preflib:A library for preferences http://www.preflib.org, in Algorithmic Decision Theory, Springer, 2013, 259-270. |
| [33] | [ N. Matti, PrefLib-Tools:A small and lightweight set of Python tools for working with and generating data from www.PrefLib.org., URL https://github.com/nmattei/PrefLib-Tools. |
| [34] | [ R. Rifkin and A. Klautau, In defense of one-vs-all classification, The Journal of Machine Learning Research, 5(2004), 101-141. |
| [35] | [ B. Ripley and W. Venables, nnet:Feed-forward neural networks and multinomial log-linear models, R package version, 7. |
| [36] | [ P. Romanski, FSelector:Selecting attributes, Vienna:R Foundation for Statistical Computing. |
| [37] | [ C. Spearman, 'Footrule' for measuring correlation, British Journal of Psychology, 1904-1920, 2(1906), 89-108. |
| [38] | [ J. E. Stone, D. Gohara and G. Shi, OpenCL:A parallel programming standard for heterogeneous computing systems, Computing in Science & Engineering, 12(2010), 66-73. |
| [39] | [ R. C. Team, R:A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria. 2013, ISBN 3-900051-07-0, 2014. |
| [40] | [ L. Xia and V. Conitzer, Determining Possible and Necessary Winners under Common Voting Rules Given Partial Orders., in Proceedings of the Twenty-Third AAAI Conference on Artificial Intelligence, AAAI Press, 2008, 196-201. |
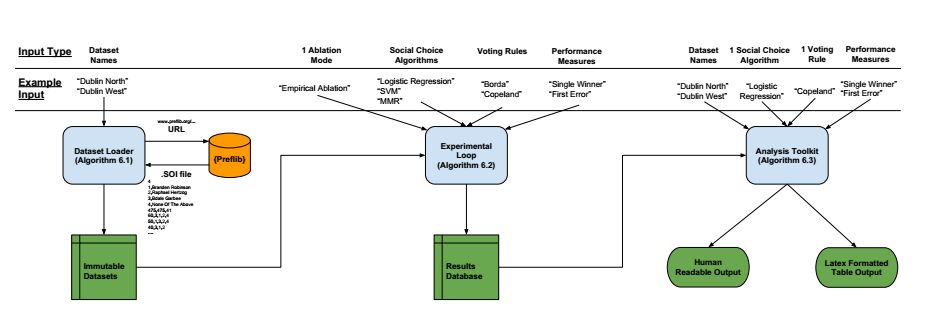
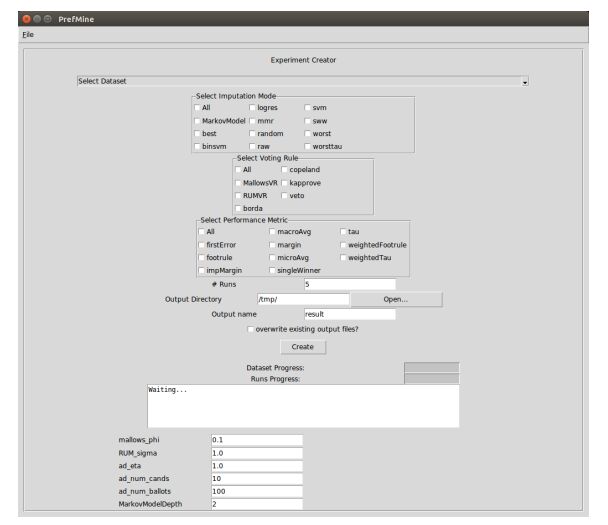
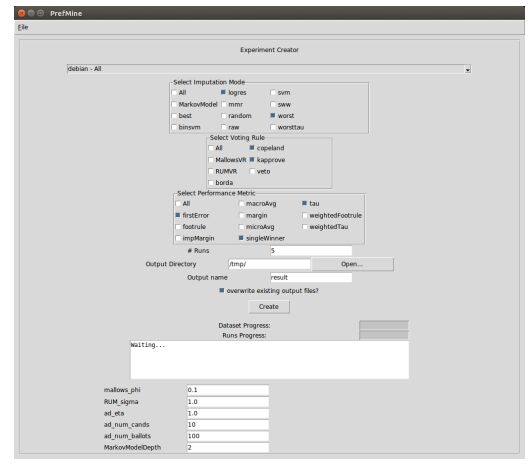

Figures(11) / Tables(4)

John A. Doucette, Robin Cohen. A testbed to enable comparisons between competing approaches for computational social choice[J]. Big Data and Information Analytics, 2016, 1(4): 309-340. doi: 10.3934/bdia.2016013









 DownLoad:
DownLoad: