Citation: Arsenio M. Fialho, Nuno Bernardes, Ananda M Chakrabarty. Exploring the anticancer potential of the bacterial protein azurin[J]. AIMS Microbiology, 2016, 2(3): 292-303. doi: 10.3934/microbiol.2016.3.292

| [1] | De Rienzo F, Gabdoulline RR, Menziani MC, et al. (2000) Blue copper proteins: a comparative analysis of their molecular interaction properties. Protein Sci 98: 1439–1454. |
| [2] |
De Rienzo F, Gabdoulline RR, Wade RC, et al. (2004) Computational approaches to structural and functional analysis of plastocyanin and other blue copper proteins. Cell Mol Life Sci 61: 1123–1142. doi: 10.1007/s00018-004-3181-5

|
| [3] |
Fialho AM, Stevens FJ, Das Gupta TK, et al. (2007) Beyond host-pathogen interactions: microbial defense strategy in the host environment. Curr Opin Biotechnol 18: 279–286. doi: 10.1016/j.copbio.2007.04.001
|
| [4] |
Stevens FJ (2008) Homology versus analogy: possible evolutionary relationship of immunoglobulins, cupredoxins, and Cu,Zn-superoxide dismutase. J Mol Recognit 21: 20–29. doi: 10.1002/jmr.861
|
| [5] |
Warren JJ, Lancaster KM, Richards JH, et al. (2012) Inner- and outer-sphere metal coordination in blue copper proteins. J Inorg Biochem 115: 119–126. doi: 10.1016/j.jinorgbio.2012.05.002
|
| [6] |
Yanagisawa S, Banfield MJ, Dennison C (2006) The role of hydrogen bonding at the active site of a cupredoxin: the Phe114Pro azurin variant. Biochemistry 45: 8812–8822. doi: 10.1021/bi0606851
|
| [7] | Cannon JG (1989) Conserved lipoproteins of pathogenic neisseria species bearing the H.8 epitope: lipid-modified azurin and H.8 outer membrane protein. Clin Microbiol Rev 2: S1–S4. |
| [8] |
Hashimoto W, Ochiai A, Hong CS, et al. (2015) Structural studies on Laz, a promiscuous anticancer Neisserial protein. Bioengineered 6: 141–148. doi: 10.1080/21655979.2015.1022303
|
| [9] |
Chaudhari A, Fialho AM, Ratner D, et al. (2006) Azurin, Plasmodium falciparum and HIV/AIDS: inhibition of parasitic and viral growth by azurin. Cell Cycle 5: 1642–1648. doi: 10.4161/cc.5.15.2992
|
| [10] |
Cruz-Gallardo, Díaz-Moreno, Díaz-Quintana A, et al. (2013) Antimalarial activity of cupredoxins: the interaction of Plasmodium merozoite surface protein 119 (MSP119) and rusticyanin. J Biol Chem 288: 20896–20907. doi: 10.1074/jbc.M113.460162
|
| [11] |
Naguleswaran A, Fialho AM, Chaudhari A, et al. (2008) Azurin-like protein blocks invasion of Toxoplasma gondii through potential interactions with parasite surface antigen SAG1. Antimicrob Agents Ch 52: 402–408. doi: 10.1128/AAC.01005-07
|
| [12] |
Škrlec K, Štrukelj B, Berlec A (2015) Non-immunoglobulin scaffolds: a focus on their targets. Trends Biotechnol 33: 408–418. doi: 10.1016/j.tibtech.2015.03.012
|
| [13] |
Yamada T, Hiraoka Y, Ikehata M, et al. (2004) Apoptosis or growth arrest: modulation of tumor suppressor p53’s specificity by bacterial redox protein azurin. Proc Natl Acad Sci USA 101: 4770–4775. doi: 10.1073/pnas.0400899101
|
| [14] |
Punj V, Bhattacharyya S, Saint-dic D, et al. (2004) Bacterial cupredoxin azurin as an inducer of apoptosis and regression in human breast cancer. Oncogene 23: 2367–2378. doi: 10.1038/sj.onc.1207376
|
| [15] |
Bernardes N, Chakrabarty AM, Fialho AM (2013) Engineering of bacterial strains and their products for cancer therapy. Appl Microbiol Biotechnol 97: 5189–5199. doi: 10.1007/s00253-013-4926-6
|
| [16] |
Apiyo D, Wittung-Stafshede P (2005) Unique complex between bacterial azurin and tumor-suppressor protein p53. Biochem Biophys Res Commun 332: 965–968. doi: 10.1016/j.bbrc.2005.05.038
|
| [17] | Goto M, Yamada T, Kimbara K, et al. (2002) Induction of apoptosis in macrophages by Pseudomonas aeruginosa azurin: tumour-suppressor protein p53 and reactive oxygen species, but not redox activity, as critical elements in cytotoxicity. Mol Microbiol 47: 549–559. |
| [18] |
Yamada T, Fialho AM, Punj V, et al. (2005) Internalization of bacterial redox protein azurin in mammalian cells: entry domain and specificity. Cell Microbiol 7: 1418–1431. doi: 10.1111/j.1462-5822.2005.00567.x
|
| [19] | Hong CS, Yamada T, Hashimoto W, et al. (2006) Disrupting the entry barrier and attacking brain tumors: The role of the Neisseria H.8 epitope and the Laz protein. Cell Cycle 5: 1633–1641. |
| [20] |
Chaudhari A, Mahfouz M, Fialho AM, et al. (2007) Cupredoxin-cancer interrelationship: azurin binding with EphB2, interference in EphB2 tyrosine phosphorylation and inhibition of cancer growth. Biochemistry 46: 1799–1810. doi: 10.1021/bi061661x
|
| [21] |
Mehta RR, Yamada T, Taylor BN, et al. (2011) A cell penetrating peptide derived from azurin inhibits angiogenesis and tumor growth by inhibiting phosphorylation of VEGFR-2, FAK and Akt. Angiogenesis 14: 355–369. doi: 10.1007/s10456-011-9220-6
|
| [22] |
Mehta RR, Hawthorne M, Peng X, et al. (2010) A 28-amino-acid peptide fragment of the cupredoxin azurin prevents carcinogen-induced mouse mammary lesions. Cancer Prev Res 3: 1351–1360. doi: 10.1158/1940-6207.CAPR-10-0024
|
| [23] |
Warso MA, Richards JM, Mehta D, et al. (2013) A first-in-class, first-in-human, phase I trial of p28, a non-HDM2-mediated peptide inhibitor of p53 ubiquitination in patients with advanced solid tumours. Br J Cancer 108: 1061–1070. doi: 10.1038/bjc.2013.74
|
| [24] | Lulla RR, Goldman S, Yamada T, et al. (2016) Phase 1 trial of p28 (NSC745104), a non-HDM2-mediated peptide inhibitor of p53 ubiquitination in pediatric patients with recurrent or progressive central nervous system tumors: a pediatric brain tumor consortium study. Neuro Oncol pii: now047. |
| [25] |
Taylor BN, Mehta RR, Yamada T, et al. (2009) Noncationic peptides obtained from azurin preferentially enter cancer cells. Cancer Res 69: 537–546. doi: 10.1158/0008-5472.CAN-08-2932
|
| [26] |
Jia L, Gorman GS, Coward LU, et al. (2011) Preclinical pharmacokinetics, metabolism, and toxicity of azurin-p28 (NSC745104) a peptide inhibitor of p53 ubiquitination. Cancer Chemother Pharmacol 68: 513–524. doi: 10.1007/s00280-010-1518-3
|
| [27] |
Fialho AM, Bernardes N, Chakrabarty AM (2012) Recent patents on live bacteria and their products as potential anticancer agents. Recent Pat Anticancer Drug Discov 7: 31–55. doi: 10.2174/157489212798357949
|
| [28] |
Bernardes N, Abreu S, Carvalho FA, et al. (2016) Modulation of membrane properties of lung cancer cells by azurin enhances the sensitivity to EGFR-targeted therapy and decreased β1 integrin-mediated adhesion. Cell Cycle 15: 1415–1424. doi: 10.1080/15384101.2016.1172147
|
| [29] | Yamada T, Das Gupta TK, Beattie CW (2016) p28-mediated activation of p53 in G2-M phase of the cell cycle enhances the efficacy of DNA damaging and antimitotic chemotherapy. Cancer Res 76: 2354–2365. |
| [30] |
Zaborina O, Dhiman N, Ling Chen M, et al. (2000) Secreted products of a nonmucoid Pseudomonas aeruginosa strain induce two modes of macrophage killing: external-ATP-dependent, P2Z-receptor-mediated necrosis and ATP-independent, caspase-mediated apoptosis. Microbiology 146: 2521–2530. doi: 10.1099/00221287-146-10-2521
|
| [31] |
Bernardes N., Ribeiro AS., Abreu S, et al. (2013) The bacterial protein azurin impairs invasion and FAK/Src signaling in P-cadherin-overexpressing breast cancer cell models. PLoS One 8: e69023. doi: 10.1371/journal.pone.0069023
|
| [32] |
Ribeiro AS, Albergaria A, Sousa B, et al. (2010) Extracellular cleavage and shedding of P-cadherin: a mechanism underlying the invasive behavior of breast cancer cells. Oncogene 29: 392–402. doi: 10.1038/onc.2009.338
|
| [33] |
Bernardes N, Ribeiro AS, Abreu S, et al. (2014) High-throughput molecular profiling of a P-cadherin overexpressing breast cancer model reveals new targets for the anti-cancer bacterial protein azurin. Int J Biochem Cell Biol 50: 1–9. doi: 10.1016/j.biocel.2014.01.023
|
| [34] |
Mollinedo F, de la Iglesia-Vicente J, Gajate C, et al. (2010) Lipid raft-targeted therapy in multiple myeloma. Oncogene 29: 3748–3757. doi: 10.1038/onc.2010.131
|
| [35] | Coppari E, Yamada T, Bizzarri AR, et al. (2014) A nanotechnological molecular-modeling, and immunological approach to study the interaction of the anti-tumorigenic peptide p28 with the p53 family of proteins. Intl J Nanomedicine 9: 1799–1813. |
| [36] | Yamada T, Das Gupta TK, Beattie CW (2013) P28, an anionic cell-penetrating peptide, increases the activity of wild type and mutated p53 without altering its conformation. Mol. Pharm 10: 3375–3383. |
| [37] | Cho I, Blaser MJ (2012) The human microbiome: at the interface of health and disease. Nat Rev Genet 13: 260–270. |
| [38] |
Shaikh F, Abhinand P, Ragunath P (2012) Identification & characterization of Lactobacillus salavarius bacteriocins and its relevance in cancer therapeutics. Bioinformation 8: 589–594. doi: 10.6026/97320630008589
|
| [39] | Nguyen C, Nguyen VD (2016) Discovery of azurin-like anticancer bacteriocins from human gut microbiome through homology modeling and molecular docking against the tumor suppressor p53. Biomed Res Int 2016: 8490482. |
| [40] | Guex N, Peitsch MC (1997) SWISS-MODEL and the Swiss-PdbViewer: An environment for comparative protein modeling. Electrophoresis 18: 2714–2723. |
| [41] |
Gibrat JF, Madej T, Bryant SH (1996) Surprising similarities in structure comparison. Curr Opin Struct Biol 6: 377–385. doi: 10.1016/S0959-440X(96)80058-3
|
| [42] | Paz I, Kligun E, Bengad B, et al. (2016) BindUP: a web server for non-homology-based prediction of DNA and RNA binding proteins. Nucleic Acids Res pii: gkw454. |
| [43] |
Jo S, Kim T, Iyer VG, et al. (2008) CHARMM-GUI: A web-based graphical user interface for CHARMM. J Comput Chem 29: 1859–1865. doi: 10.1002/jcc.20945
|
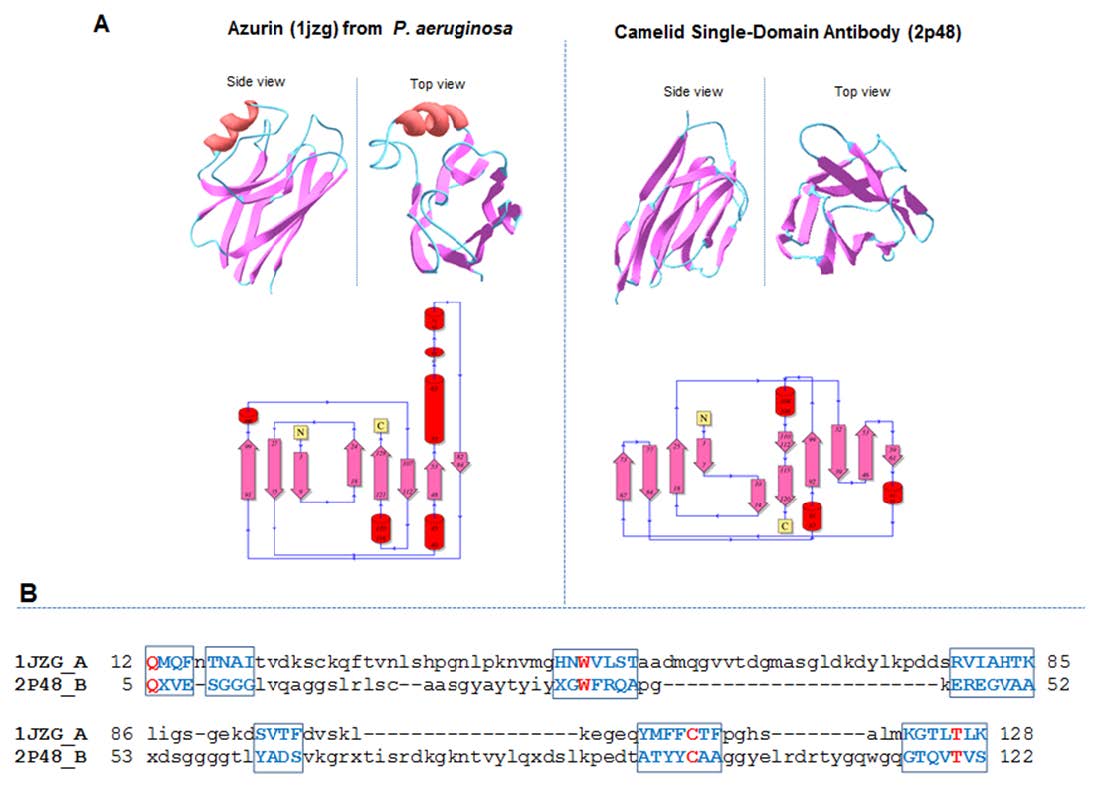
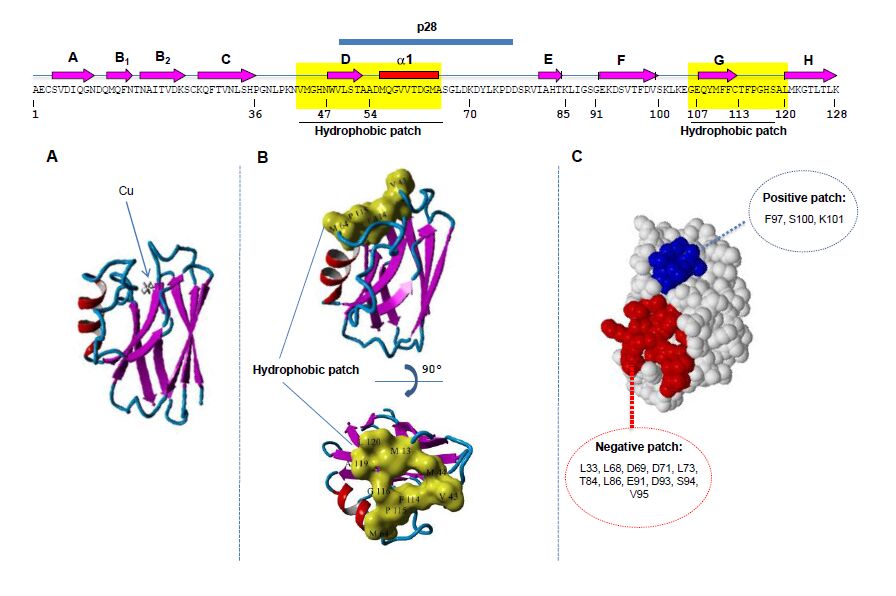
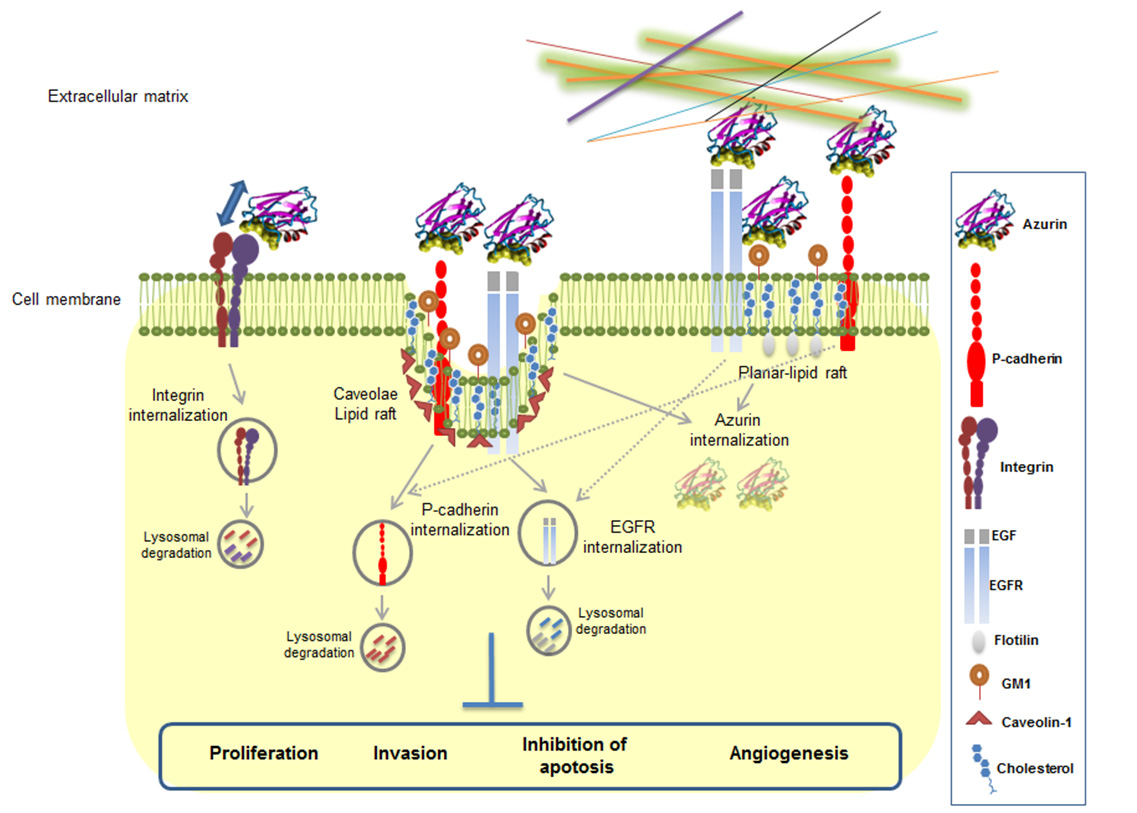
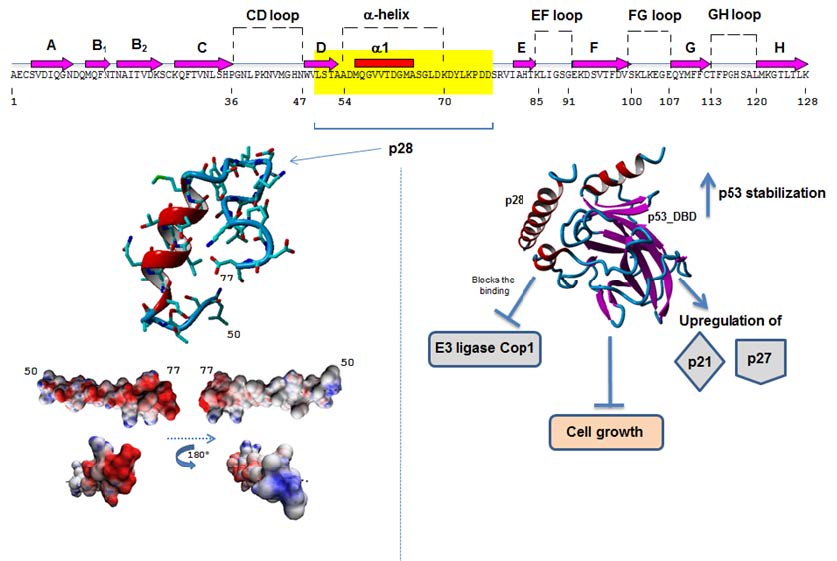
Figures(4)

Arsenio M. Fialho, Nuno Bernardes, Ananda M Chakrabarty. Exploring the anticancer potential of the bacterial protein azurin[J]. AIMS Microbiology, 2016, 2(3): 292-303. doi: 10.3934/microbiol.2016.3.292







 DownLoad:
DownLoad: