Citation: Paula García-Fraile, Esther Menéndez, Raúl Rivas. Role of bacterial biofertilizers in agriculture and forestry[J]. AIMS Bioengineering, 2015, 2(3): 183-205. doi: 10.3934/bioeng.2015.3.183

| [1] |
Gray EJ, Smith DL (2005) Intracellular and extracellular PGPR: commonalities and distinctions in the plant-bacterium signaling processes. Soil Biol Biochem 37: 395-412. doi: 10.1016/j.soilbio.2004.08.030

|
| [2] | Khalid A, Arshad M, Shaharoona B, et al. (2009) Plant Growth Promoting Rhizobacteria and Sustainable Agriculture. Microbial Strategies for Crop Improvement: Berlin: Springer; 133-160. |
| [3] |
Malusá E, Vassilev N (2014) A contribution to set a legal framework for biofertilisers. Appl Microbiol Biotechnol 98: 6599-6607. doi: 10.1007/s00253-014-5828-y
|
| [4] | Lloret L, Martinez-Romero E (2005) [Evolution and phylogeny of rhizobia]. Rev Latinoam Microbiol 47: 43-60. |
| [5] | Raymond J, Siefert JL, Staples CR, et al. (2004) The natural history of nitrogen fixation. Mol Biol Evol 21: 541-554. |
| [6] | De Felipe MR (2006) Fijación biológica de dinitrógeno atmosférico en vida libre. In: Bedmar E, Gonzálo J, Lluch C et al., editors. Fijación de Nitrógeno: Fundamentos y Aplicaciones. Granada: Sociedad Española de Microbiología (SEFIN): 9-16. |
| [7] | Tejera N, Lluch C, Martínez-Toledo MV, et al. (2005) Isolation and characterization of Azotobacter and Azospirillum strains from the sugarcane rhizosphere Plant Soil 270: 223-232. |
| [8] |
Sahoo RK, Ansari MW, Dangar TK, et al. (2014) Phenotypic and molecular characterisation of efficient nitrogen-fixing Azotobacter strains from rice fields for crop improvement. Protoplasma 251: 511-523. doi: 10.1007/s00709-013-0547-2
|
| [9] |
Sahoo RK, Ansari MW, Pradhan M, et al. (2014) Phenotypic and molecular characterization of native Azospirillum strains from rice fields to improve crop productivity. Protoplasma 251: 943-953. doi: 10.1007/s00709-013-0607-7
|
| [10] |
Dobereiner J (1961) Nitrogen-fixing bacteria of the genus Beijerinckia Derx in the rhizosphere of sugar cane. Plant Soil 15: 211-216. doi: 10.1007/BF01400455
|
| [11] |
Wani SA, Chand S, Ali T (2013) Potential Use of Azotobacter Chroococcum in Crop Production: An Overview. Curr Agri Res J 1: 35-38. doi: 10.12944/CARJ.1.1.04
|
| [12] |
Muñoz-Rojas J, Caballero-Mellado J (2003) Population dynamics of Gluconacetobacter diazotrophicus in sugarcane cultivars and its effect on plant growth. Microb Ecol 46: 454-464. doi: 10.1007/s00248-003-0110-3
|
| [13] | Berg RH, Tyler ME, Novick NJ, et al. (1980) Biology of azospirillum-sugarcane association: enhancement of nitrogenase activity. Appl Environ Microbiol 39: 642-649. |
| [14] | Vargas C, Pádua VLM, Nogueira EM,, et al. (2003) Signaling pathways mediating the association between sugarcane and endophytic diazotrophic bacteria: A genomic approach. Symbiosis 35: 159-180. |
| [15] | Elbeltagy A, Nishioka K, Sato T, et al. (2001) Endophytic colonization and in planta nitrogen fixation by a Herbaspirillum sp. isolated from wild rice species. Appl Environ Microbiol 67: 5285-5293. |
| [16] |
Reis VM, Baldani JI, Baldani VLD, et al. (2000) Biological Dinitrogen Fixation in Gramineae and Palm Trees. Crit Rev Plant Sci 19: 227-247. doi: 10.1016/S0735-2689(00)80003-9
|
| [17] |
Pereira JAR, Cavalcante VA, Baldani JI, et al. (1988) Field inoculation of sorghum and rice with Azospirillum spp. and Herbaspirillum seropedicae. Plant Soil 110: 269-274. doi: 10.1007/BF02226807
|
| [18] | Valverde A, Velazquez E, Gutierrez C, et al. (2003) Herbaspirillum lusitanum sp. nov., a novel nitrogen-fixing bacterium associated with root nodules of Phaseolus vulgaris. Int J Syst Evol Microbiol 53: 1979-1983. |
| [19] | Hurek T, Reinhold-Hurek B (2003) Azoarcus sp. strain BH72 as a model for nitrogen-fixing grass endophytes. J Biotechnol 106: 169-178. |
| [20] | Reinhold-Hurek B, Hurek T (1998) Interactions of Gramineous Plants with Azoarcus spp. and Other Diazotrophs: Identification, Localization, and Perspectives to Study their Function. Crit Rev Plant Sci 17: 29-54. |
| [21] | Govindarajan M, Balandreau J, Kwon SW, et al. (2007) Effects of the inoculation of Burkholderia vietnamensis and related endophytic diazotrophic bacteria on grain yield of rice. Microb Ecol 55: 21-37. |
| [22] |
Kao CM, Chen SC, Chen YS, et al. (2003) Detection of Burkholderia pseudomallei in rice fields with PCR-based technique. Folia Microbiol (Praha) 48: 521-524. doi: 10.1007/BF02931334
|
| [23] |
Sabry SRS, Saleh SA, Batchelor CA, et al. (1997) Endophytic establishment of Azorhizobium caulinodans in wheat. Proc Biol Sci 264: 341-346. doi: 10.1098/rspb.1997.0049
|
| [24] | Tan Z, Hurek T, Vinuesa P, et al. (2001) Specific detection of Bradyrhizobium and Rhizobium strains colonizing rice (Oryza sativa) roots by 16S-23S ribosomal DNA intergenic spacer-targeted PCR. Appl Environ Microbiol 67: 3655-3664. |
| [25] | Yanni Y, Rizk R, Abd-El Fattah F, et al. (2001) The beneficial plant growth-promoting association of Rhizobium leguminosarum bv. trifolii with rice roots. Aust J Plant Physiol 28: 845-870. |
| [26] |
Young JPW (1996) Phylogeny and taxonomy of rhizobia. Plant Soil 186: 45-52. doi: 10.1007/BF00035054
|
| [27] |
Moulin L, Munive A, Dreyfus B, et al. (2001) Nodulation of legumes by members of the beta-subclass of Proteobacteria. Nature 411: 948-950. doi: 10.1038/35082070
|
| [28] |
Yanagi M, Yamasato K (1993) Phylogenetic analysis of the family Rhizobiaceae and related bacteria by sequencing of 16S rRNA gene using PCR and DNA sequencer. FEMS Microbiol Lett 107: 115-120. doi: 10.1111/j.1574-6968.1993.tb06014.x
|
| [29] |
Young JPW, Haukka KE (1996) Diversity and phylogeny of rhizobia. New Phytol 133: 87-94. doi: 10.1111/j.1469-8137.1996.tb04344.x
|
| [30] | Kaschuk G, Hungria M, Andrade DS, et al. (2006) Genetic diversity of rhizobia associated with common bean (Phaseolus vulgaris L.) grown under no-tillage and conventional systems in Southern Brazil. Appl Soil Ecol 32: 210-220. |
| [31] | Acosta-Durán C, Martínez-Romero E (2002) Diversity of rhizobia from nodules of the leguminous tree Gliricidia sepium, a natural host of Rhizobium tropici Arch Microb 178: 161-164. |
| [32] |
Wei HG, Tan ZY, Zhu ME, et al. (2003) Characterization of rhizobia isolated from legume species within the genera Astragalus and Lespedeza grown in the Loess Plateau of China and description of Rhizobium loessense sp. nov. Int J Syst Evol Microbiol 53: 1575-1583. doi: 10.1099/ijs.0.02031-0
|
| [33] |
De Lajudie P, Willems A, Nick G, et al. (1998) Characterization of tropical tree rhizobia and description of Mesorhizobium plurifarium sp. nov. Int J Syst Bacteriol 48: 369-382. doi: 10.1099/00207713-48-2-369
|
| [34] |
Yao ZY, Kan FL, Wang ET, et al. (2002) Characterization of rhizobia that nodulate legume species of the genus Lespedeza and description of Bradyrhizobium yuanmingense sp. nov. Int J Syst Evol Microbiol 52: 2219-2230. doi: 10.1099/ijs.0.01408-0
|
| [35] | Amarger N (2001) Rhizobia in the field. Advances in Agronomy. London (UK): Academic Press. |
| [36] | Bedmar E, Gonzálo J, Lluch C, et al. (2006) Fijación de Nitrógeno: Fundamentos y Aplicaciones. Granada: Sociedad Española de Microbiología (SEFIN). |
| [37] | Benson DR, Stephens DW, Clawson ML, et al. (1996) Amplification of 16S rRNA genes from Frankia strains in root nodules of Ceanothus griseus, Coriaria arborea, Coriaria plumosa, Discaria toumatou, and Purshia tridentata. Appl Environ Microbiol 62: 2904-2909. |
| [38] | Ganesh G, Misra AK, Chapelon C, et al. (1994) Morphological and molecular characterization of Frankia sp. isolates from nodules of Alnus nepalensis Don. Arch Microbiol 161: 152-155. |
| [39] |
Kaneko T, Nakamura Y, Sato S, et al. (2000) Complete genome structure of the nitrogen-fixing symbiotic bacterium Mesorhizobium loti. DNA Res 7: 331-338. doi: 10.1093/dnares/7.6.331
|
| [40] |
Simonet P, Normand P, Moiroud A, et al. (1990) Identification of Frankia strains in nodules by hybridization of polymerase chain reaction products with strain-specific oligonucleotide probes. Arch Microb 153: 235-240. doi: 10.1007/BF00249074
|
| [41] |
Zimpfer JF, Igual JM, McCarty B, et al. (2004) Casuarina cunninghamiana tissue extracts stimulate the growth of Frankia and differentially alter the growth of other soil microorganisms. J Chem Ecol 30: 439-452. doi: 10.1023/B:JOEC.0000017987.19225.86
|
| [42] |
Costacurta A, Vanderleyden J (1995) Synthesis of phytohormones by plant-associated bacteria. Crit Rev Microbiol 21: 1-18. doi: 10.3109/10408419509113531
|
| [43] | Spaepen S (2015) Plant Hormones Produced by Microbes. In: Lugtenberg B, editor. Principles of Plant-Microbe Interactions. Switzerland: Springer International Publishing; 247-256. |
| [44] | Tanimoto E (2005) Regulation and root growth by plant hormones-roles for auxins and gibberellins. Crit Rev Plant Sci 24: 249-265. |
| [45] |
Ouzari H, Khsairi A, Raddadi N, et al. (2008) Diversity of auxin-producing bacteria associated to Pseudomonas savastanoi -induced olive knots. J Basic Microbiol 48: 370-377. doi: 10.1002/jobm.200800036
|
| [46] | Ahmed A, Hasnain S (2010) Auxin producing Bacillus sp. : Auxin quantification and effect on the growth Solanum tuberosum. Pure Appl Chem 82: 313-319. |
| [47] |
Hayat R, Ali S, Amara U, et al. (2010) Soil beneficial bacteria and their role in plant growth promotion: a review. Ann Microbiol 60: 579-598. doi: 10.1007/s13213-010-0117-1
|
| [48] |
Verma VC, Singh SK, Prakash S (2011) Bio-control and plant growth promotion potential of siderophore producing endophytic Streptomyces from Azadirachta indica A. Juss. J Basic Microb 51: 550-556. doi: 10.1002/jobm.201000155
|
| [49] |
Bent E, Tuzun S, Chanway CP, et al. (2001) Alterations in plant growth and in root hormone levels of lodgepole pines inoculated with rhizobacteria. Can J Microbiol 47: 793-800. doi: 10.1139/w01-080
|
| [50] |
Garcia-Fraile P, Carro L, Robledo M, et al. (2012) Rhizobium promotes non-legumes growth and quality in several production steps: towards a biofertilization of edible raw vegetables healthy for humans. PLoS One 7: e38122. doi: 10.1371/journal.pone.0038122
|
| [51] |
Flores-Felix JD, Menendez E, Rivera LP, et al. (2013) Use of Rhizobium leguminosarum as a potential biofertilizer for Lactuca sativa and Daucus carota crops. J Plant Nutr Soil Sc 176: 876-882. doi: 10.1002/jpln.201300116
|
| [52] |
Aloni R, Aloni E, Langhans M, et al. (2006) Role of cytokinin and auxin in shaping root architecture: regulating vascular differentiation, lateral root initiation, root apical dominance and root gravitropism. Ann Bot 97: 883-893. doi: 10.1093/aob/mcl027
|
| [53] | Sokolova MG, Akimova GP, Vaishlia OB (2011) Effect of phytohormones synthesized by rhizosphere bacteria on plants. Prikl Biokhim Mikrobiol 47: 302-307. |
| [54] |
Ortiz-Castro R, Valencia-Cantero E, López-Bucio J (2008) Plant growth promotion by Bacillus megaterium involves cytokinin signaling. Plant Signal Behav 3: 263-265. doi: 10.4161/psb.3.4.5204
|
| [55] |
Liu F, Xing S, Ma H, et al. (2013) Cytokinin-producing, plant growth-promoting rhizobacteria that confer resistance to drought stress in Platycladus orientalis container seedlings. Appl Microbiol Biotechnol 97: 9155-9164. doi: 10.1007/s00253-013-5193-2
|
| [56] | Bottini R, Cassan F, Piccoli P (2004) Gibberellin production by bacteria and its involvement in plant growth promotion and yield increase. Appl Microbiol Biotechnol 65: 497-503. |
| [57] | Joo GJ, Kim YM, Kim JT, et al. (2005) Gibberellins-producing rhizobacteria increase endogenous gibberellins content and promote growth of red peppers. J Microbiol 43: 510-515. |
| [58] | Khan AL, Waqas M, Kang SM, et al. (2014) Bacterial endophyte Sphingomonas sp. LK11 produces gibberellins and IAA and promotes tomato plant growth. J Microbiol 52: 689-695. |
| [59] |
Reid MS, Mor Y, Kofranek AM (1981) Epinasty of Poinsettias-the Role of Auxin and Ethylene. Plant Physiol 67: 950-952. doi: 10.1104/pp.67.5.950
|
| [60] |
KeÇpczyński J, KeÇpczyńska E (1997) Ethylene in seed dormancy and germination. Physiologia Plantarum 101: 720-726. doi: 10.1111/j.1399-3054.1997.tb01056.x
|
| [61] |
Galland M, Gamet L, Varoquaux F, et al. (2012) The ethylene pathway contributes to root hair elongation induced by the beneficial bacteria Phyllobacterium brassicacearum STM196. Plant Sci 190: 74-81. doi: 10.1016/j.plantsci.2012.03.008
|
| [62] | Jackson MB (1991) Ethylene in root growth and development. In: Matoo AK, Suttle JC, editors. The Plant Hormone Ethylene. Boca Raton, Florida: CRC Press; 159-181. |
| [63] |
Ahmad M, Zahir ZA, Khalid M, et al. (2013) Efficacy of Rhizobium and Pseudomonas strains to improve physiology, ionic balance and quality of mung bean under salt-affected conditions on farmer's fields. Plant Physiol Biochem 63: 170-176. doi: 10.1016/j.plaphy.2012.11.024
|
| [64] |
Yang SF, Hoffman NE (1984) Ethylene Biosynthesis and its Regulation in Higher Plants. Ann Rev Plant Physiol 35: 155-189. doi: 10.1146/annurev.pp.35.060184.001103
|
| [65] |
Klee HJ, Hayford MB, Kretzmer KA, et al. (1991) Control of Ethylene Synthesis by Expression of a Bacterial Enzyme in Transgenic Tomato Plants. Plant Cell 3: 1187-1193 doi: 10.1105/tpc.3.11.1187
|
| [66] |
Saleem M, Arshad M, Hussain S, et al. (2007) Perspective of plant growth promoting rhizobacteria (PGPR) containing ACC deaminase in stress agriculture. J Ind Microbiol Biotechnol 34: 635-648. doi: 10.1007/s10295-007-0240-6
|
| [67] |
Shaharoona B, Naveed M, Arshad M, et al. (2008) Fertilizer-dependent efficiency of Pseudomonas for improving growth, yield, and nutrient use efficiency of wheat (Triticum aestivum L. ). Appl Microbiol Biotechnol 79: 147-155. doi: 10.1007/s00253-008-1419-0
|
| [68] | Oertli JJ (1987) Exogenous application of vitamins as regulators for growth and development of plants—a review. Z Pflanzenernahr Bodenk 150: 375-391. |
| [69] |
Okon Y, Itzigsohn R (1995) The development of Azospirillum as a commercial inoculant for improving crop yields. Biotechnol Adv 13: 415-424. doi: 10.1016/0734-9750(95)02004-M
|
| [70] |
Brown ME, Carr GR (1984) Interactions between Azotobacter chroococcum and vesicular-arbuscular mycorrhiza and their effects on plant growth. J Appl Bacteriol 56: 429-437. doi: 10.1111/j.1365-2672.1984.tb01371.x
|
| [71] | Rodelas B, González-López J, Pozo C, et al. (1999) Response of Faba bean (Vicia faba L. ) to combined inoculation with Azotobacter and Rhizobium leguminosarum bv. viceae. Appl Soil Ecol 12: 51-59. |
| [72] |
Revillas JJ, Rodelas B, Pozo C, et al. (2000) Production of B-group vitamins by two Azotobacter strains with phenolic compounds as sole carbon source under diazotrophic and adiazotrophic conditions. J Appl Microbiol 89: 486-493. doi: 10.1046/j.1365-2672.2000.01139.x
|
| [73] |
Sharma SB, Sayyed RZ, Trivedi MH, et al. (2013) Phosphate solubilizing microbes: sustainable approach for managing phosphorus deficiency in agricultural soils. Springerplus 2: 587. doi: 10.1186/2193-1801-2-587
|
| [74] |
Zou X, Binkley D, Doxtader KG (1992) A new method for estimating gross phosphorus mineralization and immobilization rates in soils. Plant Soil 147: 243-250. doi: 10.1007/BF00029076
|
| [75] | Lindsay WL, Vlek PLG, Chien SH (1989) Phosphate minerals. In: Dixon JB, Weed SB, editors. Minerals in Soil Environments. 2 ed. Madison, Wisconsin: Soil Science Society of America; 1089-1130. |
| [76] | Norrish K, Rosser H (1983) Mineral phosphate. In: Lenaghan JJ, Katsantoni G, editors. Soils: an Australian viewpoint. Melbourne: CSIRO Publishing; 335-361. |
| [77] |
Dastager SG, Deepa CK, Pandey A (2010) Isolation and characterization of novel plant growth promoting Micrococcus sp NII-0909 and its interaction with cowpea. Plant Physiol Biochem 48: 987-992. doi: 10.1016/j.plaphy.2010.09.006
|
| [78] | Pindi PK, Satyanarayana SDV (2012) Liquid Microbial Consortium—A Potential Tool for Sustainable Soil Health. J Biofertil Biopest 3: 1-9. |
| [79] |
Flores-Felix JD, Silva LR, Rivera LP, et al. (2015) Plants probiotics as a tool to produce highly functional fruits: the case of Phyllobacterium and vitamin C in strawberries. PLoS One 10: e0122281. doi: 10.1371/journal.pone.0122281
|
| [80] | Shanware AS, Kalkar SA, Trivedi MM (2014) Potassium Solublisers: Occurrence, Mechanism and Their Role as Competent Biofertilizers. Int J Curr Microbiol App Sci 3: 622-629. |
| [81] |
Sheng XF, He LY (2006) Solubilization of potassium-bearing minerals by a wild-type strain of Bacillus edaphicus and its mutants and increased potassium uptake by wheat. Can J Microbiol 52: 66-72. doi: 10.1139/w05-117
|
| [82] | Sangeeth KP, Bhai RS, Srinivasan V (2012) Paenibacillus glucanolyticus, a promising potassium solubilizing bacterium isolated from black pepper (Piper nigrum L.) rhizosphere. J Spic Aromat Crops 21: 118-124. |
| [83] | Basak BB, Biswas DR (2009) Influence of potassium solubilizing microorganism (Bacillus mucilaginosus) and waste mica on potassium uptake dynamics by sudan grass (Sorghum vulgare Pers. ) grown under two Alfisols. Plant Soil 317: 235-255. |
| [84] | Han HS, Lee KD (2005) Phosphate and Potassium Solubilizing Bacteria Effect on Mineral Uptake, Soil Availability and Growth of Eggplant. Res J Agric Biol Sci 1: 176-180. |
| [85] | Han HS, Supanjani S, Lee KD (2006) Effect of co-inoculation with phosphate and potassium solubilizing bacteria on mineral uptake and growth of pepper and cucumber. Plant Soil Environ 52: 130-136. |
| [86] | Crowley DA (2006) Microbial Siderophores in the Plant Rhizosphere. In: Barton LL, Abadia J, editors. Iron Nutrition in Plants and Rhizospheric Microorganisms Netherlands: Springer Netherlands; 169-190. |
| [87] |
Ahmed E, Holmstrom SJ (2014) Siderophores in environmental research: roles and applications. Microb Biotechnol 7: 196-208. doi: 10.1111/1751-7915.12117
|
| [88] |
Wang W, Vinocur B, Altman A (2003) Plant responses to drought, salinity and extreme temperatures: towards genetic engineering for stress tolerance. Planta 218: 1-14. doi: 10.1007/s00425-003-1105-5
|
| [89] |
Liddycoat SM, Greenberg BM, Wolyn DJ (2009) The effect of plant growth-promoting rhizobacteria on asparagus seedlings and germinating seeds subjected to water stress under greenhouse conditions. Can J Microbiol 55: 388-394. doi: 10.1139/W08-144
|
| [90] |
Paul D, Nair S (2008) Stress adaptations in a Plant Growth Promoting Rhizobacterium (PGPR) with increasing salinity in the coastal agricultural soils. J Basic Microbiol 48: 378-384. doi: 10.1002/jobm.200700365
|
| [91] |
Yao L, Wu Z, Zheng Y, et al. (2010) Growth promotion and protection against salt stress by Pseudomonas putida Rs-198 on cotton. Eur J Soil Biol 46: 49-54. doi: 10.1016/j.ejsobi.2009.11.002
|
| [92] |
Egamberdiyeva D (2007) The effect of plant growth promoting bacteria on growth and nutrient uptake of maize in two different soils. Appl Soil Ecol 36: 184-189. doi: 10.1016/j.apsoil.2007.02.005
|
| [93] |
El-Akhal MR, Rincon A, Coba de la Pena T, et al. (2013) Effects of salt stress and rhizobial inoculation on growth and nitrogen fixation of three peanut cultivars. Plant Biol (Stuttg) 15: 415-421. doi: 10.1111/j.1438-8677.2012.00634.x
|
| [94] |
Thomashow LS (1996) Biological control of plant root pathogens. Curr Opin Biotechnol 7: 343-347. doi: 10.1016/S0958-1669(96)80042-5
|
| [95] | Dilantha Fernando WG, Nakkeeran S, Zhang Y (2006) Biosynthesis of Antibiotics by PGPR and its Relation in Biocontrol of Plant Diseases. In: Siddiqui ZA, editor. PGPR: Biocontrol and Biofertilization. The Netherlands: Springer; 67-109. |
| [96] | Mazzola M, Fujimoto DK, Thomashow LS, et al. (1995) Variation in Sensitivity of Gaeumannomyces graminis to Antibiotics Produced by Fluorescent Pseudomonas spp. and Effect on Biological Control of Take-All of Wheat. Appl Environ Microbiol 61: 2554-2559. |
| [97] |
Maksimov IV, Abizgil'dina RR, Pusenkova LI (2011) Plant Growth Promoting Rhizobacteria as Alternative to Chemical Crop Protectors from Pathogens (Review). Appl Biochem Microbiol 47: 333-345. doi: 10.1134/S0003683811040090
|
| [98] | Silo-Suh LA, Lethbridge BJ, Raffel SJ, et al. (1994) Biological activities of two fungistatic antibiotics produced by Bacillus cereus UW85. Appl Environ Microbiol 60: 2023-2030. |
| [99] |
Jones DA (1998) Why are so many food plants cyanogenic? Phytochemistry 47: 155-162. doi: 10.1016/S0031-9422(97)00425-1
|
| [100] |
Thamer S, Schädler M, Bonte D, et al. (2011) Dual benefit from a belowground symbiosis: nitrogen fixing rhizobia promote growth and defense against a specialist herbivore in a cyanogenic plant. Plant Soil 341: 209-219. doi: 10.1007/s11104-010-0635-4
|
| [101] | Kumar H, Bajpai VK, Dubey RC, et al. (2010) Wilt disease management and enhancement of growth and yield of Cajanus cajan (L) var. Manak by bacterial combinations amended with chemical fertilizer. Crop Protect 29: 591-598. |
| [102] |
Arora NK, Khare E, Oh JH, et al. (2008) Diverse mechanisms adopted by Pseudomonas fluorescent PGC2 during the inhibition of Rhizoctonia solani and Phytophthora capsici. World J Microbiol Biotechnol 24: 581-585. doi: 10.1007/s11274-007-9505-5
|
| [103] | Schnepf E, Crickmore N, Van Rie J, et al. (1998) Bacillus thuringiensis and its pesticidal crystal proteins. Microbiol Mol Biol Rev 62: 775-806. |
| [104] |
Chattopadhyay A, Bhatnagar NB, Bhatnagar R (2004) Bacterial insecticidal toxins. Crit Rev Microbiol 30: 33-54. doi: 10.1080/10408410490270712
|
| [105] |
Beneduzi A, Ambrosini A, Passaglia LM (2012) Plant growth-promoting rhizobacteria (PGPR): Their potential as antagonists and biocontrol agents. Genet Mol Biol 35: 1044-1051. doi: 10.1590/S1415-47572012000600020
|
| [106] |
Schippers B, Bakker AW, Bakker PAHM (1987) Interactions of Deleterious and Beneficial Rhizosphere Microorganisms and the Effect of Cropping Practices. Ann Rev Phytopathol 25: 339-358. doi: 10.1146/annurev.py.25.090187.002011
|
| [107] |
Pal KK, Tilak KV, Saxena AK, et al. (2001) Suppression of maize root diseases caused by Macrophomina phaseolina, Fusarium moniliforme and Fusarium graminearum by plant growth promoting rhizobacteria. Microbiol Res 156: 209-223. doi: 10.1078/0944-5013-00103
|
| [108] |
Radzki W, Gutierrez Manero FJ, Algar E, et al. (2013) Bacterial siderophores efficiently provide iron to iron-starved tomato plants in hydroponics culture. Antonie Van Leeuwenhoek 104: 321-330. doi: 10.1007/s10482-013-9954-9
|
| [109] |
Yu XM, Ai CX, Xin L, et al. (2011) The siderophore-producing bacterium, Bacillus subtilis CAS15, has a biocontrol effect on Fusarium wilt and promotes the growth of pepper. Eur J Soil Biol 47: 138-145. doi: 10.1016/j.ejsobi.2010.11.001
|
| [110] |
Bashan Y (1998) Inoculants of plant growth-promoting bacteria for use in agriculture. Biotechnol Adv 16: 729-770. doi: 10.1016/S0734-9750(98)00003-2
|
| [111] |
Smidsrod O, Skjak-Braek G (1990) Alginate as immobilization matrix for cells. Trends Biotechnol 8: 71-78. doi: 10.1016/0167-7799(90)90139-O
|
| [112] |
Bashan Y, Hernandez JP, Leyva LA, et al. (2002) Alginate microbeads as inoculant carriers for plant growth-promoting bacteria. Biol Fert Soils 35: 359-368. doi: 10.1007/s00374-002-0481-5
|
| [113] | VanderGheynst JS, Scher H, Guo HY (2006) Design of formulations for improved biological control agent viability and sequestration during storage Indust Biotech 2: 213-219. |
| [114] | Martinez-Viveros O, Jorquera MA, Crowley DE, et al. (2010) Mechanisms and Practical Considerations Involved in Plant Growth Promotion by Rhizobacteria. J Soil Sci Plant Nut 10: 293-319. |
| [115] | Malusa E, Sas-Paszt L, Ciesielska J (2012) Technologies for beneficial microorganisms inocula used as biofertilizers. The Scientific World J 2012: 491206. |
| [116] | Ben Rebah F, Tyagi RD, Prevost D (2002) Production of S. meliloti using wastewater sludge as a raw material: effect of nutrient addition and pH control. Environ Technol 23: 623-629. |
| [117] |
Ben Rebah F, Tyagi RD, Prevost D (2002) Wastewater sludge as a substrate for growth and carrier for rhizobia: the effect of storage conditions on survival of Sinorhizobium meliloti. Bioresour Technol 83: 145-151. doi: 10.1016/S0960-8524(01)00202-4
|
| [118] |
Vassileva M, Serrano M, Bravo V, et al. (2010) Multifunctional properties of phosphate-solubilizing microorganisms grown on agro-industrial wastes in fermentation and soil conditions. Appl Microbiol Biotechnol 85: 1287-1299. doi: 10.1007/s00253-009-2366-0
|
| [119] |
Gryndler M, Vosatka M, Hrselova H, et al. (2002) Effect of dual inoculation with arbuscular mycorrhizal fungi and bacteria on growth and mineral nutrition of strawberry. J Plant Nut 25: 1341-1358. doi: 10.1081/PLN-120004393
|
| [120] |
Medina A, Probanza A, Gutierrez Mañero FJ, et al. (2003) Interactions of arbuscular-mycorrhizal fungi and Bacillus strains and their effects on plant growth, microbial rhizosphere activity (thymidine and leucine incorporation) and fungal biomass (ergosterol and chitin). Appl Soil Ecol 22: 15-28. doi: 10.1016/S0929-1393(02)00112-9
|
| [121] | Brar SK, Sarma SJ, Chaabouni E (2012) Shelf-life of Biofertilizers: An Accord between Formulations and Genetics. J Biofertil Biopestici 3: e109. |
| [122] | Mahdi SS, Hassan GI, Samoon SA, et al. (2010) Bio-fertilizers in Organic Agriculture. J Phytol 2: 42-54. |
| [123] |
Yardin MR, Kennedy IR, Thies JE (2000) Development of high quality carrier materials for field delivery of key microorganisms used as bio-fertilisers and bio-pesticides. Radiat Phys Chem 57: 565-568. doi: 10.1016/S0969-806X(99)00480-6
|
| [124] | Sethi SK, Adhikary SP (2012) Cost effective pilot scale production of biofertilizer using Rhizobium and Azotobacter. Afr J Biotechnol 11: 13490-13493. |
| [125] |
Baudoin E, Lerner A, Mirza MS, et al. (2010) Effects of Azospirillum brasilense with genetically modified auxin biosynthesis gene ipdC upon the diversity of the indigenous microbiota of the wheat rhizosphere. Res Microbiol 161: 219-226. doi: 10.1016/j.resmic.2010.01.005
|
| [126] |
Galleguillos C, Aguirre C, Miguel Barea J, et al. (2000) Growth promoting effect of two Sinorhizobium meliloti strains (a wild type and its genetically modified derivative) on a non-legume plant species in specific interaction with two arbuscular mycorrhizal fungi. Plant Sci 159: 57-63. doi: 10.1016/S0168-9452(00)00321-6
|
| [127] | Joshi F, Chaudhari A, Joglekar P, et al. (2008) Effect of expression of Bradyrhizobium japonicum 61A152 fegA gene in Mesorhizobium sp., on its competitive survival and nodule occupancy on Arachis hypogea. Appl Soil Ecol 40: 338-347. |
| [128] | Group FBP, editor (2006) Biofertilizer Manual. Tokyo, Japan: Japan Atomic Industrial Forum. |
| [129] | Babalola OO, Glick BR (2012) Indigenous African agriculture and plant associated microbes: Current practice and future transgenic prospects. Sci Res Essays 7: 2431-2439. |
| [130] | Turrent-Fernandez A Fertilizer technology and its efficient use for crop production- Foreword. In: Etchevers JD, editor; 1994; Mexico city, Mexico. International Society of Soil Science. |
| [131] |
Cirera X, Masset E (2010) Income distribution trends and future food demand. Philos Trans R Soc Lond B Biol Sci 365: 2821-2834. doi: 10.1098/rstb.2010.0164
|
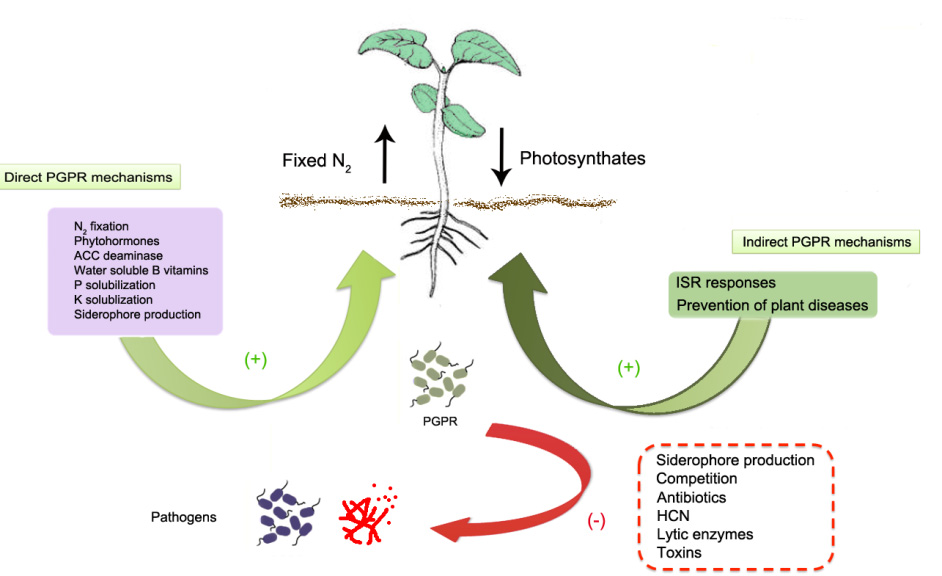
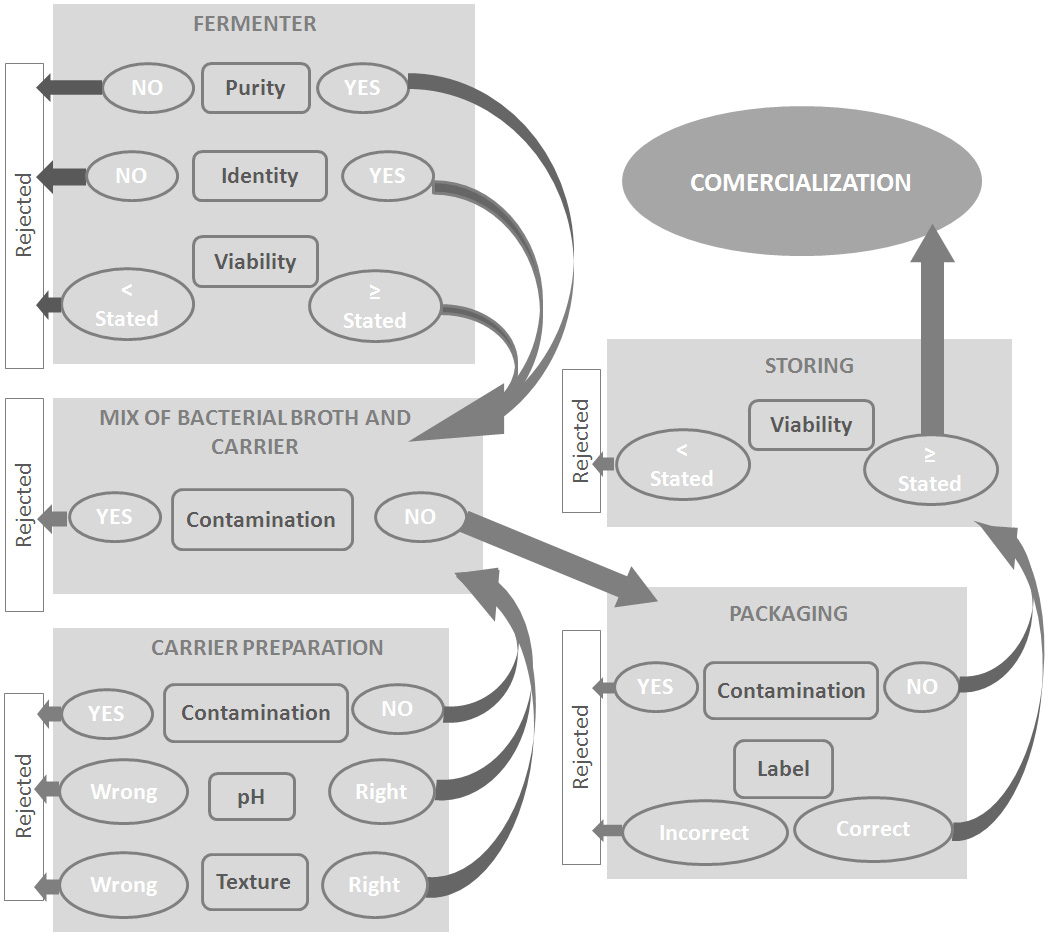
Figures(2) / Tables(2)

Paula García-Fraile, Esther Menéndez, Raúl Rivas. Role of bacterial biofertilizers in agriculture and forestry[J]. AIMS Bioengineering, 2015, 2(3): 183-205. doi: 10.3934/bioeng.2015.3.183







 DownLoad:
DownLoad: