Citation: Feng Hu, Zhigang Zhu, Jeury Mejia, Hao Tang, Jianting Zhang. Real-time indoor assistive localization with mobile omnidirectional vision and cloud GPU acceleration[J]. AIMS Electronics and Electrical Engineering, 2017, 1(1): 74-99. doi: 10.3934/ElectrEng.2017.1.74

| [1] |
Cummins M, Newman P (2011) Appearance-only slam at large scale with fab-map 2.0. Int J Robot Res 30: 1100-1123. doi: 10.1177/0278364910385483

|
| [2] |
Davison AJ, Reid ID, Molton ND, et al. (2007) Monoslam: Real-time single camera slam. IEEE T Pattern Anal 29: 1052-1067. doi: 10.1109/TPAMI.2007.1049
|
| [3] | Di Corato F, Pollini L, Innocenti M, et al. (2011) An entropy-like approach to vision based autonomous navigation. IEEE T Robotic Autom 1640-1645. |
| [4] | Rivera-Rubio J, Idrees S, Alexiou I, et al. (2013) Mobile visual assistive apps: Benchmarks of vision algorithm performance. In: New trends in image analysis and processing–iciap Springer 30-40. |
| [5] |
Liu Z, Zhang L, Liu Q, et al. (2017) Fusion of magnetic and visual sensors for indoor localization: Infrastructure-free and more effective. IEEE T Multimedia 19: 874-888. doi: 10.1109/TMM.2016.2636750
|
| [6] | Tang H, Tsering N, Hu F (2016) Automatic pre-journey indoor map generation using autocad floor plan. J Tec Pers Disabil 4: 176-191. |
| [7] | Ravi N, Shankar P, Frankel A, et al. (2006) Indoor localization using camera phones. In: IEEE Workshop on Mobile Computing Systems and Applications IEEE 49. |
| [8] | Tang H, Tsering N, Hu F (2016) Automatic pre-journey indoor map generation using autocad floor plan. In: 31st Annual International Technology and Persons with Disabilities Conference San Diego, CA, U.S.A. |
| [9] | Kulyukin V, Gharpure C, Nicholson J, et al. (2004) Rfid in robot-assisted indoor navigation for the visually impaired. Intell Robot Syst 2: 1979-1984. |
| [10] |
Cicirelli G, Milella A, Di Paola D (2012) Rfid tag localization by using adaptive neuro-fuzzy inference for mobile robot applications. Ind Robot 39: 340-348. doi: 10.1108/01439911211227908
|
| [11] | Legge GE, Beckmann PJ, Tjan BS, et al. (2013) Indoor navigation by people with visual impairment using a digital sign system. PloS one 8. |
| [12] | Hu F, Zhu Z, Zhang J (2014) Mobile panoramic vision for assisting the blind via indexing and localization. In: Computer Vision-ECCV 2014 Workshops Springer 600-614. |
| [13] |
Murillo AC, Singh G, Kosecka J, et al. (2013) Localization in urban environments using a panoramic gist descriptor. IEEE T Robot 29: 146-160. doi: 10.1109/TRO.2012.2220211
|
| [14] | Kume H, Suppé A, Kanade T (2013) Vehicle localization along a previously driven route using an image database. J Mach Vision Appl 177-180. |
| [15] | Badino H, Huber D, Kanade T (2012) Real-time topometric localization. IEEE Int Conference Robotic Autom (ICRA) 1635-1642. |
| [16] | Hu F, Tsering N, Tang H, et al. (2016) Indoor localization for the visually impaired using a 3d sensor. J Technol Pers Disabil 4: 192-203. |
| [17] | Lee YH, Medioni G (2014) Wearable rgbd indoor navigation system for the blind. In: Workshop on Assistive Computer Vision and Robotics IEEE 493-508. |
| [18] | Hu F, Tsering N, Tang H, et al. (2016) Rgb-d sensor based indoor localization for the visually impaired. In: 31st Annual International Technology and Persons with Disabilities Conference San Diego, CA, U.S.A. |
| [19] |
Molina E, Zhu Z (2013) Visual noun navigation framework for the blind. J Assist Technol 7: 118-130. doi: 10.1108/17549451311328790
|
| [20] | GoPano (2016) Gopano micro camera adapter. Available from: Available from: http://www.gopano.com/products/gopano-micro. |
| [21] | Hu F, Li T, Geng Z (2011) Constraints-based graph embedding optimal surveillance-video mosaicing. Asian Conf Pattern Recogn (ACPR) 311-315. |
| [22] | Aly M, Bouguet JY (2012) Street view goes indoors: Automatic pose estimation from uncalibrated unordered spherical panoramas. Workshop Appl Comput Vision (WACV) 1-8. |
| [23] |
Oliva A, Torralba A (2001) Modeling the shape of the scene: A holistic representation of the spatial envelope. Int J Comput Vision 42: 145-175. doi: 10.1023/A:1011139631724
|
| [24] |
Farinella G, Battiato S (2011) Scene classification in compressed and constrained domain. IET Comput Vision 5: 320-334. doi: 10.1049/iet-cvi.2010.0056
|
| [25] | Xiao J, Ehinger KA, Oliva A, et al. (2012) Recognizing scene viewpoint using panoramic place representation. Comput Vision Pattern Recogn (CVPR) 2695-2702. |
| [26] |
Zhu Z, Yang S, Xu G, et al. (1998) Fast road classification and orientation estimation using omniview images and neural networks. IEEE T Image Process 7: 1182-1197. doi: 10.1109/83.704310
|
| [27] | Sun W, Duan N, Ji P, et al. (2016) Intelligent in-vehicle air quality management: A smart mobility application dealing with air pollution in the traffc. In: 23rd World Congress on Intelligent Transportation Systems Melbourne Australia. |
| [28] | Ma C, Duan N, SunW, et al. (2017) Reducing air pollution exposure in a road trip. In: 24rd World Congress on Intelligent Transportation Systems Montreal, Canada. |
| [29] |
Farinella G, Rav D, Tomaselli V, et al. (2015) Representing scenes for real-time context classification on mobile devices. Pattern Recogn 48: 1086-1100. doi: 10.1016/j.patcog.2014.05.014
|
| [30] | Altwaijry H, Moghimi M, Belongie S (2014) Recognizing locations with google glass: A case study. IEEE Winter Conf Appl Comput Vision (WACV) Colorado. |
| [31] | Paisios N (2012) Mobile accessibility tools for the visually impaired [dissertation]. New York University. |
| [32] | Manduchi R (2012) Mobile vision as assistive technology for the blind: An experimental study. In: The 13th International Conference on Computers Helping People of Special Needs (ICCHP) Springer. |
| [33] | Scaramuzza D, Martinelli A, Siegwart R (2006) A toolbox for easily calibrating omnidirectional cameras. Intell Robot Syst 5695-5701. |
| [34] | Nayar SK (1997) Catadioptric omnidirectional camera. Comput Vision Pattern Recogn 482-488. |
| [35] | Kang SB (2000) Catadioptric self-calibration. Comput Vision Pattern Recogn 1: 201-207. |
| [36] | Scaramuzza D, Martinelli A, Siegwart R (2006) A flexible technique for accurate omnidirectional camera calibration and structure from motion. Int Conf Comput Vision Syst 45-45. |
| [37] | Zhu Z, Rajasekar KD, Riseman EM, et al. (2000) Panoramic virtual stereo vision of cooperative mobile robots for localizing 3d moving objects. Omnidirectional Vision 29-36. |


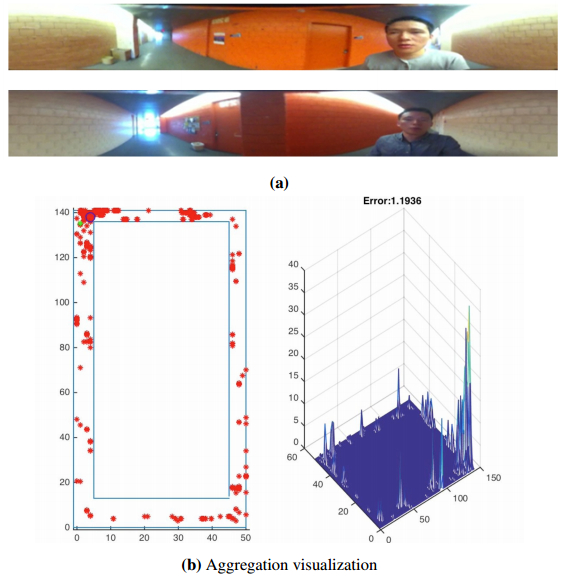
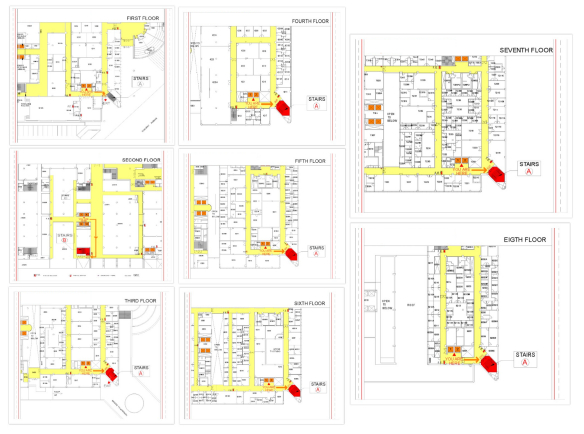
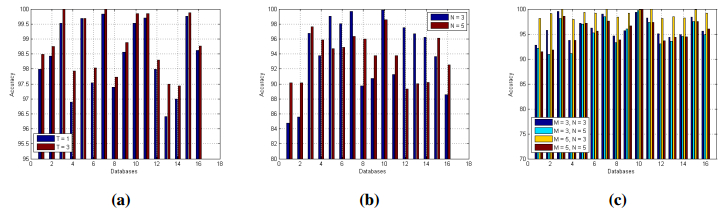
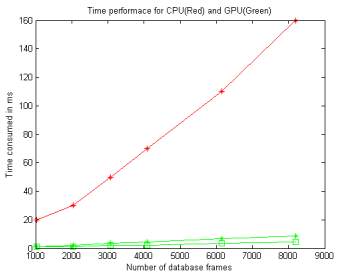
Figures(14)

Feng Hu, Zhigang Zhu, Jeury Mejia, Hao Tang, Jianting Zhang. Real-time indoor assistive localization with mobile omnidirectional vision and cloud GPU acceleration[J]. AIMS Electronics and Electrical Engineering, 2017, 1(1): 74-99. doi: 10.3934/ElectrEng.2017.1.74







 DownLoad:
DownLoad: