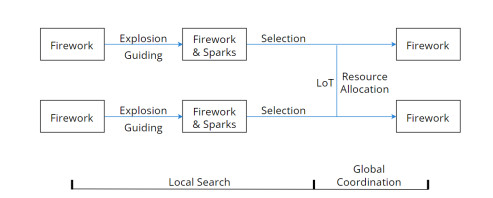
Loser-out tournament-based fireworks algorithm (LoTFWA) is a new baseline of fireworks algorithm (FWA). However, its ability to search deeply in local areas and communicate among fireworks is not satisfying enough. Therefore, this paper proposes a new triple-spark guiding strategy for LoTFWA to deal with the mentioned problems. Among the three sparks generated for guiding, one is exactly the same as the original one in LoTFWA, the second one uses the centroid of good sparks to enhance the local exploitation, and the last one is based on Differential evolution (DE) mutation and used to enhance cooperation and exploration. Experimental results show that with low computational cost, the proposed guiding strategy attains significantly better results than LoTFWA and is competitive with state-of-the-art FWA variants. Furthermore, comprehensive experiments show that the proposed strategy has the potential to combine with other FWA variants to achieve better results.
Citation: Sicheng Li, Junhao Zhu, Mingzhang Han, Mingjie Fan, Xinchao Zhao. A triple-spark guiding strategy to enhance the loser-out tournament-based fireworks algorithm[J]. Mathematical Biosciences and Engineering, 2023, 20(4): 7234-7252. doi: 10.3934/mbe.2023313
Loser-out tournament-based fireworks algorithm (LoTFWA) is a new baseline of fireworks algorithm (FWA). However, its ability to search deeply in local areas and communicate among fireworks is not satisfying enough. Therefore, this paper proposes a new triple-spark guiding strategy for LoTFWA to deal with the mentioned problems. Among the three sparks generated for guiding, one is exactly the same as the original one in LoTFWA, the second one uses the centroid of good sparks to enhance the local exploitation, and the last one is based on Differential evolution (DE) mutation and used to enhance cooperation and exploration. Experimental results show that with low computational cost, the proposed guiding strategy attains significantly better results than LoTFWA and is competitive with state-of-the-art FWA variants. Furthermore, comprehensive experiments show that the proposed strategy has the potential to combine with other FWA variants to achieve better results.

| [1] | Y. Tan, Y. Zhu, Fireworks algorithm for optimization, in Advances in Swarm Intelligence, (2010), 355–364. https://doi.org/10.1007/978-3-642-13495-1_44 |
| [2] |
W. Luo, H. Jin, H. Li, X. Fang, R. Zhou, Optimal performance and application for firework algorithm using a novel chaotic approach, IEEE Access, 8 (2020), 120798–120817. https://doi.org/10.1109/ACCESS.2020.3004430 doi: 10.1109/ACCESS.2020.3004430

|
| [3] | S. An, S. Xiao, G. Zou, D. Lin, Gradient-based fireworks algorithm for solving high dimensional electromagnetic optimization design, in 2022 IEEE 20th Biennial Conference on Electromagnetic Field Computation (CEFC), (2022), 1–2. https://doi.org/10.1109/CEFC55061.2022.9940703 |
| [4] | X. Li, T. Zhang, X. Zhao, S. Li, Region selection with discrete fireworks algorithm for person re-identification, in Advances in Swarm Intelligence, (2021), 433–440. https://doi.org/10.1007/978-3-030-78743-1_39 |
| [5] |
X. Liu, X. Qin, A neighborhood information utilization fireworks algorithm and its application to traffic flow prediction, Expert Syst. Appl., 183 (2021), 115189, https://doi.org/10.1016/j.eswa.2021.115189 doi: 10.1016/j.eswa.2021.115189
|
| [6] |
Y. Hu, M. Li, X. Liu, Y. Tan, Multi-source, multi-object and multi-domain (m-sod) electromagnetic interference system optimised by intelligent optimisation approaches, Nat. Comput., 19 (2020), 713–732. https://doi.org/10.1007/s11047-019-09728-8 doi: 10.1007/s11047-019-09728-8
|
| [7] | D. Roch Dupré, T. Gonsalves, Increasing Energy Efficiency by Optimizing the Electrical Infrastructure of a Railway Line Using Fireworks Algorithm, IGI Global, Pennsylvania, 2020. https://doi.org/10.4018/978-1-7998-1659-1.ch012 |
| [8] |
X. Zhou, Q. Zhao, D. Zhang, Discrete fireworks algorithm for welding robot path planning, J. Phys.: Conf. Ser., 1267 (2019), 012003. https://doi.org/10.1088/1742-6596/1267/1/012003 doi: 10.1088/1742-6596/1267/1/012003
|
| [9] |
A. M. Yadav, K. N. Tripathi, S. C. Sharma, An enhanced multi-objective fireworks algorithm for task scheduling in fog computing environment, Cluster Comput., 25 (2022), 983–998. https://doi.org/10.1007/s10586-021-03481-3 doi: 10.1007/s10586-021-03481-3
|
| [10] |
Y. Chen, F. He, X. Zeng, H. Li, Y. Liang, The explosion operation of fireworks algorithm boosts the coral reef optimization for multimodal medical image registration, Eng. Appl. Artif. Intell., 102 (2021), 104252, https://doi.org/10.1016/j.engappai.2021.104252 doi: 10.1016/j.engappai.2021.104252
|
| [11] | M. Li, Y. Tan, Economic dispatch optimization for microgrid based on fireworks algorithm with momentum, in Advances in Swarm Intelligence (2022), 339–353. https://doi.org/10.1007/978-3-031-09677-8_29 |
| [12] |
R. Storn, K. Price, Differential evolution – a simple and efficient heuristic for global optimization over continuous spaces, J. Global Optim., 11 (1997), 341–359. https://doi.org/10.1023/A:1008202821328 doi: 10.1023/A:1008202821328
|
| [13] |
X. Yu, N. Jiang, X. Wang, M. Li, A hybrid algorithm based on grey wolf optimizer and differential evolution for UAV path planning, Expert Syst. Appl., 215 (2022), 119327. https://doi.org/10.1016/j.eswa.2022.119327 doi: 10.1016/j.eswa.2022.119327
|
| [14] |
Y. Li, T. Han, S. Tang, C. Huang, H. Zhou, Y. Wang, An improved differential evolution by hybridizing with estimation-of-distribution algorithm, Inf. Sci., 619 (2023), 439–456. https://doi.org/10.1016/j.ins.2022.11.029 doi: 10.1016/j.ins.2022.11.029
|
| [15] |
J. Tvrdík, I. Křivý, Hybrid differential evolution algorithm for optimal clustering, Appl. Soft Comput., 35 (2015), 502–512, https://doi.org/10.1016/j.asoc.2015.06.032 doi: 10.1016/j.asoc.2015.06.032
|
| [16] |
W. Gong, Z. Cai, C. Ling, De/bbo: A hybrid differential evolution with biogeography-based optimization for global numerical optimization, Soft Comput., 15 (2010), 645–665. https://doi.org/10.1007/s00500-010-0591-1 doi: 10.1007/s00500-010-0591-1
|
| [17] | C. Yu, L. Kelley, S. Zheng, Y. Tan, Fireworks algorithm with differential mutation for solving the cec 2014 competition problems, in 2014 IEEE Congress on Evolutionary Computation (CEC), (2014), 3238–3245. https://doi.org/10.1109/CEC.2014.6900590 |
| [18] |
J. Ji, H. Xiao, C. Yang, Hfade-fmd: a hybrid approach of fireworks algorithm and differential evolution strategies for functional module detection in protein-protein interaction networks, Appl. Intell., 51 (2021), 1118–1132. https://doi.org/10.1007/s10489-020-01791-4 doi: 10.1007/s10489-020-01791-4
|
| [19] |
Y. Zheng, X. Xu, H. Ling, S. Chen, A hybrid fireworks optimization method with differential evolution operators, Neurocomputing, 148 (2015), 75–82, https://doi.org/10.1016/j.neucom.2012.08.075 doi: 10.1016/j.neucom.2012.08.075
|
| [20] | X. Zhang, X. Zhang, UAV path planning based on hybrid differential evolution with fireworks algorithm, in Advances in Swarm Intelligence, (2022), 354–364. https://doi.org/10.1007/978-3-031-09677-8_30 |
| [21] |
J. Li, Y. Tan, Loser-out tournament-based fireworks algorithm for multimodal function optimization, IEEE Trans. Evol. Comput., 22 (2018), 679–691. https://doi.org/10.1109/TEVC.2017.2787042 doi: 10.1109/TEVC.2017.2787042
|
| [22] | P. Hong, J. Zhang, Using population migration and mutation to improve loser-out tournament-based fireworks algorithm, in Advances in Swarm Intelligence, (2021), 423–432. https://doi.org/10.1007/978-3-030-78743-1_38 |
| [23] | Y. Li, Y. Tan, Multi-scale collaborative fireworks algorithm, in 2020 IEEE Congress on Evolutionary Computation (CEC), (2020), 1–8. https://doi.org/10.1109/CEC48606.2020.9185563 |
| [24] | S. Li, F. Liu, Adaptive niche radius fireworks algorithm for multi-modal function optimization, in 2021 4th International Conference on Intelligent Autonomous Systems (ICoIAS), (2021), 205–210. https://doi.org/10.1109/ICoIAS53694.2021.00044 |
| [25] | J. Zhang, W. Li, Last-position elimination-based fireworks algorithm for function optimization, in Advances in Swarm Intelligence, (2019), 267–275. https://doi.org/10.1007/978-3-030-26369-0_25 |
| [26] | M. Chen, Y. Tan, Exponentially decaying explosion in fireworks algorithm, in 2021 IEEE Congress on Evolutionary Computation (CEC), (2021), 1406–1413. https://doi.org/10.1109/CEC45853.2021.9504974 |
| [27] |
X. Shen, Q. Wang, Y. Huang, Y. Xuan, An enhanced multi-modal function optimization fireworks algorithm based on loser-out tournament, J. Syst. Simul., 32 (2020), 9–19. https://doi.org/10.16182/j.issn1004731x.joss.19-0225 doi: 10.16182/j.issn1004731x.joss.19-0225
|
| [28] | Y. Li, Y. Tan, Enhancing fireworks algorithm in local adaptation and global collaboration, in Advances in Swarm Intelligence, (2021), 451–465. https://doi.org/10.1007/978-3-030-78743-1_41 |
| [29] | I. Tuba, I. Strumberger, E. Tuba, N. Bacanin, M. Tuba, Performance analysis of the fireworks algorithm versions, in Advances in Swarm Intelligence, (2021), 415–422. https://doi.org/10.1007/978-3-030-78743-1_37 |
| [30] |
J. Li, S. Zheng, Y. Tan, The effect of information utilization: Introducing a novel guiding spark in the fireworks algorithm, IEEE Trans. Evol. Comput., 21 (2017), 153–166. https://doi.org/10.1109/TEVC.2016.2589821 doi: 10.1109/TEVC.2016.2589821
|
| [31] | J. Liang, B. Qu, P. Suganthan, A. Hernández-Díaz, Problem definitions and evaluation criteria for the cec 2013 special session on real-parameter optimization, (2013). |
| [32] | F. Wilcoxon, Individual Comparisons by Ranking Methods, Springer, New York, 1992. |

Figures(2) / Tables(7)

Sicheng Li, Junhao Zhu, Mingzhang Han, Mingjie Fan, Xinchao Zhao. A triple-spark guiding strategy to enhance the loser-out tournament-based fireworks algorithm[J]. Mathematical Biosciences and Engineering, 2023, 20(4): 7234-7252. doi: 10.3934/mbe.2023313







 DownLoad:
DownLoad: