Citation: Volodymyr Ivanov, Viktor Stabnikov, Chen Hong Guo, Olena Stabnikova, Zubair Ahmed, In S. Kim, and Eng-Ban Shuy. Wastewater engineering applications of BioIronTech process based on the biogeochemical cycle of iron bioreduction and (bio)oxidation[J]. AIMS Environmental Science, 2014, 1(2): 53-66. doi: 10.3934/environsci.2014.2.53

| [1] | Ivanov V, Hung YT (2010) Applications of environmental biotechnology. In: Handbook of Environmental Engineering. Vol.10. Environmental Biotechnology, Totowa, NJ, USA: Humana Press, Inc. 2-18. |
| [2] | Ivanov V (2010) Microbiology of environmental engineering systems. In: Handbook of Environmental Engineering. Vol.10. Environmental Biotechnology, Humana Press, Inc. Totowa, NJ, USA: Humana Press, Inc. 19-80. |
| [3] | Ivanov V (2010) Environmental Microbiology for Engineers. CRC Press, Taylor & Francis Group,-Boca Raton.402 p. |
| [4] | Tay JH, Tay STL, Ivanov V, et al. (2006) Compositions and methods for the treatment of wastewater and other waste. Patent of Singapore 106658. Date of grant 31 October 2006, date of filing 16 April 2002. |
| [5] | Tay JH, Tay STL, Ivanov V, et al. (2008) Compositions and methods for the treatment of wastewater and other waste.US Patent 7,393,452.Date of grant July 1, 2008 Date of filing 1 April 11, 2003. |
| [6] | Ivanov V, Stabnikova EV, Stabnikov VP, et al. (2002). Effects of iron compounds on the treatment of fat-containing wastewaters. Appl Biochem & Microbiol 38: 255-258. |
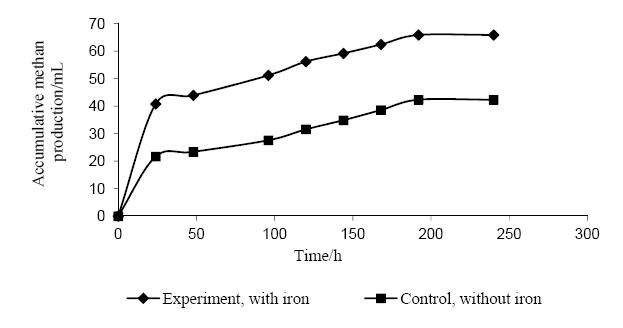
| [7] | Zubair A, Ivanov V, Hyun SH, et al. (2001) Effect of divalent iron on methanogenic fermentation of fat-containing wastewater. Environ Eng Res 6: 139-146. |
| [8] |
Li Z, Wrenn BA, Venosa AD (2006) Effects of ferric hydroxide on methanogenesis from lipids and long-chain fatty acids in anaerobic digestion. Water Environ Res 78: 522-530. doi: 10.2175/106143005X73064

|
| [9] | Stabnikov VP, Ivanov VN (2006) The effect of various iron hydroxide concentrations on the anaerobic fermentation of sulfate-containing model wastewater. Appl Biochem & Microbiol 42: 284-288. |
| [10] | Ivanov V, Tay STL, Wang JY, et al. (2004) Improvement of sludge quality by iron-reducing bacteria. J Residuals Sci Tech 1: 165-168. |
| [11] | Kessler R (2009) Sweeteners persist in waterways. Environ Health Persp 117: A438-A438. |
| [12] |
Mead RN, Morgan JB, Avery GB, et al. (2009) Occurrence of the artificial sweetener sucralose in coastal and marine waters of the United States. Mar Chem 116: 13-17. doi: 10.1016/j.marchem.2009.09.005
|
| [13] |
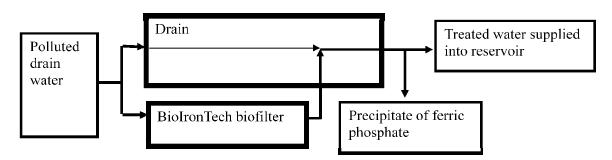
Ivanov V, Stabnikov V, Zhuang WQ, et al. (2005) Phosphate removal from return liquor of municipal wastewater treatment plant using iron-reducing bacteria. J Appl Microbiol 98: 1152-1161. doi: 10.1111/j.1365-2672.2005.02567.x
|
| [14] |
Ivanov V, Lim JJW, Stabnikova O, et al. (2010) Biodegradation of estrogens by facultative anaerobic iron-reducing bacteria. Process Biochem 45: 284-287. doi: 10.1016/j.procbio.2009.09.017
|
| [15] | Stabnikov V, Tay STL, Tay JH, et al. (2004) Effect of iron hydroxide on phosphate removal during anaerobic digestion of activated sludge. Appl Biochem & Microbiol 40: 376-380. |
| [16] |
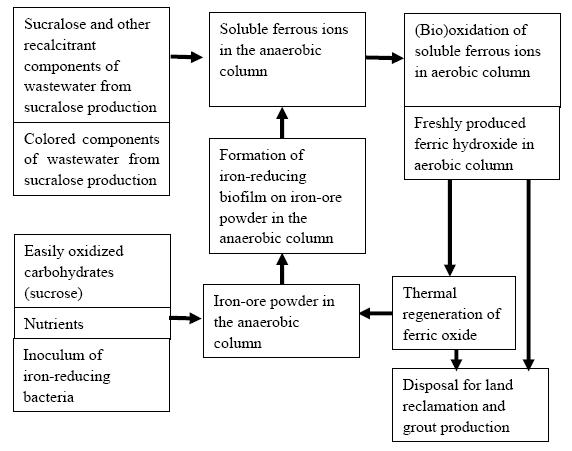
Ivanov V, Kuang SL, Guo CH, et al. (2009) The removal of phosphorus from reject water in a municipal wastewater treatment plant using iron ore. J Chem Technol Biot 84:78-82. doi: 10.1002/jctb.2009
|
| [17] |
Guo CH, Stabnikov V, Ivanov V (2009) The removal of phosphate from wastewater using anoxic reduction of iron ore in the rotating reactor. Biochem Eng J 46: 223-226. doi: 10.1016/j.bej.2009.05.011
|
| [18] |
Lumiste L, Munter R, Sutt J, et al. (2012) Removal of radionuclides from Estonian groundwater using aeration,oxidation, and filtration. P Est Acad Sci 61: 58-64. doi: 10.3176/proc.2012.1.08
|
| [19] |
Munter R (2013) Technology for the removal of radionuclides from natural water and waste management: state of the art. P Est Acad Sci 62: 122-132. doi: 10.3176/proc.2013.2.06
|
| [20] | Chiang YW, Ghyselbrecht K, Santos RM, et al. (2012) Adsorption of multi-heavy metals onto water treatment residuals: Sorption capacities and applications. Chem Eng J 200: 405-415. |
| [21] | Ivanov V, Sihanonth P, Menasveta P (1996) Multistage-ferrous- modified-biofiltration for removal of ammonia from aquacultural water. In: Proceedings of the Asia-Pacific Conference on Sustainable Energy and Environmental Technology. Singapore: World Scientific Publishing 57- 63. |
| [22] | Ivanov V, Stabnikova EV, Shirokih VO (1997) Influence of ferrous oxidation on the nitrification in aqueous and soil model ecosystems. Mikrobiologia (Moscow) 66: 428-433. |
| [23] | Ivanov V, Wang JY, Stabnikova O, et al. (2004) Iron-mediated removal of ammonia from strong nitrogenous wastewater of food processing. Water Sci Technol 49: 421-431. |
| [24] | Stabnikova O, Wang JY, Ivanov V (2010) Value-added biotechnological products from organic wastes. In: Handbook of Environmental Engineering. Vol.10.Environmental Biotechnology, Totowa, NJ, USA: Humana Press, Inc. 343-394. |
| [25] |
Guo CH, Stabnikov V, Ivanov V (2010) The removal of nitrogen and phosphorus from reject water of municipal wastewater treatment plant using ferric and nitrate bioreductions. Bioresource Technol 101: 3992-3999. doi: 10.1016/j.biortech.2010.01.039
|
| [26] | Ivanov V, Stabnikov V, Hung YT (2012) Screening and selection of microorganisms for the environmental biotechnology process. In: Handbook of Environment and Waste Management. Air and Water Pollution Control. World Scientific Publishing Co., Inc., 1137-1149. |
| [27] | Tay JH, Tay STL, Ivanov V, et al. (2004) Application of biotechnology for industrial waste treatment. In: Handbook of Industrial Wastes Treatment. 2nd edition, revised and expanded by Marcel Dekker, NY, 585-618. |


Figures(5) / Tables(4)

Volodymyr Ivanov, Viktor Stabnikov, Chen Hong Guo, Olena Stabnikova, Zubair Ahmed, In S. Kim, and Eng-Ban Shuy. Wastewater engineering applications of BioIronTech process based on the biogeochemical cycle of iron bioreduction and (bio)oxidation[J]. AIMS Environmental Science, 2014, 1(2): 53-66. doi: 10.3934/environsci.2014.2.53







 DownLoad:
DownLoad: