Citation: Frances A. Maratos, Matthew Garner, Alexandra M. Hogan, Anke Karl. When is a Face a Face? Schematic Faces, Emotion, Attention and the N170[J]. AIMS Neuroscience, 2015, 2(3): 172-182. doi: 10.3934/Neuroscience.2015.3.172

| [1] | Bannerman RL, Milders M, de Gelder B, et al. (2009) Orienting to threat: faster localization of fearful facial expressions and body postures revealed by saccadic eye movements. Proc Biol Sci 276(1662): 1635-1641. |
| [2] | Simon EW, Rosen M, Ponpipom A (1996) Age and IQ as predictors of emotion identification in adults with mental retardation. Res Dev Disabil 17(5): 383-389. |
| [3] | Eimer M (2011) The face-sensitive N170 component of the event-related brain potential. Oxford handbook face percept: 329-344. |
| [4] | Rossion B, Jacques C (2011) 5 The N170: Understanding the time course. Oxford handbook potent components 115. |
| [5] | Maurer U, Rossion B, McCandliss BD (2008) Category specificity in early perception: face and word N170 responses differ in both lateralization and habituation properties. Front Hum Neurosci. |
| [6] | Eimer M, Kiss M, Nicholas S (2010) Response profile of the face-sensitive N170 component: a rapid adaptation study. Cerebral Cortex 312. |
| [7] | Jacques C, Rossion B (2010) Misaligning face halves increases and delays the N170 specifically for upright faces: Implications for the nature of early face representations. Brain Res 13(18): 96-109. |
| [8] | Itier RJ, Alain C, Sedore K, et al. (2007) Early face processing specificity: It's in the eyes! J Cog Neurosci 19: 1815-1826. |
| [9] | Itier RJ, Batty M (2009) Neural bases of eye and gaze processing: the core of social cognition. Neurosci Biobehav Rev 33(6): 843-863. |
| [10] | Dering B, Martin CD, Moro S, et al. (2011) Face-sensitive processes one hundred milliseconds after picture onset. Front Hum Neurosci 5. |
| [11] | Eimer M (2011) The face-sensitivity of the n170 component. Front Hum Neurosci 5. |
| [12] | Ganis G, Smith D, Schendan HE (2012) The N170, not the P1, indexes the earliest time for categorical perception of faces, regardless of interstimulus variance. Neuroimage 62(3): 1563-1574. |
| [13] | Rossion B, Caharel S (2011) ERP evidence for the speed of face categorization in the human brain: Disentangling the contribution of low-level visual cues from face perception. Vision Res 51(12): 1297-1311. |
| [14] | Dering B, Hoshino N, Theirry G (2013) N170 modulation is expertisedriven: evidence from word-inversion effects in speakers of different languages. Neuropsycholo Trend 13. |
| [15] |
Tanaka JW, Curran T (2001) A Neural Basis for Expert Object Recognition. Psychol Sci 12: 43-47. doi: 10.1111/1467-9280.00308

|
| [16] |
Gauthier I, Curran T, Curby KM, et al. (2003) Perceptual interference supports a non-modular account of face processing. Nat Neurosci 6: 428-432. doi: 10.1038/nn1029
|
| [17] |
Fan C, Chen S, Zhang L, et al. (2015) N170 changes reflect competition between faces and identifiable characters during early visual processing. NeuroImage 110: 32-38. doi: 10.1016/j.neuroimage.2015.01.047
|
| [18] |
Rugg M D, Milner AD, Lines CR, et al. (1987) Modulation of visual event-related potentials by spatial and non-spatial visual selective attention. Neuropsychologia 25: 85-96. doi: 10.1016/0028-3932(87)90045-5
|
| [19] |
Schinkel S, Ivanova G, Kurths J, et al. (2014) Modulation of the N170 adaptation profile by higher level factors. Bio Psychol 97: 27-34. doi: 10.1016/j.biopsycho.2014.01.003
|
| [20] | Gong J, Lv J, Liu X, et al. (2008) Different responses to same stimuli. Neuroreport 19. |
| [21] | Thierry G, Martin CD, Downing P, et al. (2007) Controlling for interstimulus perceptual variance abolishes N170 face selectivity. Nat Neurosci 10: 505-511. |
| [22] |
Vuilleumier P, Pourtois G (2007) Distributed and interactive brain mechanisms during emotion face perception: Evidence from functional neuroimaging. Neuropsychologia 45: 174-194. doi: 10.1016/j.neuropsychologia.2006.06.003
|
| [23] |
Munte TF, Brack M, Grootheer O, et al. (1998) Brain potentials reveal the timing of face identity and expression judgments. Neurosci Res 30: 25-34. doi: 10.1016/S0168-0102(97)00118-1
|
| [24] |
Eimer M, Holmes A (2007) Event-related brain potential correlates of emotional face processing. Neuropsychologia 45: 15-31. doi: 10.1016/j.neuropsychologia.2006.04.022
|
| [25] |
Batty M, Taylor MJ (2003) Early processing of the six basic facial emotional expressions. Cog Brain Res 17: 613-620. doi: 10.1016/S0926-6410(03)00174-5
|
| [26] |
Krombholz A, Schaefer F, Boucsein W (2007) Modification of N170 by different emotional expression of schematic faces. Biol Psychol 76: 156-162. doi: 10.1016/j.biopsycho.2007.07.004
|
| [27] |
Jiang Y, Shannon RW, Vizueta N, et al. (2009) Dynamics of processing invisible faces in the brain: Automatic neural encoding of facial expression information. Neuroimage 44: 1171-1177. doi: 10.1016/j.neuroimage.2008.09.038
|
| [28] |
Hung Y, Smith ML, Bayle DJ, et al. (2010) Unattended emotional faces elicit early lateralized amygdala-frontal and fusiform activations. Neuroimage 50: 727-733. doi: 10.1016/j.neuroimage.2009.12.093
|
| [29] |
Pegna AJ, Landis T, Khateb A (2008) Electrophysiological evidence for early non-conscious processing of fearful facial expressions. Int J Psychophysiol 70: 127-136. doi: 10.1016/j.ijpsycho.2008.08.007
|
| [30] | Hinojosa JA, Mercado F, Carretié L (2015) N170 sensitivity to facial expression: A meta-analysis. Neurosci Biobehav Rev. |
| [31] | Ledoux JE (1996) The emotional brain: The mysterious underpinnings of emotional life. New York: Simon & Schuster. |
| [32] |
Öhman A, Flykt A, Esteves F (2001) Emotion drives attention: Detecting the snake in the grass. J Exper Psychology-General 130: 466-478. doi: 10.1037/0096-3445.130.3.466
|
| [33] | Luo Q, Holroyd T, Jones M, et al. (2007) Neural dynamics for facial threat processing as revealed by gamma band synchronization using MEG. Neuroimage 34(2): 839-847. |
| [34] | Maratos FA, Mogg K, Bradley BP, et al. (2009) Coarse threat images reveal theta oscillations in the amygdala: a magnetoencephalography study. Cog Affect Behav Neurosci 9(2): 133-143. |
| [35] | Maratos FA, Senior C, Mogg K, et al. (2012) Early gamma-band activity as a function of threat processing in the extrastriate visual cortex. Cog Neurosci 3(1): 62-68. |
| [36] | Fox E, Russo R, Dutton K (2002) Attentional bias for threat: Evidence for delayed disengagement from emotional faces. Cog Emotion 16(3): 355-379. |
| [37] | Gray KLH, Adams WJ, Hedger N, et al. (2013) Faces and awareness: low-level, not emotional factors determine perceptual dominance. Emotion 13(3): 537-544. |
| [38] | Stein T, Seymour K, Hebart MN, et al. (2014) Rapid fear detection relies on high spatial frequencies. Psychol Sci 25(2): 566-574. |
| [39] | Öhman A, Soares SC, Juth P, et al. (2012) Evolutionary derived modulations of attention to two common fear stimuli: Serpents and hostile humans. J Cog Psychol 24(1): 17-32. |
| [40] | Dickins DS, Lipp OV (2014) Visual search for schematic emotional faces: angry faces are more than crosses. Cog Emotion 28(1): 98-114. |
| [41] | Öhman A, Lundqvist D, Esteves F (2001) The face in the crowd revisited: a threat advantage with schematic stimuli. J Personal Soc Psychol 80: 381-396. |
| [42] | Maratos FA, Mogg K, Bradley BP (2008) Identification of angry faces in the attentional blink. Cog Emotion 22(7): 1340-1352. |
| [43] | Maratos FA (2011) Temporal processing of emotional stimuli: the capture and release of attention by angry faces. Emotion 11(5): 1242. |
| [44] | Simione L, Calabrese L, Marucci FS, et al. (2014) Emotion based attentional priority for storage in visual short-term memory. PloS one 9(5): e95261. |
| [45] | Pinkham AE, Griffin M, Baron R, et al. (2010) The face in the crowd effect: anger superiority when using real faces and multiple identities. Emotion 10(1): 141. |
| [46] | Stein T, Sterzer P (2012) Not just another face in the crowd: detecting emotional schematic faces during continuous flash suppression. Emotion 12(5): 988. |
| [47] |
Gratton G, Coles MGH, Donchin E (1983) A new method for off-line removal of ocular artifact. Electroencephalogr Clin Neurophysiol 55:468-474 doi: 10.1016/0013-4694(83)90135-9
|
| [48] | Kolassa IT, Musial F, Kolassa S, et al. (2006) Event-related potentials when identifying or color-naming threatening schematic stimuli in spider phobic and non-phobic individuals. BMC Psychiatry 6(38). |
| [49] |
Babiloni C, Vecchio F, Buffo P, et al. (2010). Cortical responses to consciousness of schematic emotional facial expressions: A high‐resolution EEG study. Hum Brain Map 31(10): 1556-1569. doi: 10.1002/hbm.20958
|
| [50] | Deffke I, Sander T, Heidenreich J, et al. (2007) MEG/EEG sources of the 170 ms response to faces are co-localized in the fusiform gyrus. Neuroimage 35(4): 1495-1501. |
| [51] | Luo S, Luo W, He W, et al. (2013) P1 and N170 components distinguish human-like and animal-like makeup stimuli. Neuroreport 24(9): 482-486. |
| [52] | Mercure E, Cohen Kadosh K, Johnson M (2011) The N170 shows differential repetition effects for faces, objects, and orthographic stimuli. Front Hum Neurosci 5(6). |
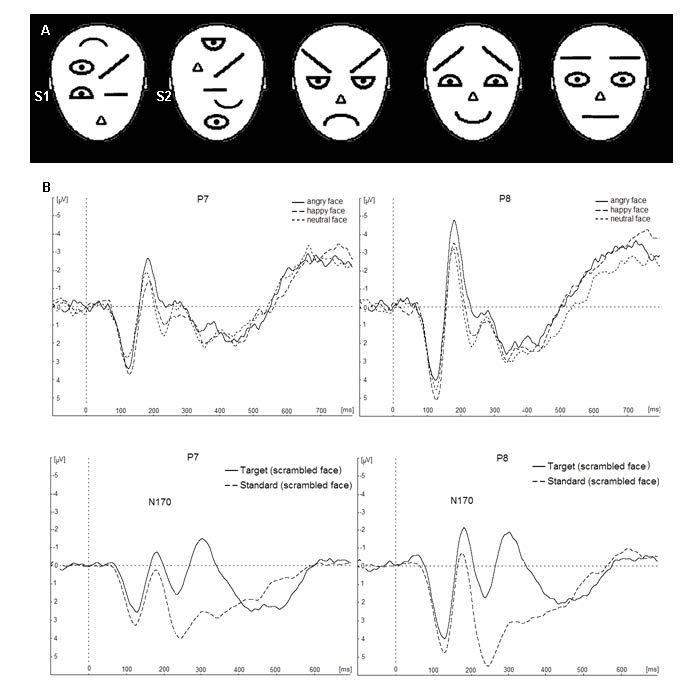
Figures(1) / Tables(1)

Frances A. Maratos, Matthew Garner, Alexandra M. Hogan, Anke Karl. When is a Face a Face? Schematic Faces, Emotion, Attention and the N170[J]. AIMS Neuroscience, 2015, 2(3): 172-182. doi: 10.3934/Neuroscience.2015.3.172







 DownLoad:
DownLoad: