This paper examined rural outdoor activity sites for children in Zhangye, Gansu Province, China. The study analyzed the characteristics of children's groups and their behavioral patterns during outdoor activities in rural areas, and explored the factors affecting children's engagement in outdoor activities. A questionnaire survey was conducted to assess the physical and mental health status of rural children in Gansu Province, the distribution of outdoor activity time, and the influence of activity venues on children. Based on the survey results in rural Zhangye, Gansu Province, activity venues and facilities suitable for rural children in Gansu were identified. Finally, five design principles were proposed (i.e., safety, fun, comfort, accessibility, and guiding) to cater to the activity preferences of rural children in Gansu, China and provide a nurturing environment that fostered their physical and mental growth.
Citation: Weidi Zhang, Runbo Liu. Data analysis and spatial design study of children's activity sites in rural Gansu, China[J]. Urban Resilience and Sustainability, 2023, 1(4): 314-333. doi: 10.3934/urs.2023020
This paper examined rural outdoor activity sites for children in Zhangye, Gansu Province, China. The study analyzed the characteristics of children's groups and their behavioral patterns during outdoor activities in rural areas, and explored the factors affecting children's engagement in outdoor activities. A questionnaire survey was conducted to assess the physical and mental health status of rural children in Gansu Province, the distribution of outdoor activity time, and the influence of activity venues on children. Based on the survey results in rural Zhangye, Gansu Province, activity venues and facilities suitable for rural children in Gansu were identified. Finally, five design principles were proposed (i.e., safety, fun, comfort, accessibility, and guiding) to cater to the activity preferences of rural children in Gansu, China and provide a nurturing environment that fostered their physical and mental growth.

| [1] | Gansu Province Bureau of Statistics (2021) Communiqué of the Seventh National Population Census in Gansu Province (No.6). Available from: http://tjj.gansu.gov.cn/tjj/c109465/202105/feef3c45ac4945528abf6c5d50dc3c2b.shtml. |
| [2] | Gansu Province Bureau of Statistics (2021) Communiqué of the Seventh National Population Census in Gansu Province (No.4). Available from: http://tjj.gansu.gov.cn/tjj/c109465/202105/d61df55e29384cf2b9cf79b26a4cfced.shtml. |
| [3] |
Kou YW (2020) The interactive development of population urbanization and ecological urbanization in Gansu province - from the perspective of coordinated development of poverty alleviation and development. J University Sci Technol Beijing (Soc Sci Ed) 36: 55–61. http://dx.doi.org/10.3969/j.issn.1008-2689.2020.03.008 doi: 10.3969/j.issn.1008-2689.2020.03.008

|
| [4] |
Song Y, Liang JP, Ren ZL, et al. (2012) Research on sustainable development mode of rural left-behind children physical and mental health in western region of China - Taking left-behind children in Chongqing as example. China Sport Sci Technol 48: 100–108. http://dx.doi.org/10.3969/j.issn.1002-9826.2012.05.015 doi: 10.3969/j.issn.1002-9826.2012.05.015
|
| [5] | General Office of the State Council (2011) Outline On the Development of Chinese Children (2011–2020). Available from: https://www.gov.cn/zwgk/2011-08/08/content-1920457.htm. |
| [6] |
Duan CR, Lv LD, Guo J, et al. (2013) Survival and development of left-behind children in rural China: Based on the analysis of sixth census data. Population J 35: 37–49. http://dx.doi.org/10.3969/j.issn.1004-129X.2013.03.004 doi: 10.3969/j.issn.1004-129X.2013.03.004
|
| [7] |
Lu F, Fu SY (2022) The development of rural children's social development questionnaire. Stud Psychol Behav 20: 248–254. https://doi.org/10.12139/j.1672-0628.2022.02.015 doi: 10.12139/j.1672-0628.2022.02.015
|
| [8] |
Garau C, Annunziata A (2020) Supporting children's independent activities in smart and playable public places. Sustainability 12: 8352. https://doi.org/10.3390/su12208352 doi: 10.3390/su12208352
|
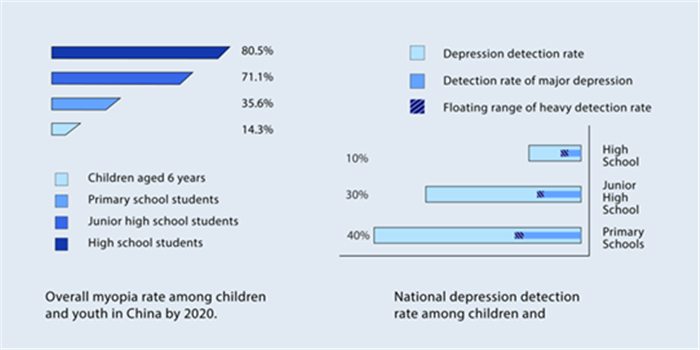
| [9] | The Central People's Government of the People's Republic of China (2021) The prevalence of myopia among Chinese children and teenagers was 52.7 percent in 2020. Available from: https://www.gov.cn/xinwen/2021-07/13/content_5624709.htm. |
| [10] |
Jiang CY, Jia YH (2022) The influence of skip-generation raising on the socialization of left-behind children in rural areas: Based on the baseline data of CEPS 2013–2014. J Yunnan Agr Univer (Soc Sci) 16: 28–35. http://dx.doi.org/10.12371/j.ynau(s).202206010 doi: 10.12371/j.ynau(s).202206010
|
| [11] |
Hazlehurst MF, Muqueeth S, Wolf KL, et al. (2022) Park access and mental health among parents and children during the COVID-19 pandemic. BMC Public Health 22: 800. https://doi.org/10.1186/s12889-022-13148-2 doi: 10.1186/s12889-022-13148-2
|
| [12] |
Lema-Gómez L, Arango-Paternina CM, Eusse-López C, et al. (2021) Family aspects, physical fitness, and physical activity associated with mental-health indicators in adolescents. BMC Public Health 21: 2324. https://doi.org/10.1186/s12889-021-12403-2 doi: 10.1186/s12889-021-12403-2
|
| [13] |
Gao J (2012) Research and practices on children outdoor playground in Japan. Landsc Archit 2012: 99–104. http://dx.doi.org/10.14085/j.fjyl.2012.05.024 doi: 10.14085/j.fjyl.2012.05.024
|
| [14] | Si XP (2017) Research on the design of experiential children's public activity space environment. Master's thesis, TianGong University, Tianjin, 2017. http://dx.doi.org/10.7666/d.Y3193619 |
| [15] | Huang Y (2016) Study on the mental health status of the left behind children in the rural areas after the extracurricular physical exercise program—By skipping, roller skating as an example. Master's thesis, Wuhan Sports University, Wuhan, 2016. |
| [16] | Li N (2008) Children's behavior psychology and children's park design. Master's thesis, Hunan University, Hunan, 2008. http://dx.doi.org/10.7666/d.y1260893 |
| [17] | Ma HM (2019) A study on the optimization of urban and rural mass sports resources allocation in Gansu province from the perspective of healthy China. Master's thesis, Mudanjiang Normal University, Heilongjiang, 2019. http://dx.doi.org/10.27757/d.cnki.gmdjs.2019.000160 |
| [18] |
Liu W, Li C, Tong Y, et al. (2020) The places children go: Understanding spatial patterns and formation mechanism for children's commercial activity space in Changchun city, china. Sustainability 12: 1377. https://doi.org/10.3390/su12041377 doi: 10.3390/su12041377
|
| [19] |
Kemperman AD, Timmermans HJ (2011) Children's recreational physical activity. Leisure Sci 33: 183–204. https://doi.org/10.1080/01490400.2011.564922 doi: 10.1080/01490400.2011.564922
|
| [20] | Pan NN (2018) Study on the Outdoor Activity site Design Based on the Characteristics of Children's Behavior. Master's thesis, Southeast University, Nanjing, 2018. |
| [21] |
Zhou C, Long YL, Gan DX (2004) Discussion about application of "human-oriented" in the building of children's play space. J Hunan Agri Univer (Soc Sci Ed) 5: 84–85. http://dx.doi.org/10.3969/j.issn.1009-2013.2004.03.027 doi: 10.3969/j.issn.1009-2013.2004.03.027
|
| [22] |
Copperman RB, Bhat CR (2007) An analysis of the determinants of children's weekend physical activity participation. Transportation 34: 67–87. https://doi.org/10.1007/s11116-006-0005-5 doi: 10.1007/s11116-006-0005-5
|
| [23] |
Paleti R, Copperman RB, Bhat CR (2011) An empirical analysis of children's after school out-of-home activity-location engagement patterns and time allocation. Transportation 38: 273–303. https://doi.org/10.1007/s11116-010-9300-2 doi: 10.1007/s11116-010-9300-2
|
| [24] |
Hjort M, Martin WM, Stewart T, et al. (2018) Design of urban public spaces: Intent vs. reality. Int J Environ Res Public Health 15: 816. https://doi.org/10.3390/ijerph15040816 doi: 10.3390/ijerph15040816
|
| [25] |
Zhou Y, Wang M, Lin S, et al. (2022) Relationship between children's independent activities and the built environment of outdoor activity space in residential neighborhoods: A case study of Nanjing. Int J Environ Res Public Health 19: 9860. https://doi.org/10.3390/ijerph19169860 doi: 10.3390/ijerph19169860
|
| [26] | Wang N (2017) Research on the interactive design of urban outdoor children recreation space. Master's thesis, Southwest University, Nanjing, 2017. |
| [27] |
Gao L, Chen Y, Su HS (2016) Safety design of outdoor space for children in tropical cities: Taking outdoor children's playground of mid peninsula in Sanya for example. Decoration 2016: 104–105. http://dx.doi.org/10.16272/j.cnki.cn11-1392/j.2016.11.026 doi: 10.16272/j.cnki.cn11-1392/j.2016.11.026
|
| [28] |
Huang V, Zhang H, Song JQ, et al. (2014) The concept of "super flat" in contemporary commercial packaging design. Packag Eng 35: 37–40. http://dx.doi.org/10.19554/j.cnki.1001-3563.2014.12.009 doi: 10.19554/j.cnki.1001-3563.2014.12.009
|
| [29] |
Bao Y, Gao M, Luo D, et al. (2021) Effects of children's outdoor physical activity in the urban neighborhood activity space environment. Front Public Health 9: 631492. https://doi.org/10.3389/fpubh.2021.631492 doi: 10.3389/fpubh.2021.631492
|
| [30] | Zhou WC (2018) Research on interesting landscape design for benefiting children's growth. Master's thesis, Wuhan Institute of Technology, Wuhan, 2018. |
| [31] |
Sheng Q, Wan DY, Yu BY (2021) Effect of space configurational attributes on social interactions in urban parks. Sustainability 13: 7805. https://doi.org/10.3389/fpubh.2021.631492 doi: 10.3389/fpubh.2021.631492
|
| [32] |
Xie YY, Chen L, Zhou AH, et al. (2021) Accessibility analysis of children's service facilities at community scale in Beijing. World Geogr Res 30: 546. http://dx.doi.org/10.3969/j.issn.1004-9479.2021.03.2019548 doi: 10.3969/j.issn.1004-9479.2021.03.2019548
|
| [33] |
Tao C, Li JX, Lai DY (2021) Public activity space quality evaluation and optimization strategy. Planners 37: 75–83. http://dx.doi.org/10.3969/j.issn.1006-0022.2021.21.011 doi: 10.3969/j.issn.1006-0022.2021.21.011
|
| [34] | Li A (2017) Research on the design of communication space for children in the city square. Master's thesis, Hebei University of Architecture, Hebei, 2017. |
| [35] |
Gil-Madrona P, Martínez-López M, Prieto-Ayuso A, et al. (2019) Contribution of public playgrounds to motor, social, and creative development and obesity reduction in children. Sustainability 11: 3787. https://doi.org/10.3390/su11143787 doi: 10.3390/su11143787
|
| [36] |
Gao YJ, Wang CL, Huang ML, et al. (2022) A new perspective of sustainable perception: research on the smellscape of urban block space. Sustainability 14: 9184. https://doi.org/10.3390/su14159184 doi: 10.3390/su14159184
|
| [37] |
Yang MC, Tang M (2015) The methodology for fashion design based on shaping up human body. Creation Design 36: 70–77. http://dx.doi.org/10.3969/J.ISSN.1674-4187.2015.01.012 doi: 10.3969/J.ISSN.1674-4187.2015.01.012
|










Figures(11) / Tables(2)
Weidi Zhang, Runbo Liu. Data analysis and spatial design study of children's activity sites in rural Gansu, China[J]. Urban Resilience and Sustainability, 2023, 1(4): 314-333. doi: 10.3934/urs.2023020







 DownLoad:
DownLoad: