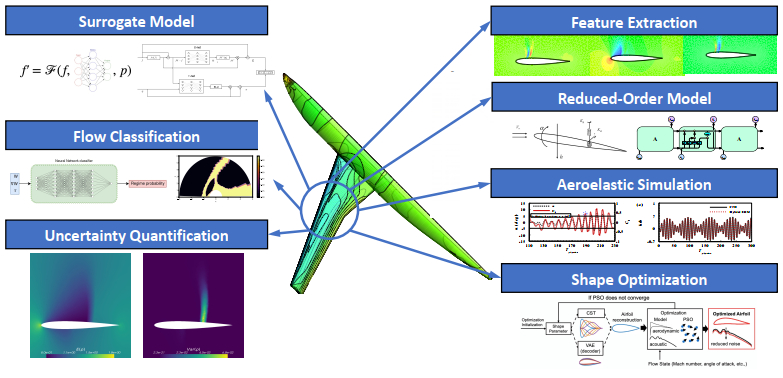
With the increasing availability of flow data from simulation and experiment, artificial intelligence and machine learning are revolutionizing the research paradigm in aerodynamics and related disciplines. The integration of machine learning with theoretical, computational, and experimental investigations unlocks new possibilities for solving cutting-edge problems. In this paper, we review the status of artificial intelligence and machine learning in aerodynamics, including knowledge discovery, theoretical modeling, numerical simulation, and multidisciplinary applications. Representative techniques and successful applications are summarized. Finally, despite successful applications, challenges still remain, which are discussed in the conclusion.
Citation: Jiaqing Kou, Tianbai Xiao. Artificial intelligence and machine learning in aerodynamics[J]. Metascience in Aerospace, 2024, 1(2): 190-218. doi: 10.3934/mina.2024009
With the increasing availability of flow data from simulation and experiment, artificial intelligence and machine learning are revolutionizing the research paradigm in aerodynamics and related disciplines. The integration of machine learning with theoretical, computational, and experimental investigations unlocks new possibilities for solving cutting-edge problems. In this paper, we review the status of artificial intelligence and machine learning in aerodynamics, including knowledge discovery, theoretical modeling, numerical simulation, and multidisciplinary applications. Representative techniques and successful applications are summarized. Finally, despite successful applications, challenges still remain, which are discussed in the conclusion.

| [1] | Anderson J (2011) EBOOK: Fundamentals of Aerodynamics (SI units), McGraw hill, 2011. |
| [2] | Wikipedia (2023) Shadowgraph Images of Re-entry Vehicles — Wikipedia, the free encyclopedia, https://commons.wikimedia.org/wiki/File: Shadowgraph_Images_of_Re-entry_Vehicles_-_GPN-2000-001938.jpg. |
| [3] |
Kou J, Zhang W (2021) Data-driven modeling for unsteady aerodynamics and aeroelasticity. Prog Aerosp Sci 125: 100725. https://doi.org/10.1016/j.paerosci.2021.100725 doi: 10.1016/j.paerosci.2021.100725

|
| [4] |
Xiao T, Frank M (2021) Using neural networks to accelerate the solution of the boltzmann equation. J Computat Phys 443: 110521. https://doi.org/10.1016/j.jcp.2021.110521 doi: 10.1016/j.jcp.2021.110521
|
| [5] |
Xiao T, Frank M (2023) Relaxnet: A structure-preserving neural network to approximate the boltzmann collision operator. J Comput Phys 490: 112317. https://doi.org/10.1016/j.jcp.2023.112317 doi: 10.1016/j.jcp.2023.112317
|
| [6] |
Xiao T, Schotthfer S, Frank M (2023) Predicting continuum breakdown with deep neural networks. J Computat Phys 489: 112278. https://doi.org/10.1016/j.jcp.2023.112278 doi: 10.1016/j.jcp.2023.112278
|
| [7] |
Xiao T, Frank M (2021) A stochastic kinetic scheme for multi-scale flow transport with uncertainty quantification. J Computat Phys 437: 110337. https://doi.org/10.1016/j.jcp.2021.110337 doi: 10.1016/j.jcp.2021.110337
|
| [8] |
Xiao T, Frank M (2021) A stochastic kinetic scheme for multi-scale plasma transport with uncertainty quantification. J Computat Phys 432: 110139. https://doi.org/10.1016/j.jcp.2021.110139 doi: 10.1016/j.jcp.2021.110139
|
| [9] |
Kou J, Zhang W (2017) An improved criterion to select dominant modes from dynamic mode decomposition. European J Mech-B/Fluids 62: 109–129. https://doi.org/10.1016/j.euromechflu.2016.11.015 doi: 10.1016/j.euromechflu.2016.11.015
|
| [10] |
Kou J, Zhang W, Liu Y, et al. (2017) The lowest reynolds number of vortex-induced vibrations. Phys Fluids 29.https://doi.org/10.1063/1.4979966 doi: 10.1063/1.4979966
|
| [11] |
Kou J, Ning C, Zhang W (2022) Transfer learning for flow reconstruction based on multifidelity data. AIAA J 60: 5821–5842. https://doi.org/10.2514/1.J061647 doi: 10.2514/1.J061647
|
| [12] |
Kou J, Zhang W (2017) Multi-kernel neural networks for nonlinear unsteady aerodynamic reduced-order modeling. Aerosp Sci Technol 67: 309–326. https://doi.org/10.1016/j.ast.2017.04.017 doi: 10.1016/j.ast.2017.04.017
|
| [13] |
Li K, Kou J, Zhang W (2019) Deep neural network for unsteady aerodynamic and aeroelastic modeling across multiple mach numbers. Nonlinear Dynam 96: 2157–2177. https://doi.org/10.1007/s11071-019-04915-9 doi: 10.1007/s11071-019-04915-9
|
| [14] |
Kou J, Zhang W (2019) Multi-fidelity modeling framework for nonlinear unsteady aerodynamics of airfoils. Appl Math Model 76: 832–855. https://doi.org/10.1016/j.apm.2019.06.034 doi: 10.1016/j.apm.2019.06.034
|
| [15] |
Kou J, Zhang W (2017) Layered reduced-order models for nonlinear aerodynamics and aeroelasticity. J Fluid Struct 68: 174–193. https://doi.org/10.1016/j.jfluidstructs.2016.10.011 doi: 10.1016/j.jfluidstructs.2016.10.011
|
| [16] |
Kou J, Zhang W (2019) A hybrid reduced-order framework for complex aeroelastic simulations. Aerosp Sci Technol 84: 880–894. https://doi.org/10.1016/j.ast.2018.11.014 doi: 10.1016/j.ast.2018.11.014
|
| [17] |
Kou J, Botero-Bolívar L, Ballano R, Eet al. (2023) Aeroacoustic airfoil shape optimization enhanced by autoencoders. Expert Syst Appl 217 : 119513. https://doi.org/10.1016/j.eswa.2023.119513 doi: 10.1016/j.eswa.2023.119513
|
| [18] | Sprent P (2019) Data driven statistical methods. Routledge. |
| [19] |
Jordan MI, Mitchell TM (2015) Machine learning: Trends, perspectives, and prospects. Science 349: 255–260. https://doi.org/10.1126/science.aaa8415 doi: 10.1126/science.aaa8415
|
| [20] |
Brunton SL, Noack BR, Koumoutsakos P (2020) Machine learning for fluid mechanics. Ann Rev Fluid Mech 52 : 477–508. https://doi.org/10.1146/annurev-fluid-010719-060214 doi: 10.1146/annurev-fluid-010719-060214
|
| [21] |
Vinuesa R, Brunton SL (2022) Enhancing computational fluid dynamics with machine learning. Nall 2: 358–366. https://doi.org/10.1038/s43588-022-00264-7 doi: 10.1038/s43588-022-00264-7
|
| [22] |
Vinuesa R, Brunton SL, McKeon BJ (2023) The transformative potential of machine learning for experiments in fluid mechanics. Nat Rev Phys 5: 536–545. https://doi.org/10.1038/s42254-023-00622-y doi: 10.1038/s42254-023-00622-y
|
| [23] | Zhang W, Kou J, Liu Y (2021) Prospect of artificial intelligence empowered fluid mechanics. Acta Aeronaut et Astronaut Sin 42: 524689. |
| [24] |
Zhang W, Wang X, Kou J (2023) Prospects of multi-paradigm fusion methods for fluid mechanics research. Adv Mech 53: 433–467. https://doi.org/10.6052/1000-0992-22-050 doi: 10.6052/1000-0992-22-050
|
| [25] | Sirovich L (1987) Turbulence and the dynamics of coherent structures. i. coherent structures. Q Appl Math 45: 561–571. |
| [26] |
Taira K, Brunton SL, Dawson ST (2017) Ukeiley, Modal analysis of fluid flows: An overview. Aiaa J 55: 4013–4041. https://doi.org/10.2514/1.J056060 doi: 10.2514/1.J056060
|
| [27] |
Noack BR (2016) From snapshots to modal expansions–bridging low residuals and pure frequencies. J Fluid Mech 802: 1–4. https://doi.org/10.1017/jfm.2016.416 doi: 10.1017/jfm.2016.416
|
| [28] | Berkooz G, Holmes P, Lumley JL (1993) The proper orthogonal decomposition in the analysis of turbulent flows. Ann Rev Fluid Mech 25: 539–575. |
| [29] |
Schmid PJ (2010) Dynamic mode decomposition of numerical and experimental data. J Fluid Mecha 656: 5–28. https://doi.org/10.1017/S0022112010001217 doi: 10.1017/S0022112010001217
|
| [30] |
Schmid PJ (2022) Dynamic mode decomposition and its variants. Ann Rev Fluid Mech 54: 225–254. https://doi.org/10.1146/annurev-fluid-030121-015835 doi: 10.1146/annurev-fluid-030121-015835
|
| [31] |
Sieber M, Paschereit CO, Oberleithner K (2016) Spectral proper orthogonal decomposition. J Fluid Mech 792: 798–828. https://doi.org/10.1017/jfm.2016.103 doi: 10.1017/jfm.2016.103
|
| [32] |
Towne A, Schmidt OT, Colonius T (2018) Spectral proper orthogonal decomposition and its relationship to dynamic mode decomposition and resolvent analysis. J Fluid Mech 847: 821–867. https://doi.org/10.1017/jfm.2018.283 doi: 10.1017/jfm.2018.283
|
| [33] |
Kaiser E, Noack BR, Cordier L, et al. (2014) Cluster-based reduced-order modelling of a mixing layer. J Fluid Mech 754: 365–414. https://doi.org/10.1017/jfm.2014.355 doi: 10.1017/jfm.2014.355
|
| [34] |
Torres P, Clainche S Le, Vinuesa R (2021) On the experimental, numerical and data-driven methods to study urban flows. Energies 14: 1310. https://doi.org/10.3390/en14051310 doi: 10.3390/en14051310
|
| [35] |
Garuma GF (2018) Review of urban surface parameterizations for numerical climate models. Urban Clim 24: 830–851. https://doi.org/10.1016/j.uclim.2017.10.006 doi: 10.1016/j.uclim.2017.10.006
|
| [36] |
Masson V, Heldens W, Bocher E, et al. (2020) City-descriptive input data for urban climate models: Model requirements, data sources and challenges. Urban Clim 31: 100536. https://doi.org/10.1016/j.uclim.2019.100536 doi: 10.1016/j.uclim.2019.100536
|
| [37] |
Rowley CW, Mezić I, Bagheri S, et al. (2009) Spectral analysis of nonlinear flows. J Fluid Mech 641: 115–127. https://doi.org/10.1017/S0022112009992059 doi: 10.1017/S0022112009992059
|
| [38] |
Mezić I (2013) Analysis of fluid flows via spectral properties of the koopman operator. Ann Rev Fluid Mech 45: 357–378. https://doi.org/10.1146/annurev-fluid-011212-140652 doi: 10.1146/annurev-fluid-011212-140652
|
| [39] |
Franz T, Zimmermann R, Grtz S, et al. (2014) Interpolation-based reduced-order modelling for steady transonic flows via manifold learning. Int J Comput Fluid Dynam 28: 106–121. https://doi.org/10.1080/10618562.2014.918695 doi: 10.1080/10618562.2014.918695
|
| [40] |
Farzamnik E, Ianiro A, Discetti S, et al. (2023) From snapshots to manifolds–a tale of shear flows. J Fluid Mech 955: A34. https://doi.org/10.1017/jfm.2022.1039 doi: 10.1017/jfm.2022.1039
|
| [41] |
Milano M, Koumoutsakos P (2002) Neural network modeling for near wall turbulent flow. J Comput Phys 182: 1–26. https://doi.org/10.1006/jcph.2002.7146 doi: 10.1006/jcph.2002.7146
|
| [42] |
Eivazi H, Clainche S Le, Hoyas S (2022) Towards extraction of orthogonal and parsimonious non-linear modes from turbulent flows. Expert Syst Appl 202: 117038. https://doi.org/10.1016/j.eswa.2022.117038 doi: 10.1016/j.eswa.2022.117038
|
| [43] |
Fukami K, Fukagata K, Taira K (2019) Super-resolution reconstruction of turbulent flows with machine learning. J Fluid Mech 870: 106–120. https://doi.org/10.1017/jfm.2019.238 doi: 10.1017/jfm.2019.238
|
| [44] | Wipf D, Nagarajan S (2007) A new view of automatic relevance determination. Adv Neur Inf Proc Syst 20. |
| [45] |
Rudy SH, Sapsis TP (2021) Sparse methods for automatic relevance determination. Physica D 418: 132843. https://doi.org/10.1016/j.physd.2021.132843 doi: 10.1016/j.physd.2021.132843
|
| [46] |
Brunton SL, Proctor JL, Kutz JN (2016) Discovering governing equations from data by sparse identification of nonlinear dynamical systems. P Natl Acad Sci 113: 3932–3937. https://doi.org/10.1073/pnas.1517384113 doi: 10.1073/pnas.1517384113
|
| [47] |
Rudy SH, Brunton SL, Proctor JL, et al. (2017) Data-driven discovery of partial differential equations. Sci Adv 3: e1602614. https://doi.org/10.1126/sciadv.1602614 doi: 10.1126/sciadv.1602614
|
| [48] |
Quade M, Abel M, Nathan Kutz J, et al. (2018) Sparse identification of nonlinear dynamics for rapid model recovery. Chaos 28.https://doi.org/10.1063/1.5027470 doi: 10.1063/1.5027470
|
| [49] |
Li S, Kaiser E, Laima S, et al. (2019) Discovering time-varying aerodynamics of a prototype bridge by sparse identification of nonlinear dynamical systems. Physical Review E 100: 022220. https://doi.org/10.1103/PhysRevE.100.022220 doi: 10.1103/PhysRevE.100.022220
|
| [50] |
Sun C, Tian T, Zhu X et al. (2021) Sparse identification of nonlinear unsteady aerodynamics of the oscillating airfoil, Proceedings of the Institution of Mechanical Engineers. P G J Aerospace Eng 235: 809–824. https://doi.org/10.1177/0954410020959873 doi: 10.1177/0954410020959873
|
| [51] |
Ma T, Cui W, Gao T, et al. (2023) Data-based autonomously discovering method for nonlinear aerodynamic force of quasi-flat plate. Phys Fluids 35.https://doi.org/10.1063/5.0133526 doi: 10.1063/5.0133526
|
| [52] |
Kocijan J, Girard A, Banko B, et al. (2005) Dynamic systems identification with gaussian processes. Math Comput Model Dyn Syst 11: 411–424. https://doi.org/10.1080/13873950500068567 doi: 10.1080/13873950500068567
|
| [53] | Wenk P, Gotovos A, Bauer S, et al. (2019) Fast gaussian process based gradient matching for parameter identification in systems of nonlinear odes, in: The 22nd International Conference on Artificial Intelligence and Statistics, PMLR, 1351–1360. |
| [54] |
Raissi M, Karniadakis GE (2018) Hidden physics models: Machine learning of nonlinear partial differential equations. J Comput Phys 357: 125–141. https://doi.org/10.1016/j.jcp.2017.11.039 doi: 10.1016/j.jcp.2017.11.039
|
| [55] | Grauer JA, Morelli EA (2015) A new formulation of the filter-error method for aerodynamic parameter estimation in turbulence. in: AIAA Atmospheric Flight Mechanics Conference, 2704. https://doi.org/10.2514/6.2015-2704 |
| [56] |
Qin T, Wu K, Xiu D (2019) Data driven governing equations approximation using deep neural networks. J Comput Phys 395: 620–635. https://doi.org/10.1016/j.jcp.2019.06.042 doi: 10.1016/j.jcp.2019.06.042
|
| [57] | Long Z, Lu Y, Ma X, et al. (2018) Pde-net: Learning pdes from data, in: International Conference on Machine Learning PMLR, 3208–3216. |
| [58] | Cranmer M, Sanchez Gonzalez A, Battaglia P, et al. (2020) Discovering symbolic models from deep learning with inductive biases. Adv Neur Inform Process Syst 33: 17429–17442. |
| [59] |
Berg J, Nystrm K (2019) Data-driven discovery of pdes in complex datasets. J Comput Phys 384: 239–252. https://doi.org/10.1016/j.jcp.2019.01.036 doi: 10.1016/j.jcp.2019.01.036
|
| [60] |
Xu H, Zhang W, Wang Y (2021) Explore missing flow dynamics by physics-informed deep learning: The parameterized governing systems. Phys Fluids 33.https://doi.org/10.1063/5.0062377 doi: 10.1063/5.0062377
|
| [61] |
Duraisamy K, Iaccarino G, Xiao H (2019) Turbulence modeling in the age of data. Ann Rev Fluid Mech 51: 357–377. https://doi.org/10.1146/annurev-fluid-010518-040547 doi: 10.1146/annurev-fluid-010518-040547
|
| [62] |
Ling J, Kurzawski A, Templeton J (2016) Reynolds averaged turbulence modelling using deep neural networks with embedded invariance. J Fluid Mech 807: 155–166. https://doi.org/10.1017/jfm.2016.615 doi: 10.1017/jfm.2016.615
|
| [63] |
Wang JX, Wu JL, Xiao H (2017) Physics-informed machine learning approach for reconstructing reynolds stress modeling discrepancies based on dns data. Phys Rev Fluids 2: 034603. https://doi.org/10.1103/PhysRevFluids.2.034603 doi: 10.1103/PhysRevFluids.2.034603
|
| [64] |
Parish EJ, Duraisamy K (2016) A paradigm for data-driven predictive modeling using field inversion and machine learning. J Comput Physics 305: 758–774. https://doi.org/10.1016/j.jcp.2015.11.012 doi: 10.1016/j.jcp.2015.11.012
|
| [65] |
Weatheritt J, Sandberg R (2016) A novel evolutionary algorithm applied to algebraic modifications of the rans stress–strain relationship. J Comput Phys 325: 22–37. https://doi.org/10.1016/j.jcp.2016.08.015 doi: 10.1016/j.jcp.2016.08.015
|
| [66] |
Zhao Y, Akolekar HD, Weatheritt J, et al. (2020) Rans turbulence model development using cfd-driven machine learning. J Comput Phys 411: 109413. https://doi.org/10.1016/j.jcp.2020.109413 doi: 10.1016/j.jcp.2020.109413
|
| [67] |
Zhu L, Zhang W, Kou J (2019) Machine learning methods for turbulence modeling in subsonic flows around airfoils. Phys Fluids 31.https://doi.org/10.1063/1.5061693 doi: 10.1063/1.5061693
|
| [68] |
Volpiani PS, Bernardini RF, Franceschini L (2022) Neural network-based eddy-viscosity correction for rans simulations of flows over bi-dimensional bumps. Int J Heat Fluid Fl 97: 109034. https://doi.org/10.1016/j.ijheatfluidflow.2022.109034 doi: 10.1016/j.ijheatfluidflow.2022.109034
|
| [69] |
Singh AP, Medida S, Duraisamy K (2017) Machine-learning-augmented predictive modeling of turbulent separated flows over airfoils. AIAA J 55: 2215–2227. https://doi.org/10.2514/1.J055595 doi: 10.2514/1.J055595
|
| [70] |
Maulik R, San O (2017) A neural network approach for the blind deconvolution of turbulent flows. J Fluid Mech 831: 151–181. https://doi.org/10.1017/jfm.2017.637 doi: 10.1017/jfm.2017.637
|
| [71] |
Maulik R, San O, Rasheed A, et al. (2019) Subgrid modelling for two-dimensional turbulence using neural networks. J Fluid Mech 858: 122–144. https://doi.org/10.1017/jfm.2018.770 doi: 10.1017/jfm.2018.770
|
| [72] |
Beck A, Flad D, Munz CD (2019) Deep neural networks for data-driven les closure models. J Comput Phys 398: 108910. https://doi.org/10.1016/j.jcp.2019.108910 doi: 10.1016/j.jcp.2019.108910
|
| [73] |
Yang X, Zafar S, Wang JX, et al. (2019) Predictive large-eddy-simulation wall modeling via physics-informed neural networks. Phys Rev Fluids 4: 034602. https://doi.org/10.1103/PhysRevFluids.4.034602 doi: 10.1103/PhysRevFluids.4.034602
|
| [74] |
Zhou Z, He G, Yang X (2021) Wall model based on neural networks for les of turbulent flows over periodic hills. Phys Rev Fluids 6: 054610. https://doi.org/10.1103/PhysRevFluids.6.054610 doi: 10.1103/PhysRevFluids.6.054610
|
| [75] |
Bae HJ, Koumoutsakos P (2022) Scientific multi-agent reinforcement learning for wall-models of turbulent flows. Nat Commun 13: 1443. https://doi.org/10.21203/rs.3.rs-573667/v1 doi: 10.21203/rs.3.rs-573667/v1
|
| [76] |
Dowell EH, Hall KC (2001) Modeling of fluid-structure interaction. Ann Rev Fluid Mech 33: 445–490. https://doi.org/10.1146/annurev.fluid.33.1.445 doi: 10.1146/annurev.fluid.33.1.445
|
| [77] |
Lucia DJ, Beran PS, Silva WA (2004) Reduced-order modeling: new approaches for computational physics. Prog Aerosp Sci 40: 51–117. https://doi.org/10.1016/j.paerosci.2003.12.001 doi: 10.1016/j.paerosci.2003.12.001
|
| [78] | Theodorsen T (1949) General theory of aerodynamic instability and the mechanism of flutter. Tech rep. |
| [79] |
Leishman JG, Beddoes T (1989) A semi-empirical model for dynamic stall. J Am Helicopter Soc 34: 3–17. https://doi.org/10.4050/JAHS.34.3.3 doi: 10.4050/JAHS.34.3.3
|
| [80] | Dowell EH (2014) A modern course in aeroelasticity. 217, Springer. |
| [81] | Noack BR, Morzynski M, Tadmor G (2011) Reduced-order modelling for flow control. 528, Springer Science & Business Media. https://doi.org/10.1007/978-3-7091-0758-4 |
| [82] |
Gao C, Zhang W (2020) Transonic aeroelasticity: A new perspective from the fluid mode. Prog Aerosp Sci 113: 100596. https://doi.org/10.1016/j.paerosci.2019.100596 doi: 10.1016/j.paerosci.2019.100596
|
| [83] | Ljung L (1998) System identification, in: Signal analysis and prediction, Springer, 163–173. https://doi.org/10.1007/978-1-4612-1768-8_11 |
| [84] |
Theofilis V (2011) Global linear instability. Ann Rev Fluid Mech 43: 319–352. https://doi.org/10.1146/annurev-fluid-122109-160705 doi: 10.1146/annurev-fluid-122109-160705
|
| [85] | Juang JN, Pappa RS (1985) An eigensystem realization algorithm for modal parameter identification and model reduction. J Guid Control Dynam 8: 620–627. |
| [86] |
Cowan TJ, Arena Jr AS, Gupta KK (2001) Accelerating computational fluid dynamics based aeroelastic predictions using system identification. J Aircraft 38: 81–87. https://doi.org/10.2514/2.2737 doi: 10.2514/2.2737
|
| [87] |
Leishman J (1988) Validation of approximate indicial aerodynamic functions for two-dimensional subsonic flow. J Aircraft 25: 914–922. https://doi.org/10.2514/3.45680 doi: 10.2514/3.45680
|
| [88] |
Skujins T, Cesnik CE (2014) Reduced-order modeling of unsteady aerodynamics across multiple mach regimes. J Aircraft 51: 1681–1704. https://doi.org/10.2514/1.C032222 doi: 10.2514/1.C032222
|
| [89] |
Silva W (2005) Identification of nonlinear aeroelastic systems based on the volterra theory: progress and opportunities. Nonlinear Dynam 39: 25–62. https://doi.org/10.1007/s11071-005-1907-z doi: 10.1007/s11071-005-1907-z
|
| [90] |
Glaz B, Liu L, Friedmann PP (2010) Reduced-order nonlinear unsteady aerodynamic modeling using a surrogate-based recurrence framework. AIAA J 48: 2418–2429. https://doi.org/10.2514/1.J050471 doi: 10.2514/1.J050471
|
| [91] | Linse DJ, Stengel RF (1993) Identification of aerodynamic coefficients using computational neural networks. J Guid Control Dynam 16: 1018–1025. |
| [92] |
Huang R, Hu H, Zhao Y (2014) Nonlinear reduced-order modeling for multiple-input/multiple-output aerodynamic systems. AIAA J 52: 1219–1231. https://doi.org/10.2514/1.J052323 doi: 10.2514/1.J052323
|
| [93] |
Benner P, Gugercin S, Willcox K (2015) A survey of projection-based model reduction methods for parametric dynamical systems. SIAM Rev 57: 483–531. https://doi.org/10.1137/13093271 doi: 10.1137/13093271
|
| [94] |
Noack BR, Afanasiev K, MORZYŃSKI M, et at. (2003) A hierarchy of low-dimensional models for the transient and post-transient cylinder wake. J Fluid Mech 497: 335–363. https://doi.org/10.1017/S0022112003006694 doi: 10.1017/S0022112003006694
|
| [95] |
Balajewicz MJ, Dowell EH, Noack BR (2013) Low-dimensional modelling of high-reynolds-number shear flows incorporating constraints from the navier–stokes equation. J Fluid Mech 729: 285–308. https://doi.org/10.1017/jfm.2013.278 doi: 10.1017/jfm.2013.278
|
| [96] |
Wei M, Rowley CW (2009) Low-dimensional models of a temporally evolving free shear layer. J Fluid Mech 618: 113–134. https://doi.org/10.1017/S0022112008004539 doi: 10.1017/S0022112008004539
|
| [97] |
Deng N, Noack BR, Morzyński M, et al. (2020) Low-order model for successive bifurcations of the fluidic pinball. J Fluid Mech 884: A37. https://doi.org/10.1017/jfm.2019.959 doi: 10.1017/jfm.2019.959
|
| [98] |
Yu J, Yan C, Guo M (2019) Non-intrusive reduced-order modeling for fluid problems: A brief review. P I Mech Eng G J Aerosp Eng 233: 5896–5912. https://doi.org/10.1016/j.jcp.2019.07.053 doi: 10.1016/j.jcp.2019.07.053
|
| [99] |
Xiao D, Fang F, Buchan AG, et al. (2015) Non-intrusive reduced order modelling of the navier–stokes equations. Comput Method Appl Mech Eng 293: 522–541. https://doi.org/10.1016/j.cma.2015.05.015 doi: 10.1016/j.cma.2015.05.015
|
| [100] |
Hesthaven JS, Ubbiali S (2018) Non-intrusive reduced order modeling of nonlinear problems using neural networks. J Comput Phys 363: 55–78. https://doi.org/10.1016/j.jcp.2018.02.037 doi: 10.1016/j.jcp.2018.02.037
|
| [101] |
Wang Z, Xiao D, Fang F, et al. (2018) Model identification of reduced order fluid dynamics systems using deep learning. Int J Numer Method Fluids 86: 255–268. https://doi.org/10.1002/fld.4416 doi: 10.1002/fld.4416
|
| [102] |
Xu J, Duraisamy K (2020) Multi-level convolutional autoencoder networks for parametric prediction of spatio-temporal dynamics. Comput Method Appl Mech Eng 372: 113379. https://doi.org/10.1016/j.cma.2020.113379 doi: 10.1016/j.cma.2020.113379
|
| [103] |
Kramer B, Peherstorfer B, Willcox KE (2024) Learning nonlinear reduced models from data with operator inference. Ann Rev Fluid Mech 56.https://doi.org/10.1146/annurev-fluid-121021-025220 doi: 10.1146/annurev-fluid-121021-025220
|
| [104] |
Kato H, Yoshizawa A, Ueno G, et al. (2015) A data assimilation methodology for reconstructing turbulent flows around aircraft. J Computat Phys 283: 559–581. https://doi.org/10.1016/j.jcp.2014.12.013 doi: 10.1016/j.jcp.2014.12.013
|
| [105] |
Mons V, Chassaing JC, Gomez T, et al. (2016) Reconstruction of unsteady viscous flows using data assimilation schemes. J Comput Phys 316: 255–280. https://doi.org/10.1016/j.jcp.2016.04.022 doi: 10.1016/j.jcp.2016.04.022
|
| [106] |
Han ZH, Grtz S (2012) Hierarchical kriging model for variable-fidelity surrogate modeling. AIAA J 50: 1885–1896. https://doi.org/10.2514/1.J051354 doi: 10.2514/1.J051354
|
| [107] |
Wang X, Kou J, Zhang W, et al. (2022) Incorporating physical models for dynamic stall prediction based on machine learning. AIAA J 60: 4428–4439. https://doi.org/10.2514/1.J061210 doi: 10.2514/1.J061210
|
| [108] |
Li K, Kou J, Zhang W (2022) Deep learning for multifidelity aerodynamic distribution modeling from experimental and simulation data. AIAA J 60: 4413–4427. https://doi.org/10.2514/1.J061330 doi: 10.2514/1.J061330
|
| [109] |
Ribeiro MD, Stradtner M, Bekemeyer P (2023) Unsteady reduced order model with neural networks and flight-physics-based regularization for aerodynamic applications. Comput Fluids 105949.https://doi.org/10.1016/j.compfluid.2023.105949 doi: 10.1016/j.compfluid.2023.105949
|
| [110] |
Raissi M, Yazdani A, Karniadakis GE (2020) Hidden fluid mechanics: Learning velocity and pressure fields from flow visualizations. Science 367: 1026–1030. https://doi.org/10.1126/science.aaw4741 doi: 10.1126/science.aaw4741
|
| [111] |
Thuerey N, Weißenow K, Prantl L, et al. (2020) Deep learning methods for reynolds-averaged navier–stokes simulations of airfoil flows. AIAA J 58: 25–36. https://doi.org/10.2514/1.J058291 doi: 10.2514/1.J058291
|
| [112] |
Kochkov D, Smith JA, Alieva A, et al., (2021) Machine learning–accelerated computational fluid dynamics, P Natl Acad Sci 118: e2101784118. https://doi.org/10.1073/pnas.2101784118 doi: 10.1073/pnas.2101784118
|
| [113] |
Raissi M, Perdikaris P, Karniadakis GE, (2019) Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. J Comput Phys 378: 686–707. https://doi.org/10.1016/j.jcp.2018.10.045 doi: 10.1016/j.jcp.2018.10.045
|
| [114] |
Pang G, Lu L, Karniadakis GE (2019) fpinns: Fractional physics-informed neural networks. SIAM J Sci Comput 41: A2603–A2626. https://doi.org/10.1137/18M1229845 doi: 10.1137/18M1229845
|
| [115] |
Raissi M, Wang Z, Triantafyllou MS, et al. (2019) Deep learning of vortex-induced vibrations. J Fluid Mech 861: 119–137. https://doi.org/10.31224/osf.io/fnwjy doi: 10.31224/osf.io/fnwjy
|
| [116] |
Sun L, Gao H, Pan S, et al. (2020) Surrogate modeling for fluid flows based on physics-constrained deep learning without simulation data. Comput Method Appl M Eng 361: 112732. https://doi.org/10.1016/j.cma.2019.112732 doi: 10.1016/j.cma.2019.112732
|
| [117] | Jin X, Cai S, Li H, et al. (2020) Nsfnets (navier-stokes flow nets): Physics-informed neural networks for the incompressible navier-stokes equations. arXiv preprint arXiv: 2003.06496. |
| [118] | Wang S, Yu X, Perdikaris P (2020) When and why pinns fail to train: A neural tangent kernel perspective. arXiv preprint arXiv:2007.14527. |
| [119] | Wang S, Teng Y, Perdikaris P (2020) Understanding and mitigating gradient pathologies in physics-informed neural networks. arXiv preprint arXiv:2001.04536. |
| [120] | Chen RT, Rubanova Y, Bettencourt J, et al. (2018) Neural ordinary differential equations, in: Advances in Neural Information Processing Systems, 6571–6583. |
| [121] |
Wang S, Wang H, Perdikaris P (2021) On the eigenvector bias of fourier feature networks: From regression to solving multi-scale pdes with physics-informed neural networks. Comput Method Appl Mech Eng 384: 113938. https://doi.org/10.1016/j.cma.2021.113938 doi: 10.1016/j.cma.2021.113938
|
| [122] |
Lu L, Jin P, Pang G, et al. (2021) Learning nonlinear operators via deeponet based on the universal approximation theorem of operators. Nat Mach Intell 3: 218–229. https://doi.org/10.1038/s42256-021-00302-5 doi: 10.1038/s42256-021-00302-5
|
| [123] | Xu W, Lu Y, Wang L (2023) Transfer learning enhanced deeponet for long-time prediction of evolution equations, in: Proceedings of the AAAI Conference on Artificial Intelligence 37: 10629–10636. https://doi.org/10.1609/aaai.v37i9.26262 |
| [124] |
He J, Kushwaha S, Park J, et al. (2024) Sequential deep operator networks (s-deeponet) for predicting full-field solutions under time-dependent loads. Eng Appl Artif Intell 127: 107258. https://doi.org/10.1016/j.engappai.2023.107258 doi: 10.1016/j.engappai.2023.107258
|
| [125] | Li Z, Kovachki N, Azizzadenesheli K, et al. (2020) Fourier neural operator for parametric partial differential equations. arXiv preprint arXiv:2010.08895. |
| [126] | Kovachki N, Lanthaler S, Mishra S (2021) On universal approximation and error bounds for fourier neural operators. J Mach Learn Res 22: 13237–13312. |
| [127] | Guibas J, Mardani M, Li Z, et al. (2021) Adaptive fourier neural operators: Efficient token mixers for transformers. arXiv preprint arXiv:2111.13587. |
| [128] | Li Z, Huang D, Liu B, et al. (2022) Fourier neural operator with learned deformations for pdes on general geometries. arXiv preprint arXiv:2207.05209. |
| [129] |
Lu L, Meng X, Cai S, et al. (2022) A comprehensive and fair comparison of two neural operators (with practical extensions) based on fair data. Comput Method Appl Mech Eng 393: 114778. https://doi.org/10.1016/j.cma.2022.114778 doi: 10.1016/j.cma.2022.114778
|
| [130] |
Di Leoni PC, Lu L, Meneveau C, et al. (2023) Neural operator prediction of linear instability waves in high-speed boundary layers. J Computat Phys 474: 111793. https://doi.org/10.1016/j.jcp.2022.111793 doi: 10.1016/j.jcp.2022.111793
|
| [131] |
Mao Z, Lu L, Marxen O, et al. (2021) Deepm & mnet for hypersonics: Predicting the coupled flow and finite-rate chemistry behind a normal shock using neural-network approximation of operators. J Comput Phys 447: 110698. https://doi.org/10.1016/j.jcp.2021.110698 doi: 10.1016/j.jcp.2021.110698
|
| [132] |
Yin M, Ban E, Rego BV, et al. (2022) Simulating progressive intramural damage leading to aortic dissection using deeponet: an operator–regression neural network. J R Soc Interface 19: 20210670. https://doi.org/10.1098/rsif.2021.0670 doi: 10.1098/rsif.2021.0670
|
| [133] |
Goswami S, Yin M, Yu Y, et al. (2022) A physics-informed variational deeponet for predicting crack path in quasi-brittle materials. Comput Meth Appl Mech Eng 391: 114587. https://doi.org/10.1016/j.cma.2022.114587 doi: 10.1016/j.cma.2022.114587
|
| [134] |
Zhu M, Zhang H, Jiao A, et al. (2023) Reliable extrapolation of deep neural operators informed by physics or sparse observations. Comput Meth Appl Mech Eng 412: 116064. https://doi.org/10.1016/j.cma.2023.116064 doi: 10.1016/j.cma.2023.116064
|
| [135] |
Sekar V, Jiang Q, Shu C, et al. (2019) Fast flow field prediction over airfoils using deep learning approach. Phys Fluids 31.https://doi.org/10.1063/1.5094943 doi: 10.1063/1.5094943
|
| [136] |
Han R, Wang Y, Zhang Y, et al. (2019) A novel spatial-temporal prediction method for unsteady wake flows based on hybrid deep neural network. Phys Fluids 31.https://doi.org/10.1063/1.5127247 doi: 10.1063/1.5127247
|
| [137] |
Bhatnagar S, Afshar Y, Pan S, et al. (2019) Prediction of aerodynamic flow fields using convolutional neural networks. Comput Mech 64: 525–545. https://doi.org/10.1007/s00466-019-01740-0 doi: 10.1007/s00466-019-01740-0
|
| [138] |
Hui X, Bai J, Wang H, et al. (2020) Fast pressure distribution prediction of airfoils using deep learning. Aerosp Sci Technol 105: 105949. https://doi.org/10.1016/j.ast.2020.105949 doi: 10.1016/j.ast.2020.105949
|
| [139] |
Wang J, He C, Li R, et al. (2021) Flow field prediction of supercritical airfoils via variational autoencoder based deep learning framework. Phys Fluids 33.https://doi.org/10.1063/5.0053979 doi: 10.1063/5.0053979
|
| [140] |
Hu JW, Zhang WW (2022) Mesh-conv: Convolution operator with mesh resolution independence for flow field modeling. J Comput Phys 452: 110896. https://doi.org/10.1016/j.jcp.2021.110896 doi: 10.1016/j.jcp.2021.110896
|
| [141] |
Zuo K, Ye Z, Zhang W, et al. (2023) Fast aerodynamics prediction of laminar airfoils based on deep attention network. Phys Fluids 35.https://doi.org/10.1063/5.0140545 doi: 10.1063/5.0140545
|
| [142] | Hirsch C (2007) Numerical computation of internal and external flows: The fundamentals of computational fluid dynamics, Elsevier. |
| [143] |
Chen X, Li T, Wan Q (2022) Mgnet: a novel differential mesh generation method based on unsupervised neural networks. Eng Comput 38: 4409–4421. https://doi.org/10.1007/s00366-022-01632-7 doi: 10.1007/s00366-022-01632-7
|
| [144] | Gao W, Wang A, Metzer G, et al. (2022) Tetgan: A convolutional neural network for tetrahedral mesh generation. arXiv preprint arXiv:2210.05735. |
| [145] | Zhang Z, Wang Y, Jimack PK, et al. (2020) Meshingnet: A new mesh generation method based on deep learning, in: International Conference on Computational Science, Springer, 186–198. https://doi.org/10.1007/978-3-030-50420-5_14 |
| [146] |
Chen X, Liu J, PangY, et al. (2020) Developing a new mesh quality evaluation method based on convolutional neural network. Eng Appl Comput Fluid Mech 14: 391–400. https://doi.org/10.1080/19942060.2020.1720820 doi: 10.1080/19942060.2020.1720820
|
| [147] | Lu Y, Zhong A, Li Q, et al. (2018) Beyond finite layer neural networks: Bridging deep architectures and numerical differential equations, in: International Conference on Machine Learning, PMLR, 3276–3285. |
| [148] | Guo L, Li M, Xu S, et al. (2019) Study on a recurrent convolutional neural network based fdtd method, in: 2019 International Applied Computational Electromagnetics Society Symposium-China (ACES), 1: IEEE, 1–2. https://doi.org/10.23919/ACES48530.2019.9060707 |
| [149] | Guo X, Li W, orio FI (2016) Convolutional neural networks for steady flow approximation, in: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 481–490. https://doi.org/10.1145/2939672.2939738 |
| [150] |
de Lara FM, Ferrer E (2022) Accelerating high order discontinuous galerkin solvers using neural networks: 1d burgers' equation. Comput Fluids 235: 105274. https://doi.org/10.1016/j.compfluid.2021.105274 doi: 10.1016/j.compfluid.2021.105274
|
| [151] |
de Lara FM, Ferrer E (2023) Accelerating high order discontinuous galerkin solvers using neural networks: 3d compressible navier-stokes equations. J Comput Phys 112253.https://doi.org/10.1016/j.jcp.2023.112253 doi: 10.1016/j.jcp.2023.112253
|
| [152] | Belbute-Peres FDA, Economon T, Kolter Z (2020) Combining differentiable pde solvers and graph neural networks for fluid flow prediction, in: International Conference on Machine Learning, PMLR, 2402–2411. |
| [153] | Liu W, Yagoubi M, Schoenauer M (2021) Multi-resolution graph neural networks for pde approximation, in: Artificial Neural Networks and Machine Learning–ICANN 2021: 30th International Conference on Artificial Neural Networks, Bratislava, Slovakia, 14–17, Proceedings, Part Ⅲ 30, Springer, 151–163. https://doi.org/10.1007/978-3-030-86365-4_13 |
| [154] |
Chen J, Hachem E, Viquerat J (2021) Graph neural networks for laminar flow prediction around random two-dimensional shapes. Phys Fluids 33.https://doi.org/10.1063/5.0064108 doi: 10.1063/5.0064108
|
| [155] |
Wang ZJ, Fidkowski K, Abgrall R, et al. (2013) High-order cfd methods: current status and perspective. Int J Numer Meth Fluids 72: 811–845. https://doi.org/10.1002/fld.3767 doi: 10.1002/fld.3767
|
| [156] |
Deng X, Mao M, Tu G, et al. (2012) High-order and high accurate cfd methods and their applications for complex grid problems. Commun Computat Phys 11: 1081–1102. https://doi.org/10.4208/cicp.100510.150511s doi: 10.4208/cicp.100510.150511s
|
| [157] |
Xiao T (2021) A flux reconstruction kinetic scheme for the boltzmann equation. J Comput Phys 447: 110689. https://doi.org/10.1016/j.jcp.2021.110689 doi: 10.1016/j.jcp.2021.110689
|
| [158] |
Beck AD, Zeifang J, Schwarz A (2020) A neural network based shock detection and localization approach for discontinuous galerkin methods. J Comput Phys 423: 109824. https://doi.org/10.1016/j.jcp.2020.109824 doi: 10.1016/j.jcp.2020.109824
|
| [159] |
Sun Z (2020) Convolution neural network shock detector for numerical solution of conservation laws. Commun Comput Phys 28.https://doi.org/10.4208/cicp.OA-2020-0199 doi: 10.4208/cicp.OA-2020-0199
|
| [160] | Morgan NR, Tokareva S, Liu X (2020) A machine learning approach for detecting shocks with high-order hydrodynamic methods. AIAA Scitech 2020 Forum. https://doi.org/10.2514/6.2020-2024 |
| [161] |
Yin X, Chen X, Chang H (2019) Experimental study of atmospheric turbulence detection using an orbital angular momentum beam via a convolutional neural network. IEEE Access 7: 184235–184241. https://doi.org/10.1109/ACCESS.2019.2960544 doi: 10.1109/ACCESS.2019.2960544
|
| [162] |
Li J, Zhang M, Wang D, et al. (2018) Joint atmospheric turbulence detection and adaptive demodulation technique using the cnn for the oam-fso communication. Opt Express 26: 10494–10508. https://doi.org/10.1364/OE.26.010494 doi: 10.1364/OE.26.010494
|
| [163] |
Levermore CD (1996) Moment closure hierarchies for kinetic theories. J Stat Phys 83: 1021–1065. https://doi.org/10.1007/BF02179552 doi: 10.1007/BF02179552
|
| [164] |
Sadr M, Torrilhon M, Gorji MH (2020) Gaussian process regression for maximum entropy distribution. J Comput Phys 418: 109644. https://doi.org/10.1016/j.jcp.2020.109644 doi: 10.1016/j.jcp.2020.109644
|
| [165] | Schotthfer S, Xiao T, Frank M, et al. (2021) A structure-preserving surrogate model for the closure of the moment system of the boltzmann equation using convex deep neural networks, in: AIAA Aviation 2021 Forum 2895.https://doi.org/10.2514/6.2021-2895 |
| [166] | Schotthfer S, Xiao T, Frank M, et al. (2022) Structure preserving neural networks: A case study in the entropy closure of the boltzmann equation, in: Proceedings of the International Conference on Machine Learning, PMLR, Baltimore, USA, 17–23. |
| [167] | Kusch J, Schotthfer S, Stammer P, et al. (2022) Kit-rt: An extendable framework for radiative transfer and therapy. arXiv preprint arXiv:2205.08417. https://doi.org/10.1145/3630001 |
| [168] |
Mohamed L, Calderhead B, Filippone M, et al. (2012) Population mcmc methods for history matching and uncertainty quantification. Comput Geosci 16: 423–436. https://doi.org/10.1007/s10596-011-9232-8 doi: 10.1007/s10596-011-9232-8
|
| [169] | Rafiee J, Reynolds AC (2018) A two-level mcmc based on the distributed gauss-newton method for uncertainty quantification, in: ECMOR XVI-16th European Conference on the Mathematics of Oil Recovery. European Association of Geoscientists & Engineers, 1–33. https://doi.org/10.3997/2214-4609.201802140 |
| [170] |
Mohamed L, Christie M, Demyanov V (2010) Comparison of stochastic sampling algorithms for uncertainty quantification. SPE J 15: 31–38. https://doi.org/10.2118/119139-MS doi: 10.2118/119139-MS
|
| [171] |
Zhang J (2021) Modern monte carlo methods for efficient uncertainty quantification and propagation: A survey, Wiley Interdisciplinary Reviews. Comput Stat 13: e1539. https://doi.org/10.1002/wics.1539 doi: 10.1002/wics.1539
|
| [172] | Izmailov P, Vikram S, Hoffman MD, et al. (2021) What are bayesian neural network posteriors really like? in: International conference on machine learning, PMLR, 4629–4640. |
| [173] |
Jospin LV, Laga H, Boussaid F (2022) Hands-on bayesian neural networks—a tutorial for deep learning users. IEEE Comput Intell Mag 17: 29–48. https://doi.org/10.1109/MCI.2022.3155327 doi: 10.1109/MCI.2022.3155327
|
| [174] | Goan E, Fookes C (2020) Bayesian neural networks: An introduction and survey, Case Studies in Applied Bayesian Data Science, in: CIRM Jean-Morlet Chair, Fall 2018, 45–87. https://doi.org/10.1007/978-3-030-42553-1_3 |
| [175] | Fortuin V, Garriga-Alonso A, Ober SW, et al. (2021) Bayesian neural network priors revisited. arXiv preprint arXiv:2102.06571. |
| [176] | Springenberg JT, Klein A, Falkner S, et al. (2016) Bayesian optimization with robust bayesian neural networks. Adv Neur Inf Process Sys 29. |
| [177] |
Chan S, Elsheikh AH (2018) A machine learning approach for efficient uncertainty quantification using multiscale methods. J Comput Phys 354: 493–511. https://doi.org/10.1016/j.jcp.2017.10.034 doi: 10.1016/j.jcp.2017.10.034
|
| [178] | Rahaman R (2021) Uncertainty quantification and deep ensembles. Adv Neur Inf Process Syst 34: 20063–20075. |
| [179] | Lakshminarayanan B, Pritzel A, Blundell C (2017) Simple and scalable predictive uncertainty estimation using deep ensembles. Adv Neur Inf Process Syst 30. |
| [180] | Egele R, Maulik R, Raghavan K, et al. (2022) Autodeuq: Automated deep ensemble with uncertainty quantification, in: 2022 26th International Conference on Pattern Recognition (ICPR), IEEE, 1908–1914. https://doi.org/10.1109/ICPR56361.2022.9956231 |
| [181] |
Moya C, Zhang S, Lin G, et al. (2023) Deeponet-grid-uq: A trustworthy deep operator framework for predicting the power grid's post-fault trajectories. Neurocomputing 535: 166–182. https://doi.org/10.1016/j.neucom.2023.03.015 doi: 10.1016/j.neucom.2023.03.015
|
| [182] | Zhang J, Zhang S, Lin G (2022) Multiauto-deeponet: A multi-resolution autoencoder deeponet for nonlinear dimension reduction, uncertainty quantification and operator learning of forward and inverse stochastic problems. arXiv preprint arXiv:2204.03193. |
| [183] |
Silva WA, Bartels RE (2004) Development of reduced-order models for aeroelastic analysis and flutter prediction using the cfl3dv6. 0 code. J Fluids Struct 19: 729–745. https://doi.org/10.1016/j.jfluidstructs.2004.03.004 doi: 10.1016/j.jfluidstructs.2004.03.004
|
| [184] |
Amsallem D, Farhat C (2008) Interpolation method for adapting reduced-order models and application to aeroelasticity. AIAA J 46: 1803–1813. https://doi.org/10.2514/1.35374 doi: 10.2514/1.35374
|
| [185] |
Winter M, Breitsamter C (2016) Neurofuzzy-model-based unsteady aerodynamic computations across varying freestream conditions. Aiaa J 54: 2705–2720. https://doi.org/10.2514/1.J054892 doi: 10.2514/1.J054892
|
| [186] |
Zhang W, Li X, Ye Z (2015) Mechanism of frequency lock-in in vortex-induced vibrations at low reynolds numbers. J Fluid Mech 783: 72–102. https://doi.org/10.1017/jfm.2015.548 doi: 10.1017/jfm.2015.548
|
| [187] |
Yao W, Jaiman R (2017) Model reduction and mechanism for the vortex-induced vibrations of bluff bodies. J Fluid Mech 827 : 357–393. https://doi.org/10.1017/jfm.2017.525 doi: 10.1017/jfm.2017.525
|
| [188] |
Gao C, Zhang W, Li X, (2017) Mechanism of frequency lock-in in transonic buffeting flow. J Fluid Mech 818: 528–561. https://doi.org/10.1017/jfm.2017.120 doi: 10.1017/jfm.2017.120
|
| [189] |
Balajewicz M, Dowell E (2012) Reduced-order modeling of flutter and limit-cycle oscillations using the sparse volterra series. J Aircraft 49: 1803–1812. https://doi.org/10.2514/1.C031637 doi: 10.2514/1.C031637
|
| [190] |
Zhang W, Wang B, Ye Z, wt al. (2012) Efficient method for limit cycle flutter analysis based on nonlinear aerodynamic reduced-order models. AIAA J 50: 1019–1028. https://doi.org/10.2514/1.J050581 doi: 10.2514/1.J050581
|
| [191] |
Mannarino A, Mantegazza P (2014) Nonlinear aeroelastic reduced order modeling by recurrent neural networks. J Fluids Struct 48: 103–121. https://doi.org/10.1016/j.jfluidstructs.2014.02.016 doi: 10.1016/j.jfluidstructs.2014.02.016
|
| [192] | Chen G, Zuo Y, Sun J, et al. (2012) Support-vector-machine-based reduced-order model for limit cycle oscillation prediction of nonlinear aeroelastic system. Math Probl Eng 2012. |
| [193] |
Liu Z, Han R, Zhang M, et al. (2022) An enhanced hybrid deep neural network reduced-order model for transonic buffet flow prediction. Aerosp Sci Technol 126: 107636. https://doi.org/10.1016/j.ast.2022.107636 doi: 10.1016/j.ast.2022.107636
|
| [194] |
Huang R, Li H, Hu H, et al. (2015) Open/closed-loop aeroservoelastic predictions via nonlinear, reduced-order aerodynamic models. AIAA J 53: 1812–1824. https://doi.org/10.2514/1.J053424 doi: 10.2514/1.J053424
|
| [195] |
Mannarino A, Dowell EH (2015) Reduced-order models for computational-fluid-dynamics-based nonlinear aeroelastic problems. Aiaa J 53: 2671–2685. https://doi.org/10.2514/1.J053775 doi: 10.2514/1.J053775
|
| [196] |
Huang R, Liu H, Yang Z, et al. (2018) Nonlinear reduced-order models for transonic aeroelastic and aeroservoelastic problems. AIAA J 56: 3718–3731. https://doi.org/10.2514/1.J056760 doi: 10.2514/1.J056760
|
| [197] |
Yang Z, Huang R, Liu H, et al. (2020) An improved nonlinear reduced-order modeling for transonic aeroelastic systems. J Fluids Struct 94: 102926. https://doi.org/10.1016/j.jfluidstructs.2020.102926 doi: 10.1016/j.jfluidstructs.2020.102926
|
| [198] | Jameson A (2003) Aerodynamic shape optimization using the adjoint method, Lectures at the Von Karman Institute, Brussels. |
| [199] |
Martins JR, Lambe AB (2013) Multidisciplinary design optimization: a survey of architectures. AIAA J 51: 2049–2075. https://doi.org/10.2514/1.J051895 doi: 10.2514/1.J051895
|
| [200] |
Jameson A (1988) Aerodynamic design via control theory. J Sci Comput 3: 233–260. https://doi.org/10.1007/BF01061285 doi: 10.1007/BF01061285
|
| [201] |
Queipo NV, Haftka RT, Shyy W, et al. (2005) Surrogate-based analysis and optimization. Prog Aerosp Sci 41: 1–28. https://doi.org/10.1016/j.paerosci.2005.02.001 doi: 10.1016/j.paerosci.2005.02.001
|
| [202] |
Han ZH, Zhang KS (2012) Surrogate-based optimization. Real-world applications of genetic algorithms. InTech 343: 343–362. https://doi.org/10.5772/36125 doi: 10.5772/36125
|
| [203] |
Yondo R, Andrés E, Valero E (2018) A review on design of experiments and surrogate models in aircraft real-time and many-query aerodynamic analyses. Prog Aerosp Sci 96: 23–61. https://doi.org/10.1016/j.paerosci.2017.11.003 doi: 10.1016/j.paerosci.2017.11.003
|
| [204] |
Li J, Du X, Martins JR (2022) Machine learning in aerodynamic shape optimization. Prog Aerosp Sci 134: 100849. https://doi.org/10.1016/j.paerosci.2022.100849 doi: 10.1016/j.paerosci.2022.100849
|
| [205] |
Xu M, Song S, Sun X, et al. (2021) Machine learning for adjoint vector in aerodynamic shape optimization. Acta Mech Sinica 37: 1416–1432. https://doi.org/10.1007/s10409-021-01119-6 doi: 10.1007/s10409-021-01119-6
|
| [206] | Xu M, Song S, Sun X, et al. (2021) A convolutional strategy on unstructured mesh for the adjoint vector modeling. Phys Fluids 33. |
| [207] |
Wu X, Zhang W, Peng X, et al. (2019) Benchmark aerodynamic shape optimization with the pod-based cst airfoil parametric method. Aerosp Sci Technol 84: 632–640. https://doi.org/10.1016/j.ast.2018.08.005 doi: 10.1016/j.ast.2018.08.005
|
| [208] |
Sun G, Wang S (2019) A review of the artificial neural network surrogate modeling in aerodynamic design. P I Mech Eng G J Aer 233: 5863–5872. https://doi.org/10.1177/0954410019864485 doi: 10.1177/0954410019864485
|
| [209] | Chen LW, Cakal BA, Hu X, et al. (2021) Numerical investigation of minimum drag profiles in laminar flow using deep learning surrogates. J Fluid Mech 919: A34. |
| [210] |
Yan X, Zhu J, Kuang M, et al. (2019) Aerodynamic shape optimization using a novel optimizer based on machine learning techniques. Aerosp Sci Technol 86: 826–835. https://doi.org/10.1016/j.ast.2019.02.003 doi: 10.1016/j.ast.2019.02.003
|
| [211] |
Li R, Zhang Y, Chen H (2021) Learning the aerodynamic design of supercritical airfoils through deep reinforcement learning. AIAA J 59: 3988–4001. https://doi.org/10.2514/1.J060189 doi: 10.2514/1.J060189
|
| [212] | Gad-el Hak M (1989) Flow control. https://doi.org/10.1115/1.3152376 |
| [213] |
Bewley TR (2001) Flow control: new challenges for a new renaissance. Prog Aerosp Sci 37: 21–58. https://doi.org/10.1001/archneur.58.1.21 doi: 10.1001/archneur.58.1.21
|
| [214] | Brunton SL, Noack BR (2015) Closed-loop turbulence control: Progress and challenges. Appl Mech Rev 67: 050801. |
| [215] |
Fouatih OM, Medale M, Imine O, et al. (2016) Design optimization of the aerodynamic passive flow control on naca 4415 airfoil using vortex generators. Eur J Mech-B/Fluids 56: 82–96. https://doi.org/10.1016/j.euromechflu.2015.11.006 doi: 10.1016/j.euromechflu.2015.11.006
|
| [216] | Kral LD (2000) Active flow control technology. ASME Fluids Eng Tech Brief 1–28. |
| [217] |
Collis SS, Joslin RD, Seifert A, et al. (2004) Issues in active flow control: theory, control, simulation, and experiment. Prog Aerosp Sci 40: 237–289. https://doi.org/10.1016/j.paerosci.2004.06.001 doi: 10.1016/j.paerosci.2004.06.001
|
| [218] |
Cattafesta Ⅲ LN, Sheplak M (2011) Actuators for active flow control. Annu Rev Fluid Mech 43: 247–272. https://doi.org/10.1146/annurev-fluid-122109-160634 doi: 10.1146/annurev-fluid-122109-160634
|
| [219] |
Lee C, Hong G, Ha Q, et al. (2003) A piezoelectrically actuated micro synthetic jet for active flow control. Sensors Actuat A Phys 108: 168–174. https://doi.org/10.1016/S0924-4247(03)00267-X doi: 10.1016/S0924-4247(03)00267-X
|
| [220] |
Gao C, Zhang W, Ye Z (2016) Numerical study on closed-loop control of transonic buffet suppression by trailing edge flap. Comput Fluids 132 32–45. https://doi.org/10.1016/j.compfluid.2016.03.031 doi: 10.1016/j.compfluid.2016.03.031
|
| [221] |
Faisal KM, Salam M, Ali MT, et al. (2017) Flow control using moving surface at the leading edge of aerofoil. J Mech Eng 47: 45–50. https://doi.org/10.3329/jme.v47i1.35420 doi: 10.3329/jme.v47i1.35420
|
| [222] |
Rowley CW, Dawson ST (2017) Model reduction for flow analysis and control. Ann Rev Fluid Mech 49: 387–417. https://doi.org/10.1146/annurev-fluid-010816-060042 doi: 10.1146/annurev-fluid-010816-060042
|
| [223] |
Ahuja S, Rowley CW (2010) Feedback control of unstable steady states of flow past a flat plate using reduced-order estimators. J Fluid Mech 645: 447–478. https://doi.org/10.1017/S0022112009992655 doi: 10.1017/S0022112009992655
|
| [224] | Duriez T, Brunton SL, Noack BR (2017) Machine learning control-taming nonlinear dynamics and turbulence, Springer. |
| [225] |
Gao C, Zhang W, Kou J, et al. (2017) Active control of transonic buffet flow. J Fluid Mech 824: 312–351. https://doi.org/10.1017/jfm.2017.344 doi: 10.1017/jfm.2017.344
|
| [226] | Ren K, Chen Y, GaoC, et al. (2020) Adaptive control of transonic buffet flows over an airfoil. Phys Fluids 32. |
| [227] |
Nair NJ, Goza A (2020) Leveraging reduced-order models for state estimation using deep learning. J Fluid Mech 897: R1. https://doi.org/10.1017/jfm.2020.501 doi: 10.1017/jfm.2020.501
|
| [228] |
Rabault J, Kuchta M, Jensen A, et al. (2019) Artificial neural networks trained through deep reinforcement learning discover control strategies for active flow control. J Fluid Mech 865: 281–302. https://doi.org/10.1017/jfm.2019.62 doi: 10.1017/jfm.2019.62
|
| [229] |
Paris R, Beneddine S, Dandois J (2021) Robust flow control and optimal sensor placement using deep reinforcement learning. J Fluid Mech 913: A25. https://doi.org/10.1017/jfm.2020.1170 doi: 10.1017/jfm.2020.1170
|
| [230] |
Rabault J, Ren F, Zhang W, et al. (2020) Deep reinforcement learning in fluid mechanics: A promising method for both active flow control and shape optimization. J Hydrodyn 32: 234–246. https://doi.org/10.1007/s42241-020-0028-y doi: 10.1007/s42241-020-0028-y
|
| [231] |
Ren F, Hu Hb, Tang H (2020) Active flow control using machine learning: A brief review. J Hydrodyn 32: 247–253. https://doi.org/10.1007/s42241-020-0026-0 doi: 10.1007/s42241-020-0026-0
|
| [232] |
Li Y, Chang J, Kong C, et al. (2022) Recent progress of machine learning in flow modeling and active flow control. Chinese J Aeronaut 35: 14–44. https://doi.org/10.1016/j.cja.2021.07.027 doi: 10.1016/j.cja.2021.07.027
|
| [233] |
Brodnik NR, Carton S, Muir C, et al. (2023) Perspective: Large language models in applied mechanics. J Appl Mech 90: 101008. https://doi.org/10.1115/1.4062773 doi: 10.1115/1.4062773
|

Figures(2)
Jiaqing Kou, Tianbai Xiao. Artificial intelligence and machine learning in aerodynamics[J]. Metascience in Aerospace, 2024, 1(2): 190-218. doi: 10.3934/mina.2024009







 DownLoad:
DownLoad: